







C语言中关于一个变量所占内存问题大家都很了解,比如int型占4字节,char占1字节。但是关于结构体的大小好向并不那么容易。下面我们先看一个简单的例子。
计算一下下面结构体的大小:
struct A
{
};处看这个结构体,它内部没有任何成员,很容易让人误以为它的大小为0,但是,经过测试,我们发现了一件很神奇的事情——在C语言和C++中,它所占内存不同。在C语言中,它的大小为0而在C++中它的大小为1.
在网上查到有这样一种说法:
1、在部分C编译器中,要求结构至少有一个成员。
2、在C++编译器中,根据网友的说法,因为C++标准规定,任何不同的对象不能拥有相同的内存地址。对于空类或空结构体,编译器会加一个字节来区别,故其大小为1。
而C++之所以自动加载1,是因为它更改了C语言的规定,结构体可以为空。但系统并不能创建一个大小为0的结构体出来。我们可以将struct A看作一个装有不同数据类型的成员的容器,这样就很容易理解了,。所以就算结构体为空,它所占的内存大小也不可能为0,非空结构体类型数据最少需要占一个字节的空间,而空结构体类型数据总不能比最小的非空结构体类型数据所占的空间还大。所以空结构体的大小既不能为 0,也不能大于 1,怎么办。所以编译器理所当然的认为你构造一个结构体数据类型是用来打包一些数据成员的,而最小的数据成员需要 1 个 byte,编译器为每个结构体类型数据至少预留 1 个 byte的空间。所以,空结构体的大小就定位 1 个 byte。
上面的例子只是简单了解以下struct的内存大小问题。下面我们再看一个例子:
struct A
{
char x;
int y;
}a;上面这个结构体大小有时多少呢?
我们最直观的理解可定会说,这么简单不就是5吗,可是编译器好像并不这么理解。我们可以看下测试结果:
[root@localhost Desktop]# gcc -o test test.c
[root@localhost Desktop]# ./test
sizeof(a) = 8
很显然,编译器认为它的大小是8。这是我们就要引入内存对齐的话题了。
许多计算机系统对基本数据类型合法地址做出了一些限制,要求
某种类型对象的地址必须是某个值 K(通常是 2、4 或 8)的倍数。这
种对齐限制简化了形成处理器和存储器系统之间接口的硬件设计。无
论数据是否对齐,其实程序都能跑下去。但是 Intel 还是要建议对齐
数据以提高存储器的性能。
其实 内存对齐是为了效率。那么它的对齐原则是什么,我们列举出来一一进行验证:
1.对于结构体的各个成员,第一个成员位于偏移量为 0 的位置,
以后每个数据成员的偏移量必须是 MIN(这个数据
成员的自身长度)的倍数。
2.在数据成员完成各自对齐之后,结构体本身也要进行对齐,对
齐将按照 MIN(结构体(共用体)最大数据成员长
度)。
但是正如上述所说,每个成员还得按照自己的方式对齐。配合上边的每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数(这里是 n 字节)中较小的一个对齐。
所以就出现了下述情况:
struct A1
{
char x1;
int y1;
char z1;
}a1;
struct A2
{
char x2;
char z2;
int y2;
}a2;a1和a2中都有三个成员,而且都是两个char型成员和一个int型成员。但是a1和a2的大小相同吗?答案是“不”,这就是上面提到的内存对其原则。它会先根据每个成员对齐,然后在按照整个结构体中最大数据成员对齐。
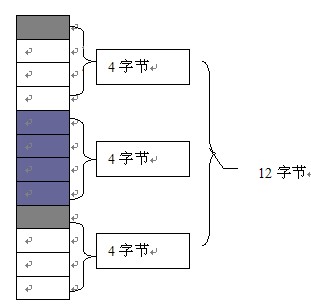
对于a1,首先x1位于a1首地址位置,占一个字节,但是由于第二个元素为int型占四个字节,按照每个成员内存对齐,它的偏移量应该是它本身长度的倍数,而1显然不是,所以必须最少空出3个字节,所以y2位于a1+4位置。最后一个元素为char一个字节,而此时它的偏移量为8,是它本身长度的整倍数。所以它从a1+5位置存储,有因为最后要按照整个结构体中最大数据成员长度(此处为4)对齐.所以a1大小为12字节。它的内存存储入下图所示:
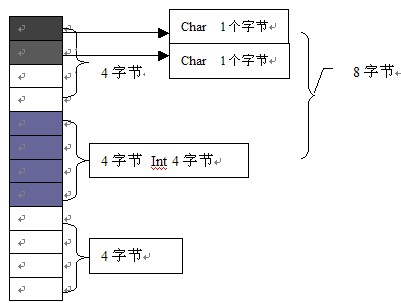
对于a2,x2同样位于a1首地址位置,占一个字节,但是由于第二个元素为char型占1个字节,按照每个成员内存对齐,它的偏移量应该是它本身长度的倍数,而1正好是,所以z2位于a1+1位置。最后一个元素为int型占4个字节,而此时它的偏移量为2,显然2是它本身长度4的整倍数,所以最少应该空出两个位置,使它的偏移量成为4的倍数。所以它从a1+4位置存储,有因为最后要按照整个结构体中最大数据成员长度(此处为4)对齐.所以a1大小为8字节。相对于a1来说,它节省了四个字节空间。所以一般在使用结构体时,最好将相同数据长度的变量放在一起,这样比较节省内存。它的内存存储入下图所示:
深刻理解内存对齐的好处:
1.在网络的数据传输中,如果能够组织起高效的数据报可以大
大节省空间。
2.TCP 和 UDP 的数据报,很多的位段用来描述数据报的状态。
3.考察学生是否进行过数据报的设计。那么内存对齐的好处确实不少:
a.加快内存的读取速度,提高了效率;
b.确保程序的正常执行,有的存储器访问要求存储器地址必须是16的倍数,不满足的会导致程序终止(这个时候需要强制对齐)。
最后,我们再一起看一道内存对其的题目:
#include <stdio.h>
#include <unistd.h>
struct A{
unsigned char x;
unsigned char y;
int z;
};
int main()
{
struct A a;
a.x = 10;
a.y = 20;
a.z = 30;
*((int *)&a) = 0x010101FF;
printf("%p, %p, %p\n", &a.x, &a.y, &a.z);
printf("%d %d %d %d\n", sizeof(a), a.x, a.y, a.z);
#endif
return 0;
}运行结果:
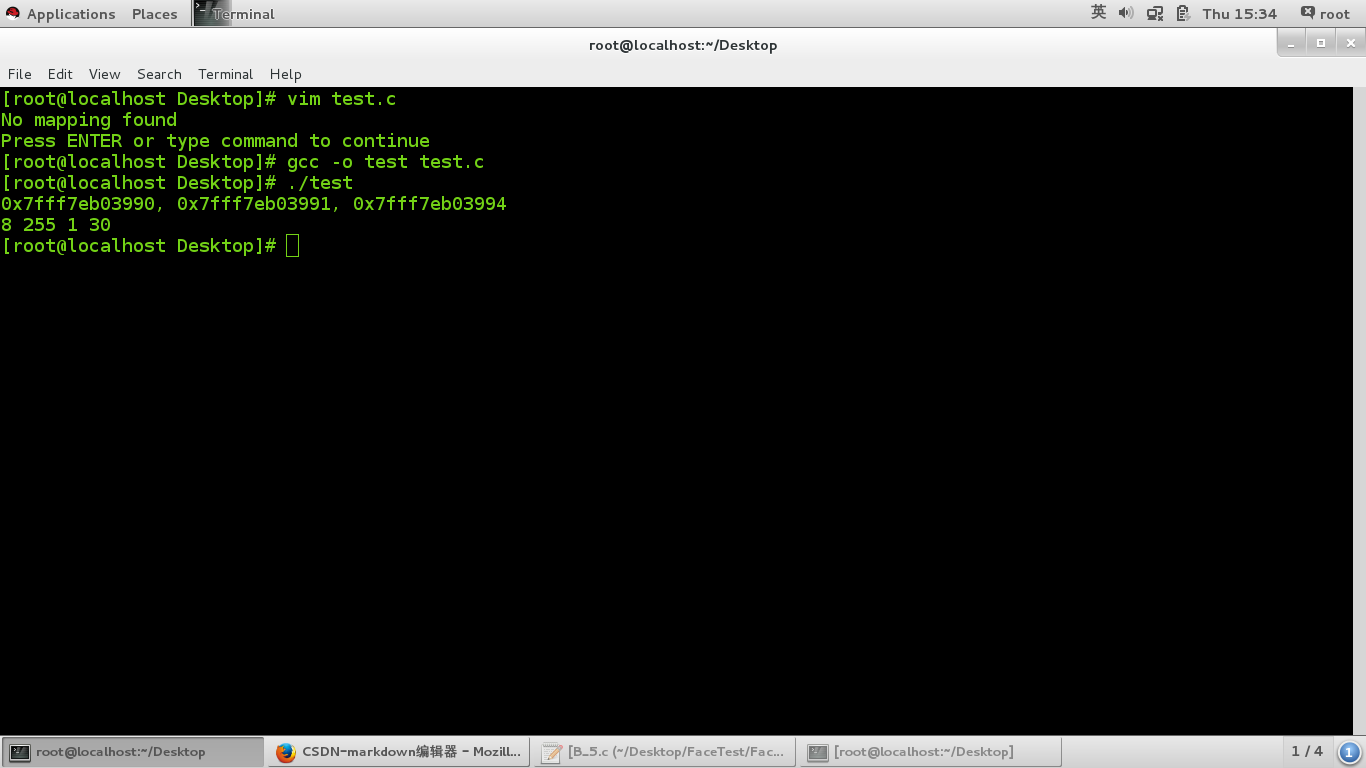
之所以sizeof(a) 为8,是因为内存对其,同上面a2。
而至于a.x、a.y、a.z的值为什么分别是255, 1, 30。那是因为虽然将a的成员强转成了int,然后将0x010101FF赋给a,但是读a里面的成员时,a.x、a.y还是unsigned char型,所以,((int )&a) = 0x010101FF 只是用来蒙蔽我们双眼的幌子而以。
它本质上如下所示:
A--> ________
(a.x) | 0A |
|________| <-- FF unsigned char : 0xFF -> 255
(a.y) | 14 |
|________| <-- 01 unsigned char : 0x01 -> 1
| |
|________| <-- 01
| |
|________| <-- 01
(a.z)--> | 00 |
|________| int : 0x1E -> 30
| 00 |
|________|
| 00 |
|________|
| 1E |
|________|















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









