






二叉树思想小结
1、二叉树:每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。
2、平衡二叉树,又称AVL树。它或者是一棵空树,或者它的左子树和右子树都是平衡二叉树,且左子树和右子树的高度之差之差的绝对值不超过1。
3、二叉树的高度:树中结点的最大层次称为树的深度(Depth)或高度。
4、完全二叉树与满二叉树:
完全二叉树:除最后一层可能不满以外,其他各层都达到该层节点的最大数,最后一层如果不满,该层所有节点都全部靠左排
满二叉树:除最后一层的结点外,每一层的所有结点都有两个子结点。
看个图:
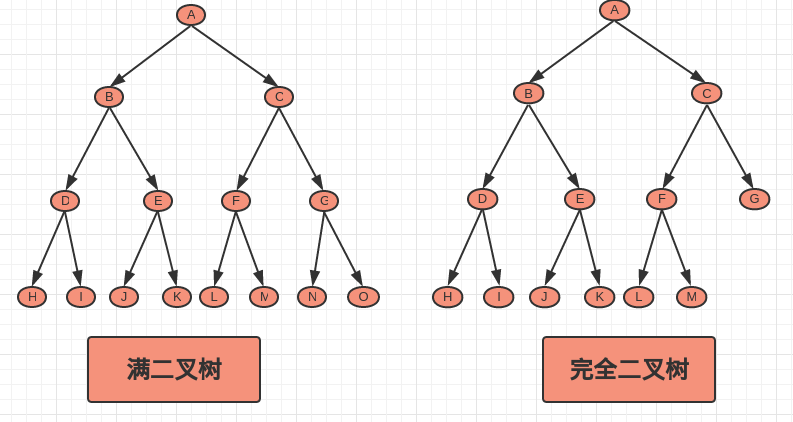
由图可以知道:满二叉树是特殊的完全二叉树
| 项目 | 满二叉树 | 完全二叉树 |
|---|---|---|
| 节点与度数 | N=2^(k-1) | 2^(k-1)-1~2^k-1 |
| 节点与边数 | S=N+1 | S=N+1 |
5、二叉树的遍历:
访问结点操作发生位置命名:
① 前序遍历(PreorderTraversal亦称(先序遍历))
前序遍历:根节点->左子树->右子树
——访问根结点的操作发生在遍历其左右子树之前。
② 中序遍历(InorderTraversal)
中序遍历:左子树->根节点->右子树
——访问根结点的操作发生在遍历其左右子树之中(间)
③ 后序遍历(PostorderTraversal)
后序遍历:左子树->右子树->根节点
——访问根结点的操作发生在遍历其左右子树之后。
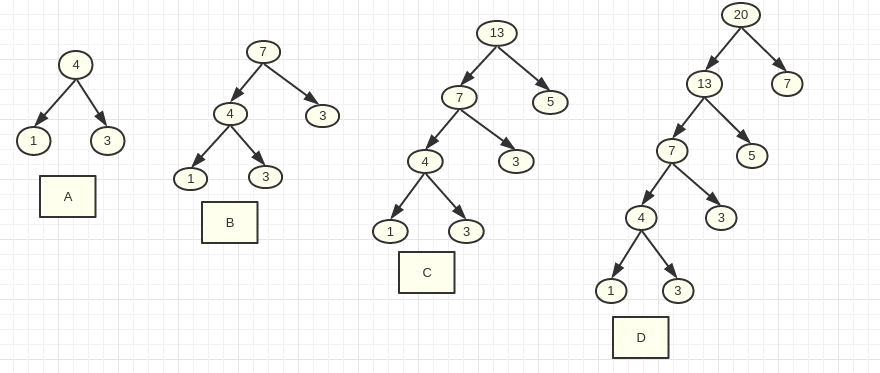
6、最优带权二叉树:
仅以哈夫曼算法为例:
①对节点进行升序排序;
②选取最小的两个节点,合成一棵二叉小树,计算权和
③ 返回第一步,直到节点用完
给定节点: 3 5 1 7 3
7、将树转换为二叉树
树中每个结点最多只有一个最左边的孩子(长子)和一个右邻的兄弟。按照这种关系很自然地就能将树转换成相应的二叉树。
步骤是:
①加线:在各兄弟结点之间用虚线相连。可理解为每个结点的兄弟指针指向它的一个兄弟。
②抹线:对每个结点仅保留它与其最左一个孩子的连线,抹去该结点与其他孩子之间的连线。可理解为每个结点仅有一个孩子指针,让它指向自己的长子。
最后整理一下各节点的角度















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









