







不得不说,堆排序太容易出现了,选择填空问答算法大题都会出现。建堆的过程,堆调整的过程,这些过程的时间复杂度,空间复杂度,以及如何应用在海量数据Top K问题中等等,都是需要重点掌握的。
1)算法简介
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
2)算法描述
我们这里介绍几个问题,一步步推到堆排序的算法。
1、什么是堆?
我们这里提到的堆一般都指的是二叉堆,它满足二个特性:
1---父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2---每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
如下为一个最小堆(父结点的键值总是小于任何一个子节点的键值)
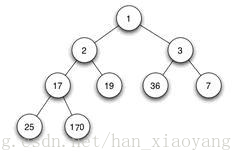
2、什么是堆调整(Heap Adjust)?
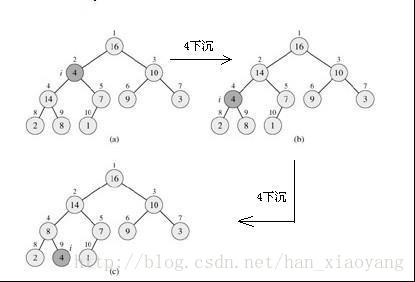
这是为了保持堆的特性而做的一个操作。对某一个节点为根的子树做堆调整,其实就是将该根节点进行“下沉”操作(具体是通过和子节点交换完成的),一直下沉到合适的位置,使得刚才的子树满足堆的性质。
例如对最大堆的堆调整我们会这么做:
1、在对应的数组元素A[i], 左孩子A[LEFT(i)], 和右孩子A[RIGHT(i)]中找到最大的那一个,将其下标存储在largest中。
2、如果A[i]已经就是最大的元素,则程序直接结束。
3、否则,i的某个子结点为最大的元素,将A[largest]与A[i]交换。
4、再从交换的子节点开始,重复1,2,3步,直至叶子节点,算完成一次堆调整。
这里需要提一下的是,一般做一次堆调整的时间复杂度为log(n)。
如下为我们对4为根节点的子树做一次堆调整的示意图,可帮我们理解。
3、如何建堆
建堆是一个通过不断的堆调整,使得整个二叉树中的数满足堆性质的操作。在数组中的话,我们一般从下标为(n-1) / 2的数开始做堆调整,一直到下标为0的数(因为下标大于n/2的数都是叶子节点,其子树已经满足堆的性质了)。下图为其一个图示:
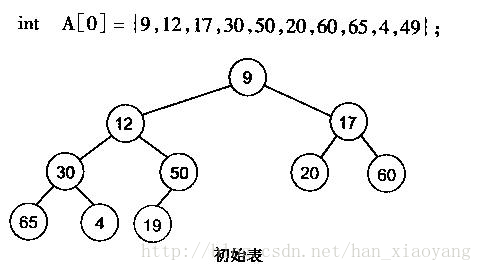
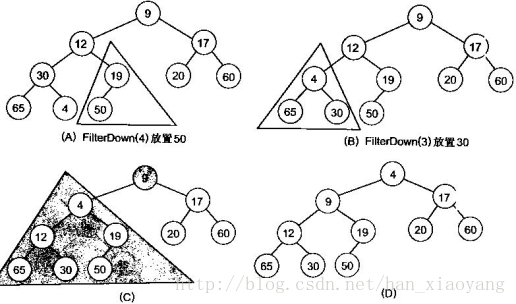
很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。
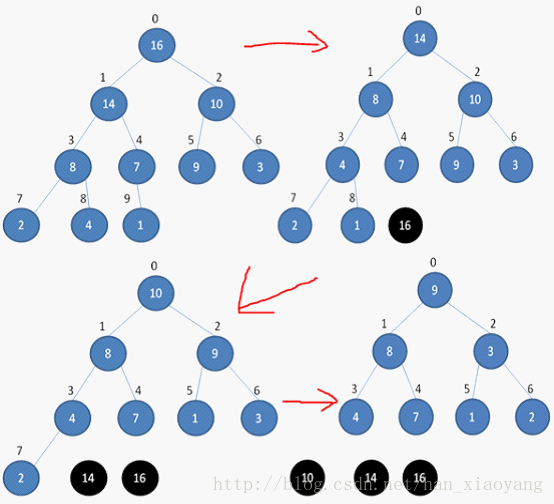
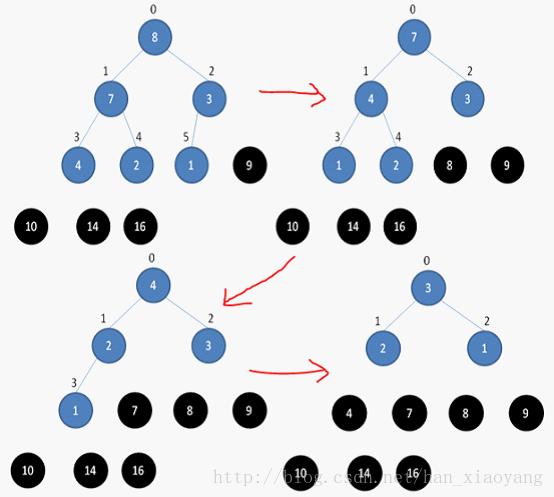
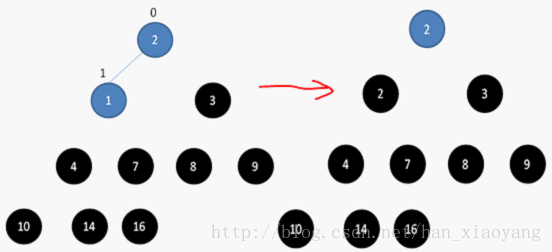
4、如何进行堆排序
堆排序是在上述3中对数组建堆的操作之后完成的。
数组储存成堆的形式之后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n-2]交换,再对A[0…n-3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。
如下图所示:
| 最差时间复杂度 | O(n log n) |
| 最优时间复杂度 | O(n log n) |
| 平均时间复杂度 | O(n log n) |
| 最差空间复杂度 | O(n) |
package Heap_Sort;
/*
* 堆排序算法 流程:建堆->堆调整->堆排序。先建堆,建堆的过程即堆调整过程,建好堆以后才能进行堆排序,每进行一次堆排序,都会伴随一次堆调整。
*/
public class heapSort {
// 获取第i个结点的父节点
public int parent(int i) {
return (i - 1) / 2;
}
// 获取第i个结点的左子节点
public int left(int i) {
return 2 * i + 1;
}
// 获取第i个结点的右子节点
public int right(int i) {
return 2 * i + 2;
}
/*
* 建堆的过程就是不断对堆调整的过程,当待排序序列用数组存储时,我们通常从i=(length-1)/2位置开始调整,i--,直到i=0
* (因为下标大于n/2的数都是叶子节点,其子树已经满足堆的性质了).
*/
public void buildHeap(int[] arr, int heap_size) {
for (int i = (heap_size - 1) / 2; i >= 0; i--) {
heapAdjust(arr, i, heap_size); //对第i个结点以下的所有结点进行堆调整
}
}
private void heapAdjust(int[] arr, int start, int heap_size) { //每进行一次堆调整的时间复杂度为O(logn)。
int l = this.left(start); //从数组中第start个数开始调整,将以第start个数为根节点的字数调整成堆的特性,然后退回到底start-1个元素进行调整
int r = this.right(start);
int temp;
int largest;
if (l < heap_size && arr[l] > arr[start]) {
largest = l;
} else {
largest = start;
}
if (r < heap_size && arr[r] > arr[largest]) {
largest = r;
}
if (largest != start) {
temp = arr[start];
arr[start] = arr[largest];
arr[largest] = temp;
heapAdjust(arr, largest, heap_size); //递归将根节点为i的子树调整为一个小堆
}
}
public void heap_Sort(int[] arr, int heap_size) {
buildHeap(arr, heap_size);
for (int i = heap_size - 1; i >= 0; i--) {
int temp = arr[i];
arr[i] = arr[0];
arr[0] = temp;
heapAdjust(arr, 0, i); //对剩余的heap_size-1个结点重新进行堆调整
}
this.print(arr, heap_size);
}
public void print(int[] arr, int heap_size) {
for (int i = 0; i < heap_size; i++) {
System.out.print(arr[i] + " ");
}
}
public static void main(String[] args) {
int[] arr = { 2, 4, 7, 45, 81, 1,5,8,100,13, 49, 23, 78, 90 };
int heap_size = arr.length;
heapSort heap = new heapSort();
heap.heap_Sort(arr, heap_size);
}
}
5)考察点,重点和频度分析
堆排序相关的考察太多了,选择填空问答算法大题都会出现。建堆的过程,堆调整的过程,这些过程的时间复杂度,空间复杂度,需要比较交换多少次,以及如何应用在海量数据Top K问题中等等。堆又是一种很好做调整的结构,在算法题里面使用频度很高。
6)笔试面试题
例题1、
编写算法,从10亿个浮点数当中,选出其中最大的10000个。
典型的Top K问题,用堆是最典型的思路。建10000个数的小顶堆,然后将10亿个数依次读取,大于堆顶,则替换堆顶,做一次堆调整。结束之后,小顶堆中存放的数即为所求。代码如下(为了方便,这里直接使用了STL容器):
例题2、
设计一个数据结构,其中包含两个函数,1.插入一个数字,2.获得中数。并估计时间复杂度。
使用大顶堆和小顶堆存储。
使用大顶堆存储较小的一半数字,使用小顶堆存储较大的一半数字。
插入数字时,在O(logn)时间内将该数字插入到对应的堆当中,并适当移动根节点以保持两个堆数字相等(或相差1)。
获取中数时,在O(1)时间内找到中数。















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









