






spark里使用scala
编者注:不要错过有关如何使用Apache Spark创建数据管道应用程序的新的免费按需培训课程-在此处了解更多信息。
这篇文章将帮助您开始在MapR沙盒上将Apache Spark GraphX和Scala一起使用。 GraphX是用于图并行计算的Apache Spark组件,它基于称为图论的数学分支建立。 它是一个位于Spark核心之上的分布式图形处理框架。
一些图形概念概述
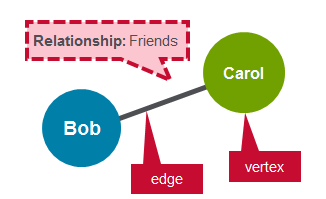
图形是用于对对象之间的关系进行建模的数学结构。 图由连接它们的顶点和边组成。 顶点是对象,边缘是它们之间的关系。
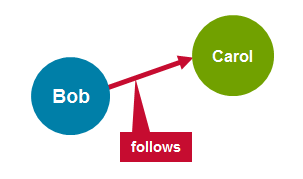
有向图是边缘具有与之关联的方向的图。 有向图的一个示例是Twitter关注者。 用户Bob可以跟随用户Carol,而并不意味着用户Carol跟随用户Bob。
正则图是每个顶点具有相同数量边的图。 常规图的一个示例是Facebook朋友。 如果Bob是Carol的朋友,那么Carol也是Bob的朋友。
GraphX属性图
GraphX通过弹性分布式属性图扩展了Spark RDD。
属性图是有向多重图,可以有多个平行的边。 每个边和顶点都有与之关联的用户定义的属性。 平行边允许相同顶点之间存在多种关系。
在本活动中,您将使用GraphX分析航班数据。
情境
作为简单的开始示例,我们将分析三个航班。 对于每个航班,我们都有以下信息:
| 始发机场 | 目的地机场 | 距离 |
| 财务总监 | ORD | 1800英里 |
| ORD | DFW> | 800英里 |
| DFW | SFO> | 1400英里 |
在这种情况下,我们将机场表示为顶点,将路线表示为边。 对于我们的图形,我们将有三个顶点,每个顶点代表一个机场。 机场之间的距离是一个路线属性,如下所示: 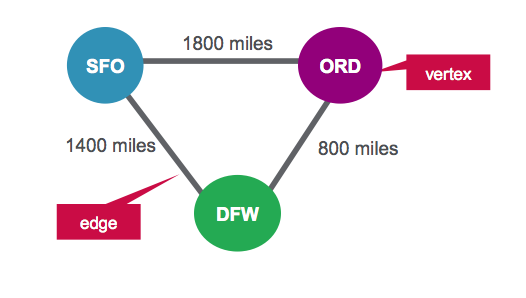
机场顶点表
| ID | 属性 |
| 1个 | 财务总监 |
| 2 | ORD |
| 3 | DFW |
路线边表
| SrcId | 目的地 | 属性 |
| 1个 | 2 | 1800 |
| 2 | 3 | 800 |
| 3 | 1个 | 1400 |
软件
本教程将在包含Spark的MapR沙盒上运行。
- 您可以从此处下载代码和数据以运行这些示例:
- 使用spark-shell命令启动后,本文中的示例可以在Spark shell中运行。
- 您还可以按照独立的应用程序运行代码,如MapR Sandbox上的Spark入门教程中所述。
启动Spark Interactive Shell
如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1878
1878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









