







python2中的中文乱码情况,本文将从一下四种情况进行展开。
下面两句话是本文的重点,文中的内容都是围绕下面两句话展开的
1.乱码的本质是字符的编码格式与显示字符的环境编码格式不一致引起的。这句话告诉我们要解决乱码问题,我们需要知道两个信息,一个是字符本身是什么编码,另一个就是显示字符的环境编码是什么,两者必须一致,才能显示出正确的内容。
2.在python中,对于任何Unicode类型编码的字符,打印时会自动根据环境编码转为特定编码后再显示。
接下来,看看字符在python代码中是如何被编码的。在不同的python版本中,字符编码的方式不一样。本文主要说的是python2版本。
乱码情况1
python2默认使用ASCII来编码代码的,如果代码中出现中文,那么就必须在py文件的开头注明支持中文的编码格式,如果没有声明,python2就会使用默认的ASCII编码来识别中文,就会报错。
s = "中文"
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
File "E:/PycharmProjects/LEDdisplay2/1.py", line 1
SyntaxError: Non-ASCII character '\xe4' in file E:/PycharmProjects/LEDdisplay2/1.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
Process finished with exit code 1
上述报错翻译过来就是,在1.py文件的第一行有非ASCII字符“\e4”,而且没有声明编码。
如果我们设置编辑器pycharm此时的环境编码是utf-8的话,用软件查看1.py文件的十六进制,可以看到“中文”存储的是\xe4\xb8\xad\xe6\x96\x87。(utf-8存储文件一个字符需要三个字节表示,可以看到“中文”两个字符是六个字节)
使用nodepad++查看十六进制

python2默认编码格式ASCII编码是不认识“\xe4”的,无法识别“中文”,所以会报错。所以,需要在py文件的开头加上 # encoding:utf-8 声明脚本的编码方式,则python就可以识别代码中的汉字字符串,并按照声明的字符编码格式来进行编码。
补充:
代码查看python环境的默认编码
代码查看字符串的十六进制
# encoding:utf-8
import sys
s = "中文"
print(sys.getdefaultencoding())
print (repr(s))
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
ascii
'\xe4\xb8\xad\xe6\x96\x87'
Process finished with exit code 0
乱码情况2
如果我们在py文件开头声明脚本的编码格式为utf-8,设置编辑器pycharm的环境编码为GBK,那么,当我们打印中文时,会出现什么情况呢?答:还是乱码
# coding=utf-8
s = "中文"
print(s)
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
涓枃
Process finished with exit code 0
pycharm编码设置:
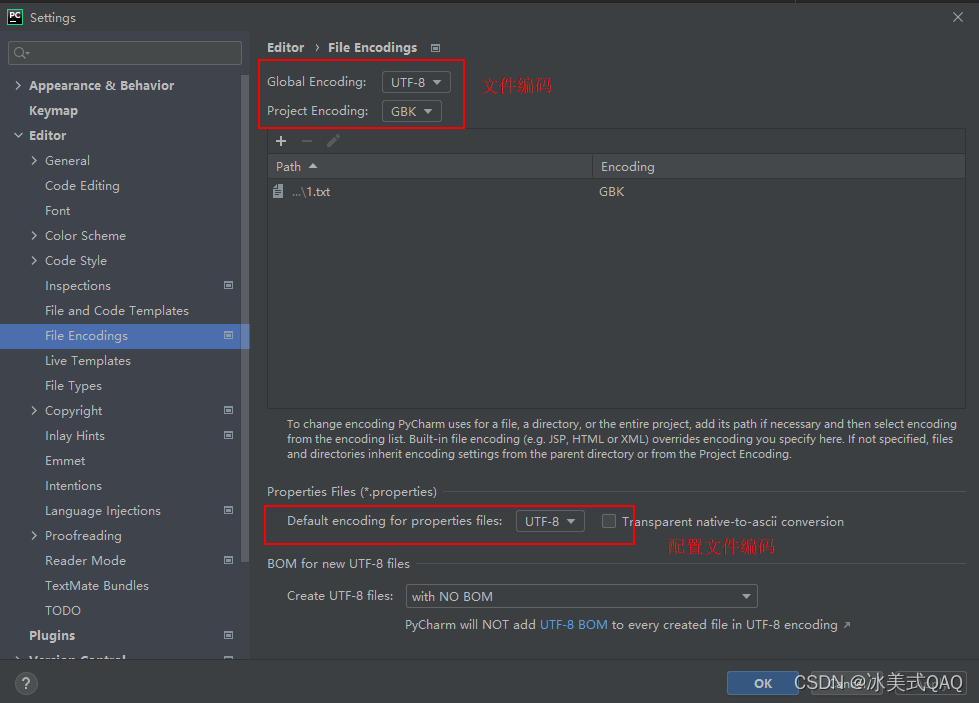
原因是,上述代码中s变量的编码是utf-8的,而我们运行脚本的编辑器pycharm设置的环境编码却是GBK,两者编码方式不一致,所以必定会出现乱码。
解决方法有以下几种:
(这几种方法是互斥的,目的是为了保证文件开头声明的编码格式和pycharm编辑器设置的环境编码格式一致)
1.可以修改编辑器pycharm的环境编码为UTF-8
2.可以修改py文件开头声明脚本的编码方式为GBK
3.在变量s前加一个u,将其强制转换为Unicode编码(前面已经说过了,对于Unicode编码的字符,python打印时会自动根据环境编码转为特定编码后再显示)
4.通过decode和encode函数。使用decode方法可以将字符串按照指定的格式解码成Unicode,需要注意的是,我们对所有的非Unicode类型的字符只能进行decode操作,不能进行encode操作,对Unicode类型的字符只能进行encode操作,不能进行decode操作。
# encoding:utf-8
s = "中文"
y1 = s.decode("utf-8") # s.decode("utf-8")这句话跟u“中文”效果是等价的
y2 = s.decode("utf-8").encode("gbk")
print(y1)
print(y2)
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
中文
中文
Process finished with exit code 0
注意:encode和decode的时候都是需要指定编码的。
在 Python 中编码是可以互相转换的,但是不同编码之间不能直接转换,需要通过Unicode字符集中间过渡下。比如从utf-8转换为gbk,需要先将utf-8格式解码成Unicode,再编码成gbk格式。
encode的正常使用:对Unicode类型进行encode,得到字节串str类型。也即是Unicode-> encode(根据指定编码) -> str。
decode的正常使用:对str类型进行decode,得到Unicode类型。也即是str -> decode(根据指定编码) -> Unicode。
encode的不正常使用:对str类型进行encode,因为encode需要的是Unicode类型,这个时候python会用默认编码decode成Unicode类型,再用你给出编码进行encode。(注意这里默认编码不是开头的encoding,而是ASCII编码)
decode的不正常使用:对Unicode类型进行decode,python会用默认的系统编码encode成str类型,再用你给出的编码进行decode。
另外,需要注意的是,用什么字符编码对Unicode进行编码(编码为str类型),就要用对应的字符编码对str类型进行解码(解码为Unicode类型)。
举个不正常使用的例子:
# encoding:utf-8
import sys
s = "中文"
print(sys.getdefaultencoding())
y3 = s.encode("utf-8")
print(y3)
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
ascii
Traceback (most recent call last):
File "E:/PycharmProjects/LEDdisplay2/1.py", line 5, in <module>
y3 = s.encode("utf-8")
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
Process finished with exit code 1
上面的代码可以看出,python2的默认编码是ASCII编码,直接对str类型的变量s进行encode时,python会使用默认编码ASCII码将变量s先deconde成Unicode,而文件开头已经声明代码用utf-8编码,所以会报ASCII码无法decode字节“0xe4”,而“0xe4”是utf-8编码存储变量s=“中文”的第一个字节的十六进制表示。
乱码情况3
将下面代码文件(存储时选择utf-8编码)直接在命令行里面运行,又会发生什么问题呢?
# encoding:gbk
s = "中文"
y1 = s.decode("gbk") #s.decode("gbk")这句话跟u“中文”效果是等价的
y2 = s.decode("gbk").encode("utf-8")
print(y1)
print(y2)

y1正常显示中文了,y2却出现了乱码。这次出现乱码的原因又是什么呢?windows命令行的环境编码是GBK格式,y1经过decode后是Unicode码,前面提到对于任何Unicode类型编码的字符,打印时python会自动根据环境编码转为特定编码后再显示,所以y1在cmd命令行下正常显示。y2经过解码和编码后是utf-8格式,只能在环境编码为utf-8的环境中才能正常显示,在winows命令行下运行就会出现由于编码不一致而导致的乱码。
如果上述代码再加一句print(s),将其分别在pycharm和cmd下运行,结果会是怎样呢?
# encoding:gbk
s = "中文"
y1 = s.decode("gbk") #s.decode("gbk")这句话跟u“中文”效果是等价的
y2 = s.decode("gbk").encode("utf-8")
print(y1)
print(y2)
print(s)
E:\PycharmProjects\LEDdisplay2\venv\Scripts\python.exe E:/PycharmProjects/LEDdisplay2/1.py
中文
中文
����
Process finished with exit code 0
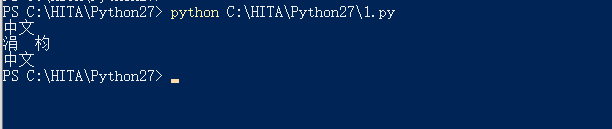
在pycharm环境下运行,输出s会乱码,因为pycharm环境编码我们设置的是utf-8,文件开头声明编码是gbk,编码方式不一致,故乱码。在cmd环境下运行,输出a不会乱码,因为cmd环境编码是GBK,而我们开头文件声明的编码格式也是GBK,编码方式一致,故正常显示。
上述的代码都是在python2环境下运行的,如果是python3的脚本的话,则要简单得多。因为python3中,所有的字符串不再受系统环境编码的影响,统一使用Unicode来进行编码,字符串类型统一为str,所以不再需要在中文前面加u来使中文字符变为Unicode这种写法。而且所有python3的脚本默认都是utf-8来编码的,所以我们也不需要在脚本开头指定coding:utf-8了(但是一般建议写上,兼容python2)。打印显示的时候也会方便很多,由于是字符串都是Unicode格式,所以不管在命令行中还是pycharm中,都会正常显示而不会出现乱码。
乱码情况4
如果是直接在命令行中写脚本,又会出现什么问题呢?我们只需要弄清楚字符本身的编码和环境编码是否一致就可以得出答案了。在python shell(即命令行)中直接写代码运行时,我们需要知道的是,windows下命令行的默认编码是gbk的,Linux环境下命令行的默认编码是utf-8的。
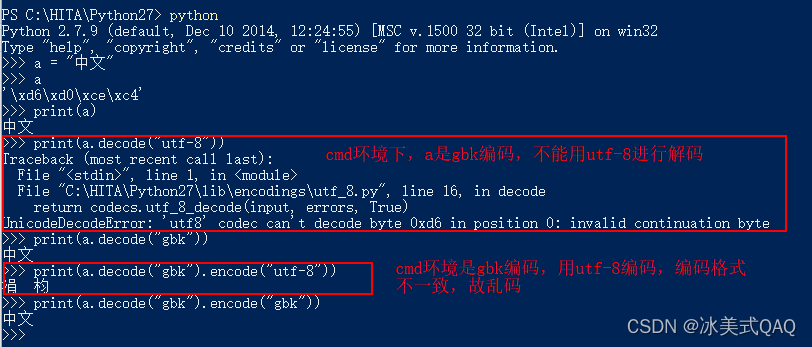
第一行我们在定义a="中文"时,并不会报错,因为在命令行中默认是gbk编码,所以此时其实a的编码已经是gbk了,支持中文没有任何问题。直接显示a变量时,打印出来的不是乱码,而是该字符串的字节码表示方式,大家可以理解成给计算机看的,不是给人看的,只有print出来的内容才是给人看的。print(a)也不会报错,因为按照gbk方式编码并且在gbk环境中运行,不可能会出问题。
直接将a进行decode解码时,解码方式必须跟编码方式是一致的,gbk方式编码的内容不能用utf-8解码为Unicode,只能用gbk解码成Unicode。用gbk进行decode之后,字符串会变为Unicode,python会自动根据环境的编码进行编码,故可以正常显示。最后,我们将Unicode按照utf-8编码时,字符的编码格式又跟环境编码不一致了,所以再次出现了乱码。linux下同理,只是linux下命令行的默认编码格式是utf-8。
参考链接:
https://blog.csdn.net/joyfixing/article/details/79971667
https://zhuanlan.zhihu.com/p/74613584?utm_source=wechat_session
https://www.cnblogs.com/liaohuiqiang/p/7247393.html















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









