







前言
进入哈希表环节。继续。
记录十三:力扣【242. 有效的字母异位词】
一、介绍哈希表
来源【代码随想录】,总结:
(1)哈希表:根据关键码可以直接访问。
(2)作用:快速判断一个元素是否在集合中。
(3)哈希函数:通过特定编码方式,将其他数据格式转化为不同的数值。这个数值就是索引。
(4)哈希碰撞:两个对象映射到同一个索引。如何解决?
- 拉链法:在一个索引上,把冲突的对象放到一个链表中。那么要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
- 线性探测法:
- 一定要保证tableSize大于dataSize。 靠哈希表中的空位来解决碰撞问题。
(5)常见的哈希结构:
-
数组(通过下标索引获得数据。)
-
set (集合):
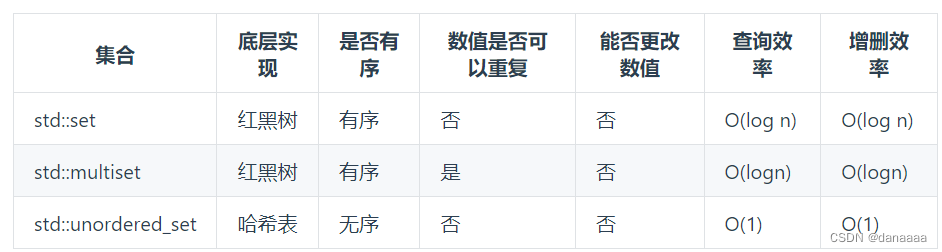
使用集合来解决哈希问题的时候:- 优先使用unordered_set,因为它的查询和增删效率是最优的。
- 如果需要集合是有序的,那么就用set;
- 如果要求不仅有序还要有重复数据的话,那么就用multiset。
-
map
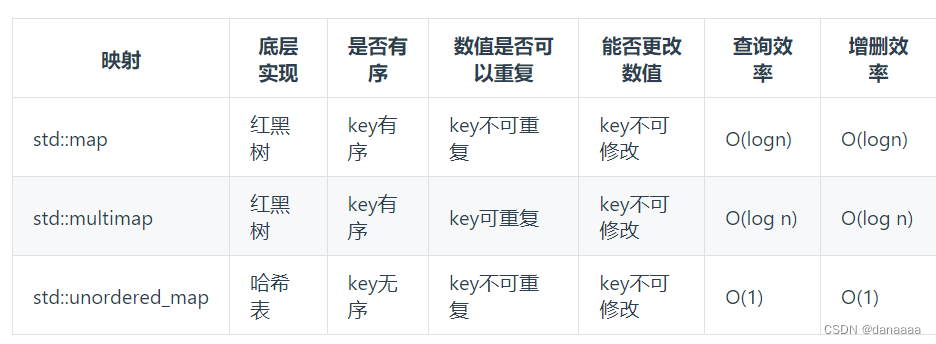
map 是一个key-value 的数据结构,map中,对key有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
虽然std::set和std::multiset 的底层实现基于红黑树,红黑树来存储和索引数据,仍然用哈希方法来使用:即用key来访问value。 std::map和std::multimap同理。 (红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。)
总结:遇到需要判断一个元素是否出现过,用哈希方法。快。
二、题目阅读
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
解释:‘a’出现3次;‘n’、‘g’、'r'、‘m’出现1次;
示例 2:
输入: s = "rat", t = "car"
输出: false
提示:
1 <= s.length, t.length <= 5 * 104
s 和 t 仅包含小写字母
进阶:
如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
二、第一次尝试
目标:看两个字符串中每个字符出现的次数是不是一样。
思路:26个小写字母,用容纳26个元素的数组表示,下标代表字母,按照字母顺序,也是ASCII码的顺序。存储的值是出现的次数。
- 给s和t分别创建数组:s_array[26]和t_array[26],并做初始化。
- 用stringstream处理string s和string t。依次获取单个字符,使得对应索引的数值++。
代码如下(测试通过):
class Solution {
public:
bool isAnagram(string s, string t) {
int s_array[26];
int t_array[26];
char a;//暂时存储读出的字符
//初始化
for(int i = 0;i < 26;i++){
s_array[i] = 0;
t_array[i] = 0;
}
stringstream stream1(s);
//先处理s
while(stream1 >> a){
int index = a - 'a';//ASCII码值
s_array[index]++;
}
//再处理t
stringstream stream2(t);
while(stream2 >> a){
int index = a - 'a';//ASCII码值
t_array[index]++;
}
for(int i = 0;i < 26 ;i++){
if(s_array[i] != t_array[i]){
return false;
}
}
return true;
}
};
三、代码随想录学习
学习内容
二、中的思路正确,但是可以将代码精简 :
- 第一:用一个数组来记录,处理s时候索引对应数值++;处理t时候索引对应数值–。最后判断数组所有值是否为0。(自然数组初始化时要全部处理为0)
- 第二:我用了stringstream来处理字符串,但是string类可以直接string[i]用下标运算符获取字符。
- 第三:index多了一行,可以直接和s_array[index]合并。
所以把代码改的更简单一些:
class Solution {
public:
bool isAnagram(string s, string t) {
int hash_array[26];
//初始化
for(int i = 0;i < 26;i++){
hash_array[i] = 0;
}
//先处理s
for(int i = 0;i < s.size();i++){
hash_array[s[i]-'a']++;
}
//再处理t
for(int i = 0;i < t.size();i++){
hash_array[t[i]-'a']--;
}
for(int i = 0;i < 26 ;i++){
if(hash_array[i] != 0){
return false;
}
}
return true;
}
};
总结
(1)可能听到哈希表,比较难理解。
- 但其实就是给一个输入x,x可以是任何类型,通过hashFunction函数,输出y,这个y就是表的下标索引。
- 加入时,给x,hashFunction求出y,按照y,直接把x放到y的位置。
- 删除时,给x,hashFunction求出y,按照y,直接从y取出x。
- 如果y相同时,两种解决:链表法:串项链一样的串起来;线性探测法:求出来y的位置被人占了,往下找个新的空位放进去。
(2)一看到找元素存不存在,可以先想“哈希法”:用哈希的数据结构来处理。能不能定义成索引,直接找它。如何转换索引,这就是自定义的HashFunction.















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









