







 MinHash 算法由 Andrei Broder (1997) 提出的, 它是一种快速计算海量文档相似度的近似方法。开始被用在AltaVista 搜索引擎上,用于检测两个duplicate web pages, 如果两个web pages非常的像,则把这个page丢掉。Minhash也被用在lage-scale clustering 算法中。本文的结构1. 文本的Jaccard相似度;
MinHash 算法由 Andrei Broder (1997) 提出的, 它是一种快速计算海量文档相似度的近似方法。开始被用在AltaVista 搜索引擎上,用于检测两个duplicate web pages, 如果两个web pages非常的像,则把这个page丢掉。Minhash也被用在lage-scale clustering 算法中。本文的结构1. 文本的Jaccard相似度;
近日读了 Mining of Massive datasets 中 关于Finding similar items相关内容,遂将其中的MinHash算法整理如下。
MinHash 算法由 Andrei Broder (1997) 提出的, 它是一种快速计算海量文档相似度的近似方法。开始被用在AltaVista 搜索引擎上,用于检测两个duplicate web pages, 如果两个web pages非常的像,则把这个page丢掉。Minhash也被用在lage-scale clustering 算法中。
本文的结构
1. 文本的Jaccard相似度;
2. Minhash 定义,以及Minhash 和 Jaccard相似度关系;
3. 求一组文本的Minhash signature。
1. 文本Jaccard Similarity
Jaccard 是一种常用的计算文本相似度的方法,例如两篇文章S1={a, b, c, d} and S2 ={b,c,d,e}, a,...,e 表示文本的特征(例如K-shingle)。
Jaccard 相似度定义为
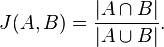
例如上例J(S1, S2) = 3/5 = 0.6
在推荐系统中 S可以表示用户, a,...,e 可以表示为购买的产品
Jaccard 可以表示两个用户的相似度。
如果有p个用户,k个产品其实可以表示为一个p*k的矩阵M 如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 172
172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









