







Convolutional Neural Networks卷积神经网络
I. Neural Networks [5]
Neural networks是模仿人的大脑皮层的计算过程。大脑完成许多任务,并不需要许多programs,实际上只需要一个。
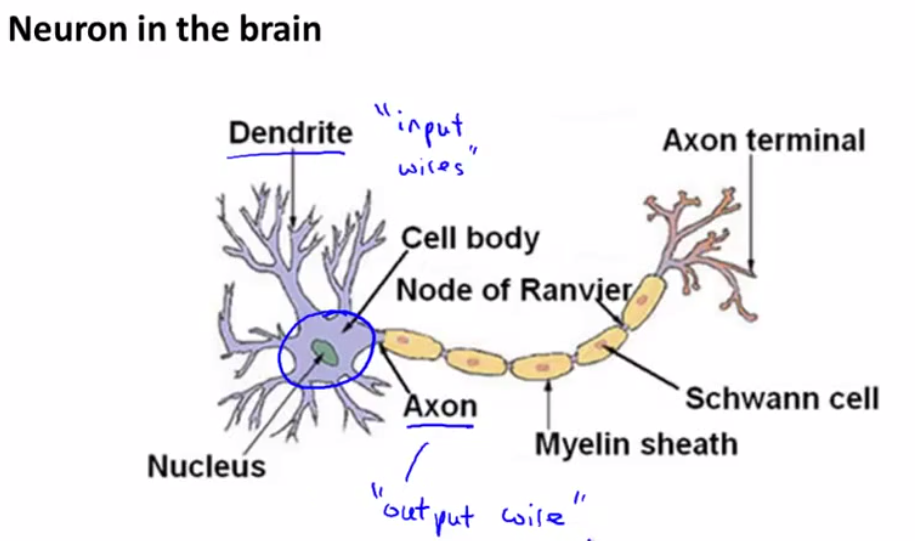
Dendrite接收消息,传到Cell body处理,通过Axon输出到下一个Nucleus的Dendrite。信号通过一个个Nucleus一级级传输。建模为以下模型:
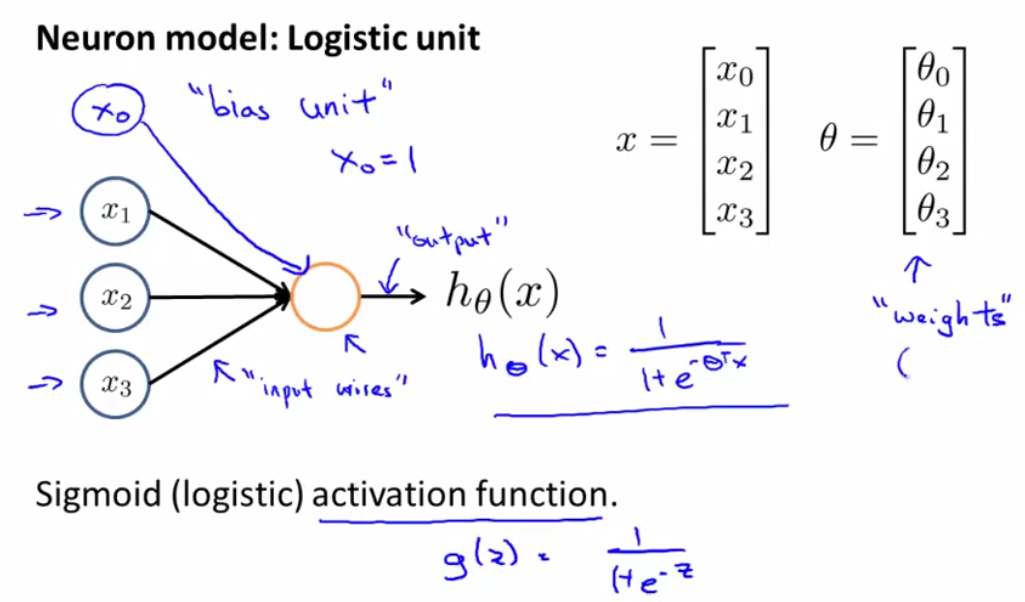
输入信号为x0, x1, x2, x3,其中x0为bias unit,且始终值为1。x0, …, x3与系数θ相乘后,做sigmoid运算作为输出,即hθ(x) = 1 / (1 + exp(-θTx))。
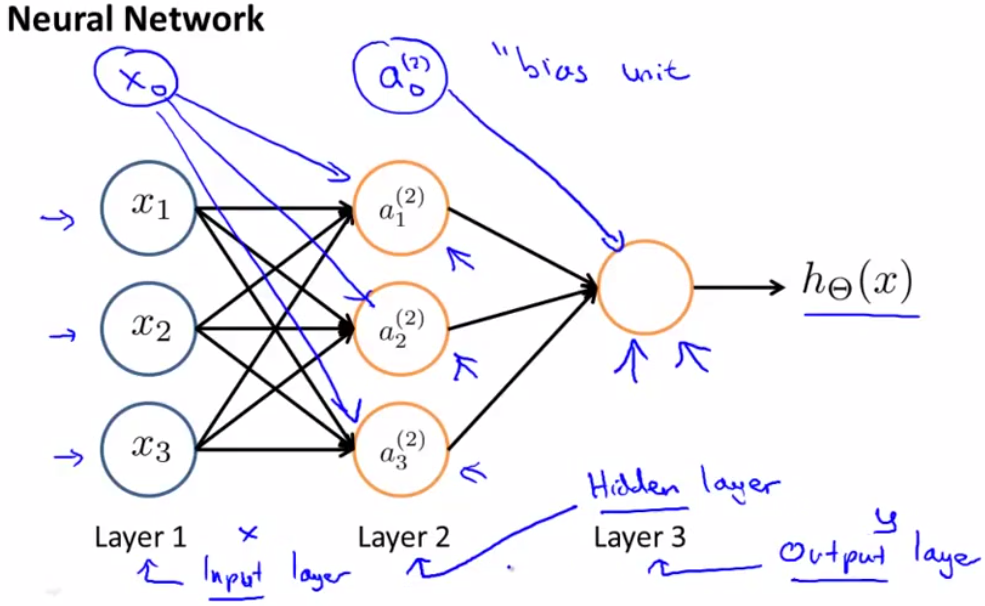
若有隐层,则为下图所示。Mathematical definition of Neutral networks。

II. Receptive Field
定义一:我们称直接或间接影响某一特定神经细胞的光感受器细胞的全体为该特定神经细胞的感受野(receptive field)。
定义二:感受器受刺激兴奋时,通过感受器官中的向心神经元将神经冲动(各种感觉信息)传到上位中枢,一个神经元所反应(支配)的刺激区域就叫做神经元的感受野(receptive field)。[6]
定义三:视觉感受野(receptive field of vision)是指视网膜上一定的区域或范围。当它受到刺激时,能激活视觉系统与这个区域有联系的各层神经细胞的活动。视网膜上的这个区域就是这些神经细胞的感受野。
III. Convolutional Neural Networks
Although deep supervised neural networks were generally found too difficult to train before the use of unsupervised pre-training, there is one notable exception: convolutional neural networks.[1]
如果BP网络中层与层之间的节点连接不再是全连接,而是局部连接的。这样,就是一种最简单的一维卷积网络。如果我们把上述这个思路扩展到二维,就是卷积神经网络。具体参看下图:[2]

对于上图中被标注为红色节点的净输入,就等于所有与红线相连接的上一层神经元节点值与红色线表示的权值之积的累加。这样的计算过程,很多书上称其为卷积。
权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性[3]。
定义:Convolutional NN’s are specialized NN architectures which incorporate knowledge about the invariances of two-dimensional (2-D) shapes by using local connection patterns and by imposing constraints on the weights [4].
优点:CNN & ordinary fully connected feedforward network [4]:
(1) 全连接的神经网络权值非常多,需要的训练集很庞大。Main deficiency of unstructured nets for image or speech applications is that they have no built-in invariance with respect to translations or local distortions of the inputs. Learning these weight configurations requires a very large number of training instances to cover the space of possible variations.
In convolutional networks, shift invariance is automatically obtained by forcing the replication of weight configurations (权值共享) across space.
(2) CNN利用了图像等的拓扑结构,即其在时域或空域的相关性。Convolutional networks force the extraction of local features by restricting the receptive fields (感受野[3]) of hidden units to be local.
原理:Convolutional networks combine three architectural ideas to ensure some degree of shift, scale, and distortion in-variance: 1) local receptive fields; 2) shared weights (or weight replication); and 3) spatial or temporal subsampling [4].
(1) local receptive fields
此为模拟人类神经网络感受野的特征,即特定的神经元的输入与视网膜上一定范围内收到的刺激有关。
同时,用local receptive fields的思想,采用上一层输入的局部范围内信号作为下一层一个神经元的输入,elementary visual features也对偏移、旋转等distortion有更好的鲁棒性。
不仅输入层,每一层都采用local receptive fields,逐层detect higher order features。
An interesting property of convolutional layers is that if the input image is shifted, the feature map output will be shifted by the same amount, but it will be left unchanged otherwise.
(2) shared weights
研究发现,对某一神经元Unit及其对应的receptive field提取特征的好用的weight vector θ和bias,对整幅图像(或整个输入Map)都是好用的,故每一个unit对应的θ和bias都是一样的。
Shared weights的所有units的输出构成一个feature map,对应的是同一类feature。同一个输入map,多组θ和bias,可以得到多个feature maps。
Weights数量减少后,也减小了training error和test error之间的gap (原理:Regulation)。
(3) spatial or temporal subsampling
Feature map中各个特征在map中的精确位置不仅没有用处,当存在distortion时,反而有不利影响。To reduce the resolution of the feature map and reduce the sensitivity of the output to shifts and distortions,将上一层feature map中2*2的receptive field 取average,再降采样,得到subsampling layer。
再对subsampling layers提取feature maps,补偿了信息的损失。
IV. Neural Networks for Deep Architectures
1. Multi-Layer Neural Networks的通用数学表达式 [1]:
除top layer外,其它layer的计算表达式b为偏移量,W为权值,tanh可换为其它saturating nonlinearities,如sigmoid。输出层top layer的h通常与训练输出y以及loss function L有关,通常对于是convex的。输出层有可能为
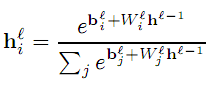
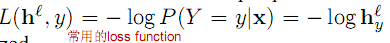
[1]Bengio Y. Learning deep architectures for AI [J]. Foundations and trends® inMachine Learning, 2009, 2(1): 1-127.
[2]http://blog.csdn.net/celerychen2009/article/details/8973218
[3]http://blog.csdn.net/zouxy09/article/details/8781543
[4]LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to documentrecognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[5]MachineLearning courses by Andrew Ng. https://class.coursera.org/ml-005/lecture/preview.8-2, 3.
[6]http://baike.baidu.com/link?url=o9_Xy1aAESz8zPWDfMNtWGUtfsK7KNY1QQXJ-cKQU7q8S8j5dWl25D2-gdIBQpiOx7KEEq0UfTLSa5Og6Ca5Na百度百科















 4936
4936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









