









 本文介绍了如何使用Python尝试爬取B站视频封面。首先尝试通过直接访问URL获取源码,但由于B站的反爬机制,需要添加'Referer'头信息。使用urllib时出现乱码问题,但requests库能成功保存网页。然而,直接获取的网页无法找到封面图片,发现原因是动态加载。通过抓包工具找到请求`https://api.bilibili.com/x/web-interface/view?aid=41949084`,该请求返回的JSON数据中的`pic`字段即为封面。最后指出,通过改变请求中的`aid`参数即可获取不同视频的封面,若`code`为0表示查询成功。
本文介绍了如何使用Python尝试爬取B站视频封面。首先尝试通过直接访问URL获取源码,但由于B站的反爬机制,需要添加'Referer'头信息。使用urllib时出现乱码问题,但requests库能成功保存网页。然而,直接获取的网页无法找到封面图片,发现原因是动态加载。通过抓包工具找到请求`https://api.bilibili.com/x/web-interface/view?aid=41949084`,该请求返回的JSON数据中的`pic`字段即为封面。最后指出,通过改变请求中的`aid`参数即可获取不同视频的封面,若`code`为0表示查询成功。
尝试根据AV号爬取B站封面。。。
尝试一:
首先尝试直接根据网址获取到原网页源码获取封面
比如直接根据av号访问
https://www.bilibili.com/video/av41949084
import ssl
import urllib.request
url = 'https://www.bilibili.com/video/av41949084'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',
'Referer': 'https://www.bilibili.com'} # 竟然是这里的错误
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request, context=ssl.SSLContext(ssl.PROTOCOL_TLSv1_2))
print(response)
content = response.read()
with open('bilibili.html', mode='wb') as f:
f.write(content)
B站还是做了一点反爬措施的。。。因此要添加一定的头信息。。一定要添加
‘Referer’: ‘https://www.bilibili.com’ 。。。不然会报错。
然而 使用urllib。。。不知为何 保存下来的文件永远是乱码。。可能headers信息有误吧。。。
使用requests。。。
import requests
import urllib3
url = 'https://www.bilibili.com/video/av41949084'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',
'Referer': 'https://www.bilibili.com'} # 竟然是这里的错误
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get(url, headers=headers, verify=False) #证书验证设为FALSE
print(response)
content = response.content
with open('bilibili.html', mode='wb') as f:
f.write(content)
使用requests可以正常保存网页。。。
尽管 网页保存完成 但是并不能从该网页中获取到封面图片
然后甚至试了 https://search.bilibili.com/all?keyword=av41949084
网页。。。仍然查不到封面
这时应该想到是动态加载的。。。
尝试二:
接下来 使用抓包工具或者浏览器自带的F12 。。。查找响应请求
找了好久应该是该请求
https://api.bilibili.com/x/web-interface/view?aid=41949084
该请求返回结果如下
{"code":0,"message":"0","ttl":1,"data":{"aid":41949084,"videos":1,"tid":31,"tname":"翻唱","copyright":1,"pic":"http://i0.hdslb.com/bfs/archive/4467bebd1af3c206f36f8a1b4a41c95961d1bcb0.jpg","title":"【泠鸢】繁华唱遍(虽已不似当年景,仍有人传有人承)","pubdate":1549470685,"ctime":1548669455,"desc":"非常感谢能受邀翻唱这首歌!本家av36570707\n春晚我一直喜爱戏曲板块,实话说我平时也不看戏,但春晚上的戏曲节目总是能吸引我,我觉得这个板块的编排带着戏曲人浓浓的感情,当老中青三代演员一起谢幕时,总有一丝传承的感动。虽已不似当年景,仍有人传有人承…","state":0,"attribute":16768,"duration":256,"rights":{"bp":0,"elec":0,"download":1,"movie":0,"pay":0,"hd5":1,"no_reprint":1,"autoplay":1,"ugc_pay":0,"is_cooperation":0},"owner":{"mid":282994,"name":"泠鸢yousa","face":"http://i1.hdslb.com/bfs/face/c45b540d71e56da8127b44c318c97fe4b7d46a4a.jpg"},"stat":{"aid":41949084,"view":558754,"danmaku":4124,"reply":5882,"favorite":52951,"coin":75620,"share":7741,"now_rank":0,"his_rank":0,"like":66936,"dislike":0},"dynamic":"非常感谢能受邀翻唱这首歌!春晚我一直喜爱京剧板块,当老中青三代演员一起谢幕时,总有一丝传承的感动。虽已不似当年景,仍有人传有人承…","cid":75021374,"dimension":{"width":1920,"height":1080,"rotate":0},"no_cache":false,"pages":[{"cid":75021374,"page":1,"from":"vupload","part":"繁华唱遍_第四版_Mux","duration":256,"vid":"","weblink":"","dimension":{"width":1920,"height":1080,"rotate":0}}],"subtitle":{"allow_submit":true,"list":[]}}}
应该算是标准的json数据
该数据中的 data 中的 pic 正是封面
B站还是比较良心的。。。。
分析该请求即可知 只需将https://api.bilibili.com/x/web-interface/view?aid=41949084最后的aid 改为我们需要的即可。
如果该av号不存在呢。。。 比如 https://api.bilibili.com/x/web-interface/view?aid=41949
可以得到
{"code":62002,"message":"稿件不可见","ttl":1}
可以猜测 code 为 0 表示正常查询到该数据
至此。。。应该算是基本完工
import json
import requests
import urllib3
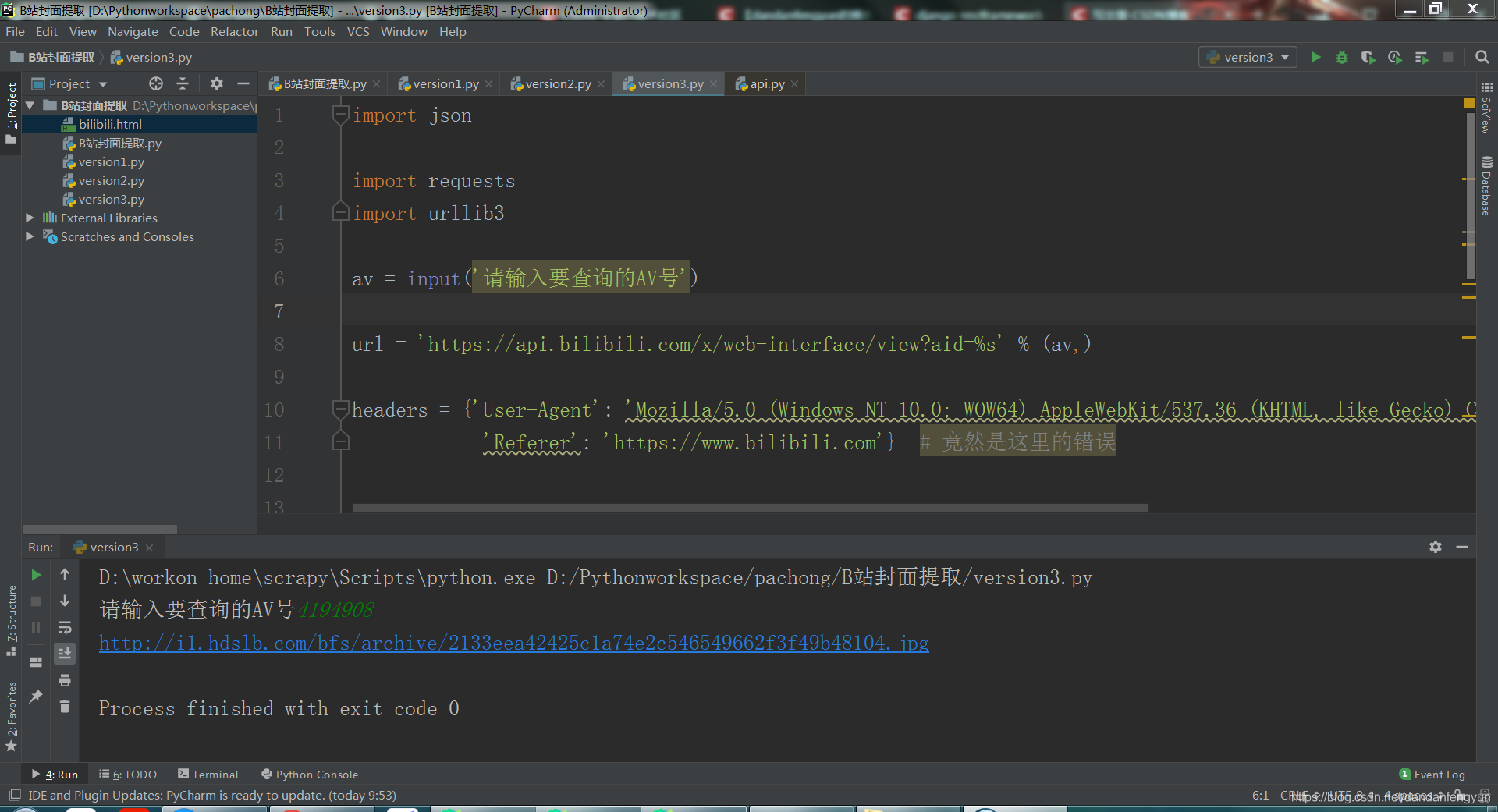
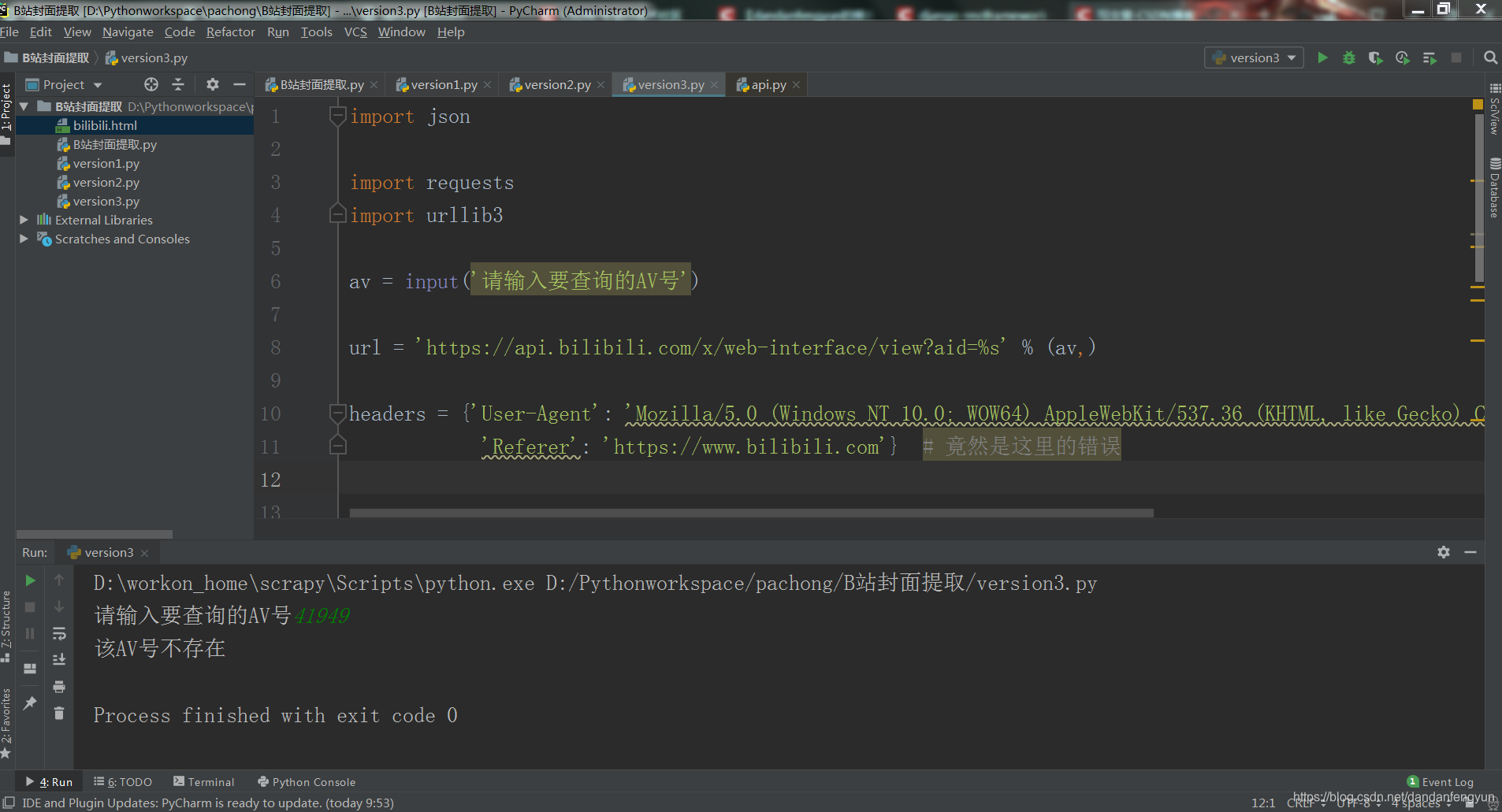
av = input('请输入要查询的AV号')
url = 'https://api.bilibili.com/x/web-interface/view?aid=%s' % (av,)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',
'Referer': 'https://www.bilibili.com'} # 竟然是这里的错误
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get(url, headers=headers, verify=False) #证书验证设为FALSE
content = json.loads(response.text)
# 获取到的是str字符串 需要解析成json数据
statue_code = content.get('code')
if statue_code == 0:
print(content.get('data').get('pic'))
else:
print('该AV号不存在')
如果也写一个服务器 供用户访问。。。我们也算作了一个 封面提取器 也感谢B站评论的封面提取器给了我学习的一点动力。

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









