




 文章深入探讨了Redis中SCAN迭代器的实现原理,包括dictScan函数的运作机制,以及在rehashing过程中如何确保数据完整性和一致性。通过对源码的详细分析,揭示了SCAN迭代器在处理字典扩容时的精妙策略。
文章深入探讨了Redis中SCAN迭代器的实现原理,包括dictScan函数的运作机制,以及在rehashing过程中如何确保数据完整性和一致性。通过对源码的详细分析,揭示了SCAN迭代器在处理字典扩容时的精妙策略。
Scan迭代器dictScan函数
在学习scan迭代器的时候,被其迭代算法的思想惊艳到了,忍不住大赞作者。(迭代所使用的算法是由 Pieter Noordhuis 设计的)
想比较深入的了解scan迭代器的话,大家可以参考下面这篇博文:
http://chenzhenianqing.com/articles/1101.html
建议大家先看一下这篇博文,因为本文所写的内容是在验证这篇博文的基础上,提出一些源码方面的问题。
在进行后面的分析之前,我们先来看一下dictScan函数里面写了啥(Redis源码的版本是3.0的(《Redis设计与实现》作者黄健宏老师注释版))
一、dictScan函数
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
// 跳过空字典
if (dictSize(d) == 0) return 0;
// 迭代只有一个哈希表的字典
//没有在做rehash,所以只有第一个表有数据的
if (!dictIsRehashing(d)) {
// 指向哈希表
t0 = &(d->ht[0]);
//记录 mask
//槽位大小-1,因为大小总是2^N,所以sizemask的二进制总是后面都为1,
//比如16个slot的字典,sizemask为00001111
m0 = t0->sizemask;
/* Emit entries at cursor */
// 指向哈希桶
de = t0->table[v & m0]; //找到当前这个槽位,然后处理数据
// 遍历桶中的所有节点
while (de) {
fn(privdata, de); //将这个slot的链表数据全部入队,准备返回给客户端
de = de->next;
}
// 迭代有两个哈希表的字典
} else {
// 指向两个哈希表
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
// 确保 t0 比 t1 要小
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
// 记录掩码
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
// 指向桶,并迭代桶中的所有节点 ,处理小一点的表。
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
// Iterate over indices in larger table // 迭代大表中的桶
// that are the expansion of the index pointed to // 这些桶被索引的 expansion 所指向
// by the cursor in the smaller table
//扫描大点的表里面的槽位,注意这里是个循环,会将小表没有覆盖的slot全部扫描一次的
do {
/* Emit entries at cursor */
// 指向桶,并迭代桶中的所有节点
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
//下面的意思是,还需要扩展小点的表,将其后缀固定,然后看高位可以怎么扩充。
//其实就是想扫描一下小表里面的元素可能会扩充到哪些地方,需要将那些地方处理一遍。
//后面的(v & m0)是保留v在小表里面的后缀。
//((v | m0) + 1) & ~m0) 是想给v的扩展部分的二进制位不断的加1,来造成高位不断增加的效果。
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
//终止条件是 v的高位区别位没有1了,其实就是说到头了。
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
//按位取反,其实相当于v |= m0-1 , ~m0也就是11110000,
//这里相当于将v的不相干的高位全部置为1,待会再进行翻转二进制位,然后加1,然后再转回来
v |= ~m0;
/* Increment the reverse cursor */
//下面将v的每一位倒过来再加1,再倒回去,这是什么意思呢,
//其实就是要将有效二进制位里面的高位第一个0位设置置为1,因为现在是0嘛
v = rev(v);
v++;
v = rev(v);
return v;
}
1.1 dictScan() 函数的简单理解
dictScan() 函数用于迭代给定字典中的元素。
迭代按以下方式执行:
- 一开始,你使用 0 作为游标来调用函数。
- 函数执行一步迭代操作,并返回一个下次迭代时使用的新游标。
- 当函数返回的游标为 0 时,迭代完成。
函数保证,在迭代从开始到结束期间,一直存在于字典的元素肯定会被迭代到,但一个元素可能会被返回多次。
每当一个元素被返回时,回调函数 fn 就会被执行,
fn 函数的第一个参数是 privdata ,而第二个参数则是字典节点 de 。
工作原理
迭代所使用的算法是由 Pieter Noordhuis 设计的,算法的主要思路是在二进制高位上对游标进行加法计算。也即是说,不是按正常的办法来对游标进行加法计算,而是首先将游标的二进制位翻转(reverse)过来,然后对翻转后的值进行加法计算,最后再次对加法计算之后的结果进行翻转。
这一策略是必要的,因为在一次完整的迭代过程中,哈希表的大小有可能在两次迭代之间发生改变。
哈希表的大小总是 2 的某个次方,并且哈希表使用链表来解决冲突,因此一个给定元素在一个给定表的位置总可以通过 Hash(key) & SIZE-1公式来计算得出,
其中 SIZE-1 是哈希表的最大索引值,这个最大索引值就是哈希表的 mask (掩码)。
举个例子,如果当前哈希表的大小为 16 ,那么它的掩码就是二进制值 1111 ,这个哈希表的所有位置都可以使用哈希值的最后四个二进制位来记录。
如果哈希表的大小改变了怎么办?
当对哈希表进行扩展时,元素可能会从一个槽移动到另一个槽,举个例子,假设我们刚好迭代至 4 位游标 1100 ,而哈希表的 mask 为 1111 (哈希表的大小为 16 )。
如果这时哈希表将大小改为 64 ,那么哈希表的 mask 将变为 111111 …
在 rehash 的时候可是会出现两个哈希表的!
1.2 scan迭代器的缺点
限制
这个迭代器是完全无状态的,这是一个巨大的优势,因为迭代可以在不使用任何额外内存的情况下进行。
这个设计的缺陷在于:
- 函数可能会返回重复的元素,不过这个问题可以很容易在应用层解决。
- 为了不错过任何元素,迭代器需要返回给定桶上的所有键,以及因为扩展哈希表而产生出来的新表,所以迭代器必须在一次迭代中返回多个元素。
- 对游标进行翻转(reverse)的原因初看上去比较难以理解,不过阅读这份注释应该会有所帮助。
二、对函数代码的验证
2.1 关于 依次遍历 时 槽位变化 的验证
通过阅读上面代码和注释,我们大概对scan函数的执行流程有了一个了解,现在有必要对函数中的两个重难点进行仔细地分析。
第一个就是在 “return v” 之前的函数段:
v |= ~m0;
v = rev(v);
v++;
v = rev(v);
这段代码的作用是 控制scan从0号开始遍历字典,然后经过计算跳到下一个正确的槽位,逐步完成scan遍历。v表示此时正在遍历的槽位(也叫索引值,桶位)。
假设开始时v=0,即0000 0000,字典大小为size=8,mask=size-1=7,即m0= 0000 0111。
依次执行下面的运算,看看经过一遍运算之后 v 的值是如何变化的:
v |= ~m0; “|=”表示做“或”操作,“~”表示“按位取反”,所以就是先对m0按位取反,之后再用v与之做或操作,0000 0000 | 1111 10000 = 1111 1000,v = 1111 1000;
v = rev(v); rev( ) 表示对其二进制的高低位翻转,此时 v = 0001 1111;
v++; 表示二进制位加1 ,此时 v = 0010 0000;
v = rev(v); 如上上步,翻转,此时 v = 0000 0100;v = 4;
经过上面的代码转换,scan遍历的游标槽位从0变为4了;
再经过一遍上面的代码,看看如何将游标从 4 “升”到 2 :
v |= ~m0; v = 0000 0100 | 1111 1000 = 1111 1100
v = rev(v); v = 0011 1111
v++; v = 0100 0000
v = rev(v); v = 0000 0010 = 2
上面的代码演示了游标从 0 变成了 4,又从 4 变成了 2,再经过上面的代码,游标就会变成 6 -> 1 -> 5 -> 3 ->7 -> 0;
符合从最高位依次加1的规律,如下所示:
0 0 0 0
1 0 0 4
0 1 0 2
1 1 0 6
0 0 1 1
1 0 1 5
0 1 1 3
1 1 1 7
0 0 0 0
2.2 关于 rehashing 中 槽位迁移 的变化的验证
前面讨论的情况是没有遇到在rehashing的过程中,都是扩容或者缩小的时候都没有请求到来。这里来简单讨论一下发生rehashing的过程中,接受到的SCAN该怎么处理;
redis处理这个情形的方法很简单:干脆就一次查找字典里面的2个表,一个临时扩容,一个就是主要的dict。 免得中间的状态基本无法维护;所以这种情况下,redis会先扫描数据项小一点的表,然后就扫描大的表,将其2份数据和在一起返回给客户端。这样简单粗暴,但绝对靠谱。这种情况下,是不会出现丢数据,和重复的情况的。
但从dictScan 函数里面可以看到,为了处理rehashing,里面对于大点的表的处理有一个比较关键的地方,如下代码:
//扫描大点的表里面的槽位,注意这里是个循环,会将小表没有覆盖的slot全部扫描一次的
do {
// 指向桶,并迭代桶中的所有节点
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
//((v | m0) + 1) & ~m0) 是想给v的扩展部分的二进制位不断的加1,来造成高位不断增加的效果。
v = (((v | m0) + 1) & ~m0) | (v & m0);
//终止条件是 v的高位区别位没有1了,其实就是说到头了。
} while (v & (m0 ^ m1));
上面这段代码的作用就是 在字典进行扩容rehashing时,为了将所有可能从当前的小表的游标v所指的slot扩展迁移过去的slot,都扫描一遍,防止遗漏。
比如当前的游标v等于0, 小表大小为8,大的表为64,那么需要扫描大表的这几个位置:0, 8, 16, 32。 原因是因为可能t0(小表)里面的一部分元素已经发生了迁移,仅仅扫描t0不够,还要扫描哪些可能的迁移目的地(来源,一样的)。
如下所示,t0到t1大小从8变化到64之后,原来在0号slot的元素可能会迁移到了0, 8, 16, 24,32,48,56这几个t1的slot中。所以我们需要扫描这几个槽位,一次将其返回给客户端,免得夜长梦多,下次找不到地方了。
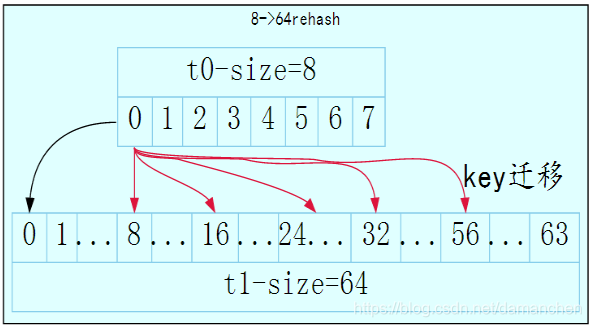
考虑字典从8扩到64的时候,所以mask分别为 m0 = 0000 0111,m1 = 0011 1111,v 刚开始为 0000 0000。
在此do…while循环中用来控制槽位 v 的重要代码如下:
v = (((v | m0) + 1) & ~m0) | (v & m0);
开始时, v = 0 = 0000 0000, 做一遍运算变化如下:
v | m0 + 1 = 0000 0000 | 0000 0111 + 1 = 0000 1000
0000 1000 & ~m0 = 0000 1000 & 1111 1000 = 0000 1000
0000 1000 | (0000 0000&0000 0111) = 0000 1000 | 0000 0000 = 0000 1000 = 8
一遍循环之后 v = 8;
再做一遍循环,之后 v = 16,之后 16 -> 24 -> 32 ->…->56,
当 v = 56 = 0011 1000时,
(v & (m0 ^ m1))= (0011 1000 & ( 0000 0111 ^ 0011 1111) = 0011 1000 & 0011 1000 = 0011 1000 != 0,仍然满足循环条件。
当再循环一次,v = 64 = 0100 0000时,(v & (m0 ^ m1))= 0100 0000 & 0011 1000 = 0,不满足循环条件,不执行循环,所以整个循环会在 v = 64之前停下来,正如我们所期望的循环执行。
这下清楚了,rehashing的时候会返回t0的槽位,以及t1里面所有可能发生迁移到的槽位。
思考
在上面验证当发生 rehashing,对字典进行scan时槽位的变化情况时,我们考虑到的字典的扩容情况是字典size从8直接扩容到64位。但是大家有没有想过,字典扩容的时候会直接从size=8,直接扩容到size=64的情况吗???
但是我们印象中字典的扩容不都是翻倍的扩容吗,也就是从4到8,然后再从8到16,,,这样的扩容呀,如果是这样翻倍扩容的话,Redie作者写这个do…while循环还有什么用处吗?还用考虑这样的槽位迁移的情况吗?代码多余了??!!
作为开发出Redis这么优秀的服务的作者,怎么可能会犯这么低级的错误呢!?
我会在下一篇博文中分享一下Redis字典扩容的一些问题,看看Redis字典扩容时会不会直接从size=8直接扩容到size=64,以及对这段代码的再思考。。。

















 5002
5002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









