









什么是字节序?
字节序,简单来说,指的是 超过一个字节的数据类型在内存中存储的顺序
有几种字节序?
大端字节序(Big Endian)
高位字节数据存放在内存低地址处,低位字节数据存放在内存高地址处。
小端字节序(Little Endian)
高位字节数据存放在内存高地址处,低位数据存放在内存低地址处。
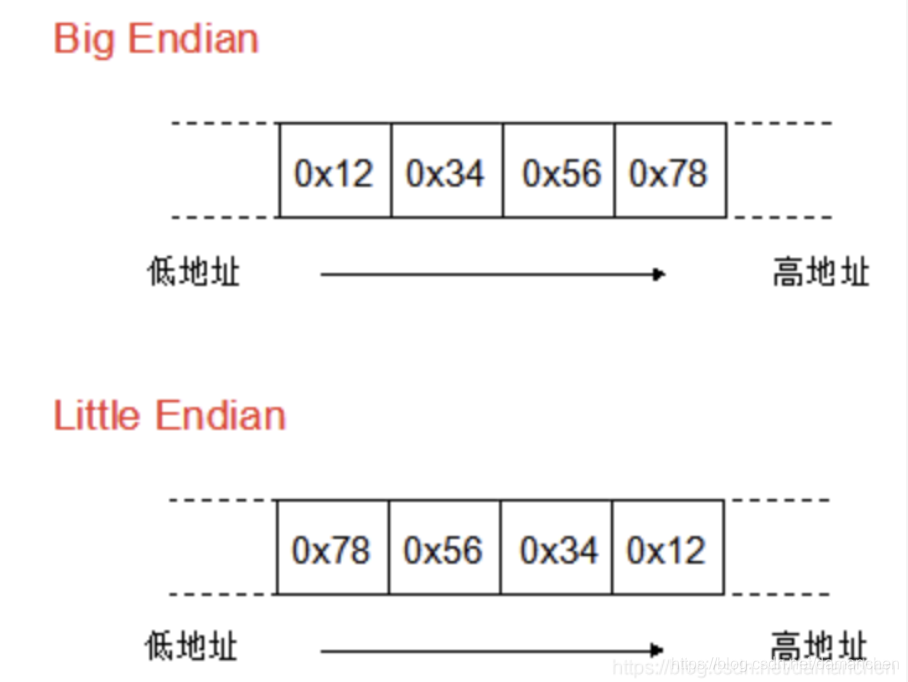
如上图所示,int32类型的数值 12345678用一个字节表示不了,需要用到4个字节,也就有了字节序的问题。
数值 12345678(一千两百三十四万五千六百七十八),这里的最高位数据就是1,最低位数据就是8。
看大端序的存储方式,高位在前面的低地址,低位在后面的高地址,这也是人类读写数值的方式;而小端序正好相反。
那么问题来了,为什么还需要小端序的方式,只使用大端序的方式不是更方便吗?什么是内存高地址/低地址,为什么低地址在前,高地址在后呢?
为什么需要小端字节序?
我们知道计算机正常的内存增长方式是从低到高(当然栈不是),取数据方式是从基址根据偏移找到他们的位置。
从大/小端的存储方式可以看出,大端存储因为第一个字节就是高位,从而很容易知道它是正数还是负数,对于一些数值判断会很迅速。
而小端存储 第一个字节是它的低位,符号位在最后一个字节,这样在做数值四则运算时,从低位每次取出相应字节运算,最后直到高位,并且最终把符号位刷新,这样的运算方式会更高效。
所以大端和小端有其各自的优势。
具体是使用大端序还是小端序跟处理器体系有关:
处理器体系
- x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器为小端序;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器为大端序;
- ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
字节序的处理
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
网络字节序
前面的大端和小端都是在说计算机自己,也被称作主机字节序HBO(Host Byte Order)。其实,只要自己能够自圆其说是没啥问题的。问题是,网络的出现使得计算机可以通信了。通信,就意味着相处,相处必须得有共同语言啊,得说普通话,要不然就容易会错意,下了一个小时的小电影发现打不开,理解错误了!
但是每种计算机体系都有自己的主机字节序啊,还都不依不饶,坚持做自己,怎么办?
TCP/IP协议隆重出场,RFC1700规定使用“大端”字节序为网络字节序NBO(Network Byte Order)。
其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。
为了程序的兼容,你会看到,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。
这么常用的操作,BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。当然,有了上面的理论基础,也可以编写自己的转换函数。
网络字节顺序(NBO)
NBO(Network Byte Order):按照从高到低的顺序存储,在网络上使用统一的网络字节顺序,可以避免兼容性问题。TCP/IP中规定好的一种数据表示格式,与具体的 CPU 类型、操作系统等无关。从而保证数据在不同主机之间传输时能够被正确解释。
主机字节顺序(HBO)
HBO(Host Byte Order):不同机器 HBO 不相同,与 CPU 有关。计算机存储数据有两种字节优先顺序:Big Endian 和 Little Endian。Internet 以 Big Endian 顺序在网络上传输,所以对于在内部是以 Little Endian 方式存储数据的机器,在网络通信时就需要进行转换。
除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
golang中验证系统的大小端
package main
import (
"fmt"
"unsafe"
)
func main() {
a := int64(0x12345678)
fmt.Printf("int64: %v bytes\n", unsafe.Sizeof(a))
//用int8去转换int64,会只截取到第一个字节
s := int8(a)
if 0x12 == s {
fmt.Println("Big-Endian")
} else {
fmt.Println("Little-Endian")
}
fmt.Printf("s: 0x%x", s)
}
输出如下:
int64: 8 bytes
Little-Endian
s: 0x78
参考:
大小端字节序存在的意义,为什么不用一个标准呢?https://www.zhihu.com/question/25311159
http://www.ruanyifeng.com/blog/2016/11/byte-order.html
你知道字节序吗 https://zhuanlan.zhihu.com/p/115135603
“字节序”是个什么鬼? https://zhuanlan.zhihu.com/p/21388517
字节序及 Go encoding/binary 库 https://zhuanlan.zhihu.com/p/35326716
字节序:Big Endian 和 Little Endian https://songlee24.github.io/2015/05/02/endianess/

















 9129
9129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









