






1、 前言
作为一名 C/C++ 程序员,字节是我们天天都要与之打交道的一个东西。我们和它熟稔到几乎已经忘记了它的存在。可是,它自己是不甘寂寞的,或迟或早地,总会在某些时候探出头来张望,然后给你一个腿儿绊。其实,只要你真正了解了它的底细,你就会畅行无阻。在本文中,我们将首先简要了解一下字节的概念,然后着重了解一下字节序问题和字节对齐问题。
注:笔者已经尽最大努力保证本文信息的正确性,但确实无法提供百分之百的担保。
2、 什么是字节
我们知道,二进制计算机(也就是我们目前接触到的几乎所有的计算机)的最小数据单位是位( bit )。一位数据只能够表示两种含义(需要说明,尽管我们通常把单个位表示的两种含义选择为相互对立的含义,但这并不是必然的,例如你可以认为 1 代表 5 个人, 0 代表 8 个人),对于绝大多数的计算要求,单个位显然不能满足。因此,我们通常都会使用一连串的位,我们可以称之为位串( bit string ,请爱好质疑的的朋友注意,此术语非我杜撰)。由于种种原因,计算机系统都不会让你使用任意长度的位串,而是使用某个特定长度的位串。一些常见的位串长度形式具有约定好的名称,如,半字节( nibble ,貌似用的不多)代表四个位的组合,字节( byte ,主角出场!)代表 8 个位的组合。再多的还有,字( word )、双字( Double word ,通常简写为 Dword )、四字( Quad word ,经常简写为 Qword )、十字节( Ten byte ,也简写为 Tbyte )。
在这些里面,字( word )有时表示不同的含义。在 Intel 体系里, word 表示一个 16 位的数值,它是固定大小的。而在另外一些场合, word 表示了 CPU 一次可处理的数据的位数,表示一个符合 CPU 字长( word-length )的数目的位串。事实上我们接触较多的 ARM 体系中, word 就有不同的含义,它表示一个 32 位的数据(与机器字长相同),对于 16 位大小的数据, ARM 使用了另外的一个术语,叫作半字( half-word ),请大家在文档阅读时加以注意。另外, Qword 也是 Intel 体系中的术语,其他的体系中可能并不使用。在本文中,我们按照 Intel 的惯例来使用字或者 word 这一术语。
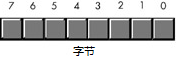
一个字节中共有 8 个数据位,有时需要用图表逐位表述各个位。习惯上,我们按照下面的图来排列各个位的顺序,即,按照从右到左的顺序,依次为最低位(从第 0 位开始)到最高位(对于字节,则是第 7 位):
字节是大多数现代计算机的最小存储单元,但这并不代表它是计算机可以最高效地处理的数据单位。一般的来说,计算机可以最高效地处理的数据大小,应该与其字长相同。在目前来讲,桌面平台的处理器字长正处于从 32 位向 64 位过渡的时期,嵌入式设备的基本稳定在 32 位,而在某些专业领域(如高端显卡),处理器字长早已经达到了 64 位乃至更多的 128 位。
3、 字节序问题的由来
对于字、双字这些多于一个字节的数据,如果把它们放置到内存中的某个位置上,可以看出,我们还可以将之看作是字节的序列。一个字是两个字节,双字则是四个字节。假设有以下数据: 0x12345678 、 0x9abcdef0 。在此处,我使用了我们最习惯的十六进制表示法,并给出了两个双字的值。按照惯例,我把双字的左侧视为高端,而把右侧视为低端。把它们顺序放置在起始地址为 0 的内存中,如下图所示:
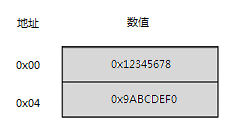
由图示可知, 0x9abcdef 的相应地址为 0x04 。现在,问题来了,如果有一个内存操作,要从地址 0x06 处读取一个字,得到的结果是多少呢?答案是:不一定。
这里的本质问题在于,如何把多字节的对象存储到内存中去呢?即使使用最正常的思维去考虑这个问题,你也会发现有两种方法。第一种方法是,把最低端的字节放到指定的起始位置(即基地址处),然后按照从低到高的字节顺序把其余字节依次放入,如下图 a ;另一种方法非常类似,但是对高端字节和低端字节的处理顺序正好相反,如下图 b (我确信你还可以想出其他的方法,但是除二字节的情况外,必然会打破字节排列顺序的一致性,我视之为反常规思维的产物,此处暂不考虑)。

图 a

图 b
在很久之前,哪一种存储方式更为合理曾经有过争论。到今天,争论的结果已经无关紧要了,紧要的是以下事实:这两种存储方式都被应用到了现实的计算机系统中。上图 a 中的排列方式为 Intel 所采用并大行其道,而图 b 的排列方式则被大多数的其他平台采用(如最近被苹果公司彻底抛弃的 PowerPC ),因此上,我们不能称之为罕见的用法。之所以造成事实上的不经常见到,其原因正如我今天中午所得到的消息: Intel 的 CPU 占整个市场份额的 80% 以上。
这两种排列方式通常用小端( little endian )和大端( big endian )来称谓。这两个奇怪的名字据说来源于童话《格列佛游记》,其中小人国里的公民为了鸡蛋到底是应该从小的一头打开还是大的一头打开而大起争执。 Intel 的方式对应于“小端”,顺便说一句,大端的方式也有一个大公司的名字作为其代表,即最近开始没落的 Motorola 。如果有谁了解过 TIFF 图像文件格式,就会发现其文件头中用以标识文件数据字节序的标志就是“ II ”和“ MM ”,分别对应于 Intel 和 Motorola 的首字母。值得提醒一下,小端方式的排列与位的排列顺序相一致,看上去似乎更协调一些。
现在我们可以回答上面的问题了。对于小端字节序,我们取到的字,其值为 0x9abc ,而如果是大端字节序的话,就会取到 0xdef0 。
4、 何时会出现字节序问题
字节序问题主要出现在数据在不同平台之间进行交换时,交换的途径可能是网络传输,也可能是文件复制。例如,如果你设计了一种可能会应用于不同平台的文件格式,其中存储了某些数据结构,则对于大小大于一个字节的数据就要明确地规定其遵循的字节序,以便各平台上的处理程序可以在使用数据时实现做必要的转换。
举一个实际的例子。 Java 是一个跨平台的编程语言,其可执行文件(扩展名为 .class ,使用的是一种机器无关的字节码指令集)在理论上可以运行于所有的实现了 Java 运行时的平台(包含有与特定平台相关特性的除外)。编译后的 .class 中一定保存有诸如 Integer 这样类型的数据,这就涉及到了字节序的确定,否则 .class 必然不能被采用了不同字节序的平台同时正确加载并运行。事实上, Java 语言采用的为大端字节序,这个一点都不奇怪,因为当初 SUN 公司自己的 SPARC 架构就是采用的大端字节序。同样的问题和解决问题的方式,也存在于操作系统新贵 android 系统上。
网络传输则是另一个典型场景。 TCP/IP 所采用的网络传输字节序标准也是大端字节序,这个也不必奇怪,因为 TCP/IP 是从 UNIX 系统发展起来的,而绝大部分的 UNIX 系统在很长的一段时间内都没有运行于 Intel 体系架构上的版本。
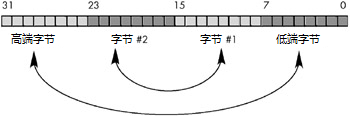
处理字节序问题的手段非常简单,也就是对数据进行必要的转换:将十六进制的数字从两端开始交换,直至移动到数据的中心,交换完成为止。交换的结果就好像物体与镜面之内的成像互换了位置,因此也被称为镜像交换( mirror-image swap )。请参看下图:
5、 如何在程序中判断字节序
在实际的工作中,有时需要对字节序进行判断,然后予以不同的处理。一般的来说,编译后的程序通常只能运行在特定的平台之上,其所采用的字节序方式在编译时即可确定,在这种情况下,程序源代码中通常是把字节序的判别作为条件编译的判断语句,而不会判断代码放在真正的可执行代码中。
在这里,需要使用我们的老朋友 —— 宏。以下是一个真实的跨平台工程中代码,清晰起见,我稍做了修改:
#define SGE_LITTLE_ENDIAN 1234
#define SGE_BIG_ENDIAN 4321
#ifndef SGE_BYTEORDER
#if defined(__hppa__) || /
defined(__m68k__) || defined(mc68000) || defined(_M_M68K) || /
(defined(__MIPS__) && defined(__MISPEB__)) || /
defined(__ppc__) || defined(__POWERPC__) || defined(_M_PPC) || /
defined(__sparc__)
#define SGE_BYTEORDER SGE_BIG_ENDIAN
#else
#define SGE_BYTEORDER SGE_LITTLE_ENDIAN
#endif
#endif
以上为根据平台的预定义宏所作的前期工作,将之存入一个头文件中,然后包含到源代码文件中使用。
在需要进行判断的时候,则像以下代码这样使用:
#if SGE_BYTEORDER == SGE_BIG_ENDIAN
#define SwapWordLe(w) SwapWord(w)
#else
#define SwapWordLe(w) (w)
#endif
由于这两个宏实际上被定义成了常量数值,因此也可以被用到可执行代码中,进行执行期的动态判断:
if(SGE_BYTEORDER == SGE_BIG_ENDIAN)
return r << 16 | g << 8 | b;
else
return r | g << 8 | b << 16;
追根寻源,上面的这种判断需要依赖编译器及其所在平台的预定义宏。下面介绍一种执行期动态判断的方法,则不需要有宏的参与,而是巧妙地利用了字节序的本质。代码如下:
int IsLittleEndian()
{
const static union
{
unsigned int i;
unsigned char c[4];
} u = { 0x00000001 };
return u.c[0];
}
动手画一下内存布局即可了解其原理。还有更简练的写法,作为练习,请大家自行去寻找。
在结束对字节序的讨论之前,特别提醒一下, ARM 体系的 CPU 在字节序上与 Intel 的体系结构是一致的。
6、 字节对齐问题的产生
冯诺依曼体系的计算机,通过地址总线来寻址内存(假设 n 为地址总线的位数,则最多可以寻址 2n 个内存位置)。根据地址总线的位数,我们可以知道 CPU 与内存的一次交互(也即一次内存访问)能够读写的数据的大小。显然地,对于 8 位的 CPU ,是一个字节,对于 16 位 CPU 则是一个字, 32 位 CPU 则是一个双字,依此类推。这是 CPU 与生俱来的最本质、最快捷的访问方式。在实际的计算需求中,如果访问的数据量超过了一次访问的限度,则很显然需要进行多次访问,如果是少于的话,则需要对从内存中取回的数据进行适当的裁剪。裁剪操作有可能是 CPU 自身支持的,也有可能是需要用软件来实现的。
有的系统是支持寻址到单个字节所在的位置的(称为可字节寻址),而有的则不可以,只能寻址到符合某些条件的地址上。对于 Intel/ARM 体系结构的 CPU ,我们在宏观上可以认为它们都支持字节寻址(但是 ARM 家族的 CPU 在内存访问时有其他约束,下文有详细叙述)。
出现这样的限制是有原因的,终极因素就在于内存访问的粒度与字长的关联上。用 32 位 CPU 来说,它对于地址为 4 的倍数处的内存访问是最自然的,其余的地址就要做一些额外的工作。例如,我们要访问地址为 0x03 处的一个双字,对于 80x86 体系,事实上将会导致 CPU 的两次内存访问,取回 0x00 以及 0x04 处的两个双字,分别进行适当的截取之后再拼装为一个双字返回。对于其他的体系,设计者可能认为 CPU 不应该承担数据拼装的工作,因而就选择产生一个硬件异常。
在硬件和 / 或操作系统的约束下,进行数据访问时对数据所在的起始位置以及数据的大小都需要遵循一定的规则 ,与这些规则相关的问题,都可以称之为字节对齐问题。
举例来说。在 HP-UX (惠普公司的一个服务器产品平台, UNIX 的一种)平台中,系统严禁对奇地址直接进行访问,假设你视这一原则于不顾:
int i = 0; // 编译器保证 i 的起始地址不是奇地址
char c = *((char*)&i + 1); // 强制在奇地址处访问
其执行结果就是内核转储( core dump ),为应用程序最严重的错误。(特别注明:此处代码为记忆中的情形,目前笔者已经没有验证环境了)
在不同的硬件体系架构下,字节对齐关系到三方面的问题,一是数据访问的可行性问题,二是数据访问的效率问题,三是数据访问的正确性问题。
字节对齐问题给程序员在编码时带来了额外的注意点,并且对最终程序执行的正确性也带来了一定的不确定因素。相同的代码在不同的平台上,甚至在相同的平台上采用不同的编译选项,都可能有不同的执行结果。
如果所有的系统都和 HP-UX 的表现一样的话,事情要简单一些,问题通常会在比较早的时间内就可以暴露出来。遗憾的是,我们目前所面对的平台不是这样,这些平台的设计者为最大程度地减少对开发人员的干扰而作了辛苦的努力,使得我们在很多时候都感觉不到字节对齐问题的存在。但另一方面,也制造出了把问题隐藏得更深的机会。
效果最好的努力是 Intel 的体系架构。 80x86 允许你对整个内存进行字节寻址,在不超过机器字长的情况下可以访问任意数目的字节(很显然,大多数情况下就是 1 字节、 2 字节、 3 字节、 4 字节这四种情况)。
ARM 体系的 CPU 似乎做了一定的努力,但是其结果和其他体系相比呈现一种很奇怪的状态。由于笔者没有对 ARM 整个系列的 CPU 进行过完整的了解,因此此处的论述可能并不完整。 ARM CPU 允许对内存进行字节寻址,但在访问时有额外的要求。即:如果你要访问一个字(注意本文惯例,此处的字是两字节大小,与 ARM 平台的标准术语不同),那么起始地址必须在一个字的边界上,如果访问一个双字,则起始地址必须位于一个双字的边界上(其余数据类型请参考 ARM 的知识库文档)。这意味着,你不能在 0x03 这样的地址处访问一个字或者一个双字。但是,令人痛苦的事情到来了,如果你非要这么访问,大多数的 CPU 不会有显式的异常,而是返回错误的数据,其余的一些 CPU 则会造成程序崩溃。
7、 如何控制字节对齐
控制程序的字节对齐行为是一个与编译器相关的工作。以下编译指示( directive )被许多编译器认可:
#pragma pack(n)
#pragma pack()
任何处于这两个编译指示语句之间的数据结构,将采用 n 字节的数据对齐方式。 n 是一个可以指定的数字,取值范围请参阅所使用编译器的文档,通常都会取值为 2 的幂。现代编译器在对程序进行编译时,处于效率方面的考虑,会对数据结构的内存布局使用一个默认的字节对齐值,这个值一般都可以在命令行上显式指定。如果要在一个头文件 / 源文件中对特定的部分指定对齐属性,则需要上述的编译指示。结束指示的写法在某些编译器或者平台下需要写成:
#pragma pack(pop)
我们用一个例子来看一下这两个指示的实际效用,看它究竟是如何影响数据的内存排列的。假定我们有如下的数据结构定义:
struct S1
{
int i;
char c;
short s;
};
struct S2
{
char c;
int i;
short s;
};
这两个结构的成员看起来是一样的,只不过换了一下顺序而已。我们使用 sizeof() 操作符来测量各自占用多少字节(除非特别指出,均在 32 位平台上,并认为 int 占用 4 字节, char 占用 1 字节, short 占用 2 字节)。答案似乎不可思议, sizeof(S1) 的结果是 8 ,而 sizeof(S2) 却是 12 。差异是怎么来的呢?原因就在于编译器缺省的字节对齐设定在发生作用。
这里需要引入以下概念和规则:
概念及规则一,原生数据类型自身对齐值。原生数据类型即是 C/C++ 直接支持的数据类型,也可以称为内建( built in )数据类型。它们的自身对齐值分别为: char 为 1 , short int 为 2 , int 、 float 、 double 等为 4 ,不受符号位(即正负)的影响。
概念及规则二,用户数据类型自身对齐值。用户数据类型即由程序员定义的类、结构、联合等,也叫抽象数据类型( ADT )。它们的自身对齐值等同于为其成员的对齐值中的最大值。
概念及规则三,用户指定对齐值。程序员在编译器命令行上的指定值,或者在 pragma pack 编译指示中指定的值,对最终数据的影响取就近原则(显然 pragma pack 指示会覆盖命令行的指定)。
概念及规则四,有效对齐值。取数据类型的自身对齐值与用户指定对齐值中的较小值。此值一旦决出,则会影响到数据在内存中的布局。一个有效对齐值为 n ,表示以下事实:相关数据在内存中存放时,其起始地址的值必须可以被 n 整除 。
根据以上四条,可以很圆满地解释 S1 和 S2 的大小不同这一现状。由于没有使用 pragma pack 指示,那么编译器(在我的测试环境下)会采用缺省的对齐值 4 。假设 S1 或者 S2 的实例将从地址 0x0000 处开始。
在 S1 中,第一个成员 i 的自身对齐值为 4 ,指定对齐值(尽管是缺省的)也是 4 ,同时 0x0000 这一地址符合被 4 整除的要求,因此, i 将占据 0x0000 到 0x0003 的四个字节,下一个可用地址值为 0x0004 ;接下来的成员 c 的数据类型为 char ,自身对齐值为 1 ,指定对齐值为 4 ,取较小者仍然是 1 , 0x0004 符合被 1 整除的要求,因此 c 将占据 0x0004 处的一个字节,下一个可用地址值为 0x0005 ;最后的一个成员 s 数据类型为 short ,自身对齐值为 2 ,指定对齐值为 4 ,有效对齐值取 2 ,但是地址 0x0005 不能符合被 2 整除的要求,因此编译器作相应调整,向后移动到最近的满足要求的地址处,即 0x0006 , s 将占用 0x0006 和 0x0007 处的两个字节,由此导致 S1 的大小为 8 。
在地址 0x0005 处的一个字节,习惯上称之为填充数据( padding )。
同理可以轻易推出 S2 结构的大小确实是 12 。是这样吗?不是的。实际动手的结果应该是 10 。那么 12 应该作何解释?
我们来设想一个场景,程序员用 new 或者 malloc 分配一个 S2 的数组。不用多,假定有两个元素,而地址 0x0000 处正好有空闲的内存可以满足这一内存分配请求。我们都知道,在 C/C++ 语言中,数组的元素是紧邻排放的。也就是说,后一个元素的起始地址应该正好等于前一个元素的起始地址,并加上元素的大小。我们来检视一下 S2 的情况,它的元素大小为 10 ,它的有效对齐值是 4 (请参阅概念及规则二),这表示任何一个 S2 结构的起始地址都应该位于 4 的整数倍处。现实的情况是,第一个元素的起始地址是 0x0000 ,第二个元素的起始地址变成了 0x000A ,而后者的数值不能满足被 4 整除的要求。正是为了解决这一情况,编译器为 S2 结构在结尾处也增加了两个字节的填充,从而满足各个条件的限定。
pragma pack 指示非常有效,使用也比较普遍,但是对于 ARM 平台,它有一些力所不及的地方,我们再来看一个例子。仍然用 S2 ,这一次,我们强制把它的字节对齐设定为 1 ,并同时定义了 S2 的一个全局变量 s2 。也即:
#pragma pack(1)
struct S2
{
char c;
int i;
short s;
} s2;
#pragma pop()
然后,在某处具有如下的数据访问:
int i = s2.i;
这条看上去稀松平常的语句很可能不能如所希望的那样执行。因为对于 i 的访问其前提应该是 i 的起始地址是 4 的倍数(注意,这个不是对齐规则的约束结果,而是 ARM CPU 的数据访问规则的约束结果),但强行指定的 1 字节对齐则导致 i 的起始地址是一个奇数。
RVCT 编译器为此做了特别的努力,引入了 __packed 关键字。此关键字应用到用户定义数据结构上会导致该结构的内存布局取得与 pragma pack(1) 等同的效果,但是,更进一步地,编译器会把对该结构中成员的访问作适当的处理,发现不对齐的访问则会翻译为调用适当的保证数据正确性的函数。此关键字也可以应用到指针上,以保证经由指针对目标对象的访问也采用保守方式。可以预料到的是,此关键字的使用会降低代码执行的效率,所以需要慎用,一个很典型的使用场景是移植其他平台的代码时。以下是一些使用了此关键字的定义示例:
typedef __packed struct
{
char x; // 所有成员都会被 __packed 修饰
int y;
} X; // 5 字节的结构,自身对齐值 = 1
int f(X* p)
{
return p->y; // 执行一个非对齐的读取操作
}
typedef struct
{
short x;
char y;
__packed int z; // 仅 __pack 本成员,此用法仅适用于整型
char a;
} Y; // 8 字节结构,自身对齐值 = 2(请思考原因)
int g(Y* p)
{
return p->z + p->x; // 仅对 z 执行非对齐读取操作
}
需要注意的是, GCCE 编译器没有实现类似的努力,它有一个和对齐有关的关键字: __attribute__ (packed)) ,该关键字的功效与 pragma pack(1) 类似。
8、 思考 / 练习题
a) 位( bit )在字节中的排列,应该也有类似字节序那样的问题,为什么没有?
b) 自己写几个结构,根据规则推断其大小,然后写代码验证
c) 请查阅 RVCT 的相关文档,学习 __align 关键字的含义和用法
d) 了解微软公司针对 Windows Mobile 平台的编译器是否也具有帮助程序员自动解决对其访问的机制
9、 参考资料
a) 《编程卓越之道》,第一卷
b) 《 RealView Compilation Tools - Compiler and Libraries Guide 》
d) http://blog.csdn.net/xhfwr/archive/2006/07/23/963793.aspx















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









