





在上一篇文章中 ,我使用通过Azure市场提供的模板将MapR群集部署到Azure云。 我这样做的目的是尽快建立启用Drill的群集并进入Azure。
我对Azure的强调表明,我可能正在利用Microsoft云来进行更多活动,而不仅仅是运行一个群集。 因此,尽管我将打算与Drill一起使用的大量数据加载到MapR群集的本机文件系统中,但很可能我已经将一些数据加载到其他Azure资源中,并且也想查询这些数据。 为此,我要做的就是将适当的驱动程序加载到Drill环境中,并为每个资源在群集中配置存储插件。 这是本博客文章的重点。
我的测试环境
在进入技术细节之前,重要的是要了解我为此演示配置的Azure环境。 在上一篇文章中,我对构成三节点MapR集群的资产进行了相当详细的细分。 在这里,我仅将其称为单个资源,以专注于将要集成到其中的其他Azure资产。
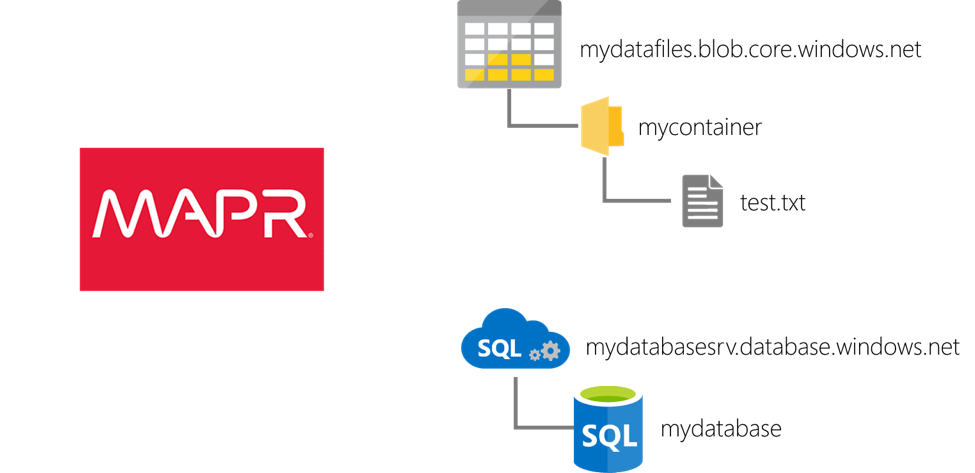
我将使用的第一个资产是Azure存储帐户。 Azure存储帐户是用于存储各种数据资产的逻辑容器。 对于此演示,我将文件存储在帐户的块Blob部分中。 块Blob是Azure存储中最便宜的存储选项,当您希望读取整个文件时(与对页面Blob类型支持的文件执行随机读取相反),它是理想的选择。
Azure存储帐户由唯一名称标识:此环境中的mydatafiles 。 因此,该帐户的块Blob部分可作为mydatafiles.blob.core.windows.net寻址。 斑点存放在容器中: mycontainer在这种环境中。 然后,在该容器中,我上传了一个由制表符分隔的名为test.txt的文件。 (如果要创建自己的环境,则存储帐户将需要使用不同的名称,但可以使用相同的容器和文件名。)
我将连接的第二个资产是Azure SQL数据库 。 Azure SQL数据库是在云中运行的Microsoft SQL Server(关系)数据库,其消除了典型数据库的大部分管理开销。 它还具有许多其他好处,使其成为Azure云中结构化数据存储的非常受欢迎的选择。
我的Azure SQL数据库名为mydatabase 。 我没有在其中创建任何对象,而是仅查询其目录中的一些预先存在的表以演示连通性。 该数据库部署在逻辑服务器的上下文中,该逻辑服务器为数据库提供了一个地址:我的环境中的mydatabasesrv.database.windows.net 。 我将服务器上的防火墙保留为默认设置,以便数据库将响应的唯一流量将是来自Azure云的流量。 (和以前一样,如果要创建自己的环境,则服务器将需要使用其他名称,但是可以使用相同的数据库名称。)
连接到Azure存储
在适当的测试环境下,我将首先将Drill连接到我的Azure存储帐户。 为此,我将首先使用在群集部署期间创建的SysAdmin用户名(默认为mapradmin )和密码(或证书)通过SSH进入群集的节点0。
注意对于此步骤序列,从节点0执行这些操作很重要。
登录后,我现在需要将两个驱动程序(即hadoop-azure和azure-storage驱动程序)下载到群集的每个节点上的/opt/mapr/drill/drill-1.6.0/jars/3rdparty/目录中。 为了解决这个问题,我将通过-a选项使用预安装在MapR集群上的clustershell实用程序 ( clush ),该选项将启动双引号括起来的命令以在集群中的所有节点上运行:
sudo clush -a "wget http://central.maven.org/maven2/org/apache/hadoop/hadoop-azure/2.7.3/had... " sudo clush -a "wget http://central.maven.org/maven2/com/microsoft/azure/azure-storage/4.4.0/... " sudo clush -a "mv *azure*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/"
有了驱动程序之后,我现在需要使用Azure存储帐户使用的密钥来配置Drill,以控制对其内容的访问。 为此,我在/opt/mapr/drill/drill-1.6.0/conf/中的core-site.xml文件的配置节点下添加以下块,用我的Azure存储帐户的名称及其密钥替换:
<property> <name>fs.azure.account.key. mydatafiles .blob.core.windows.net</name> <value> DrIhQUaOMvoydL0/+DcOuuWq8nj9TbwlLbFV4MIR7YdB1PihKQ== </value> </property>
此时,对core-site.xml文件的更改仅在节点0(我登录到的集群的节点)上进行。要将这些更改复制到集群的其余节点,我可以使用再次使用clustershell实用程序,这次使用-w选项来控制在集群的哪些节点上执行规定的操作:
sudo clush -w maprclusternode[1-2] -c /opt/mapr/drill/drill-1.6.0/conf/core-site.xml --dest /opt/mapr/drill/drill-1.6.0/conf/请注意,我已经部署了一个三节点群集。 将Clustershell配置为将这些节点识别为maprclusternode0,maprclusternode1和maprclusternode2。 更改了maprclusternode0上的core-site.xml文件后,clush仅需要针对maprclusternode [1-2]进行操作。 如果集群中的节点数不同,则需要修改分配给-w选项的值。 另外,在clustershell命令的这个实例中,我已指示clush使用SCP(即-c选项)将core-site.xml的本地副本复制到目标服务器上的适当目标位置。
注意如果在接下来的步骤中遇到问题,请尝试使用MapR仪表板(可通过TCP端口8443上的HTTPS访问)重新启动Drill服务。
有了所有驱动程序组件之后,我现在可以在Drill中创建一个存储插件来定位我的Azure存储帐户。 为此,我按照上一篇文章中的说明登录到Drill Console,然后导航到“存储”页面。
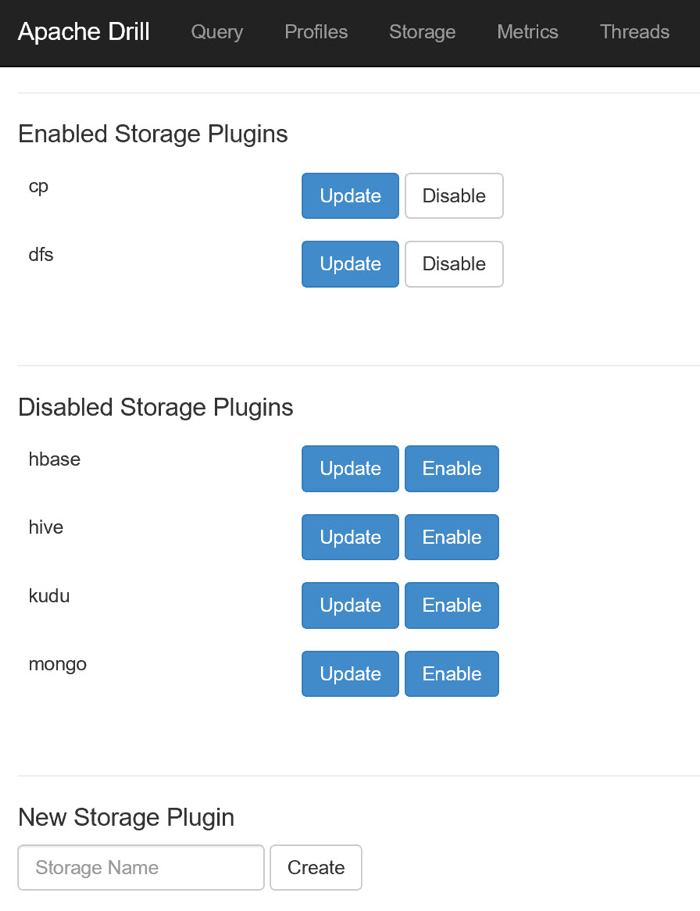
我将创建的插件配置将非常接近默认dfs插件的配置。 因此,在创建新插件之前,我单击dfs插件旁边的“更新”按钮,复制其配置信息,然后单击“上一步”按钮返回到“存储”页面。
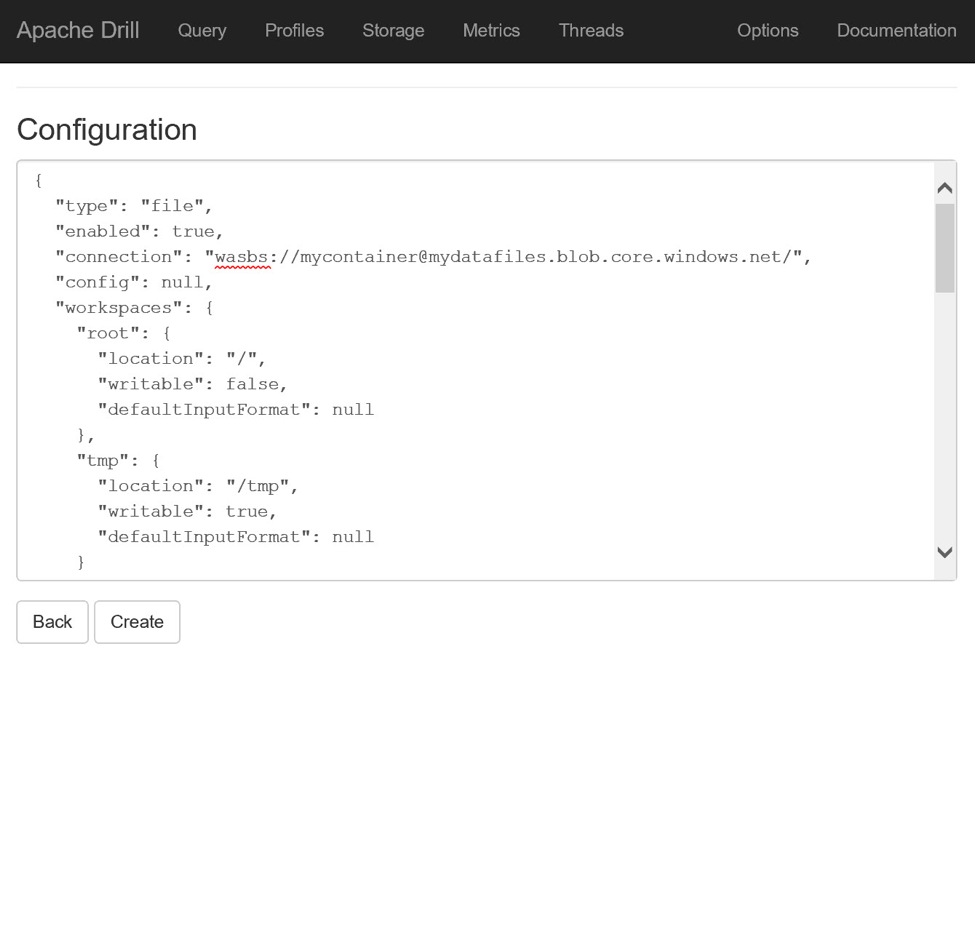
拥有dfs插件的配置信息后,在“存储”页面底部找到“新存储插件”部分,输入新插件的名称,例如mydatafiles ,然后单击“创建”按钮。 在出现的“配置”页面中,删除null关键字,并将其替换为复制的配置信息。 在配置JSON中找到连接密钥,并将其值替换为wasbs:// mycontainer@mydatafiles.blob.core.windows.net / ,并适当替换Azure存储帐户和容器名称。 (wasbs://协议指示Drill使用先前加载的驱动程序,并使它们使用HTTPS与存储帐户进行通信。)
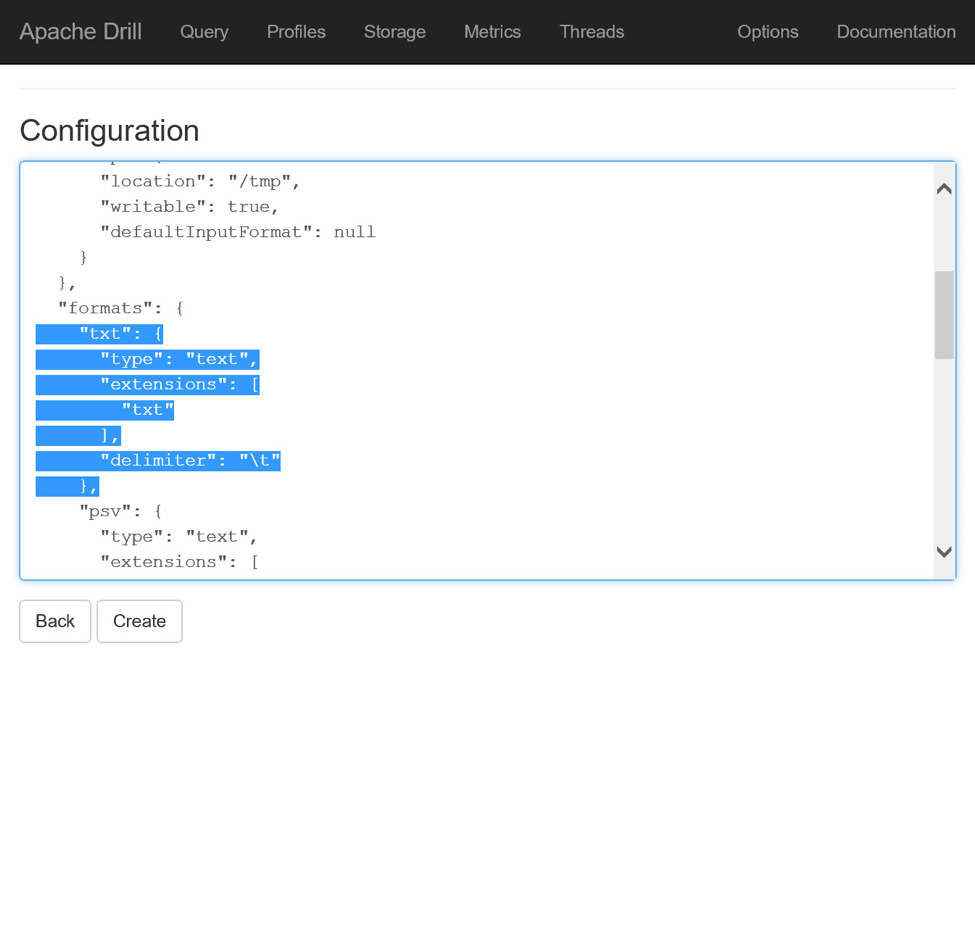
在离开此页面之前,滚动浏览配置信息,直到找到format键。 该键包含许多子键/值对,它们指示Drill如何解释特定格式的文件。 在格式下添加以下键,告诉Drill将带有txt扩展名的文件解释为制表符分隔的文本:
单击创建按钮以创建存储插件。 您应该看到指示成功的标语消息。 看到后,单击“上一步”返回到“存储”页面。 现在,您应该在页面的“启用的存储插件”部分下看到您的插件。
在安装了驱动程序并配置了插件的情况下,您可以如何查询Azure存储帐户。 导航到Drill Console的“查询”页面,并提交以下SQL查询以查看存储帐户中文件的列表:
SHOW FILES FROM `mydatafiles`;注意此查询中的插件名称以反勾号包装,通常称为重音符号。
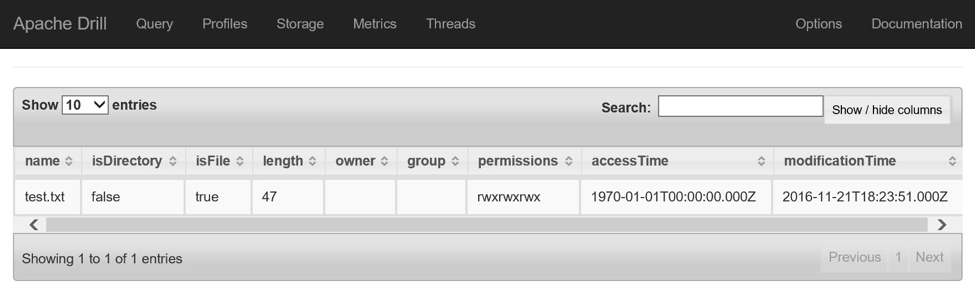
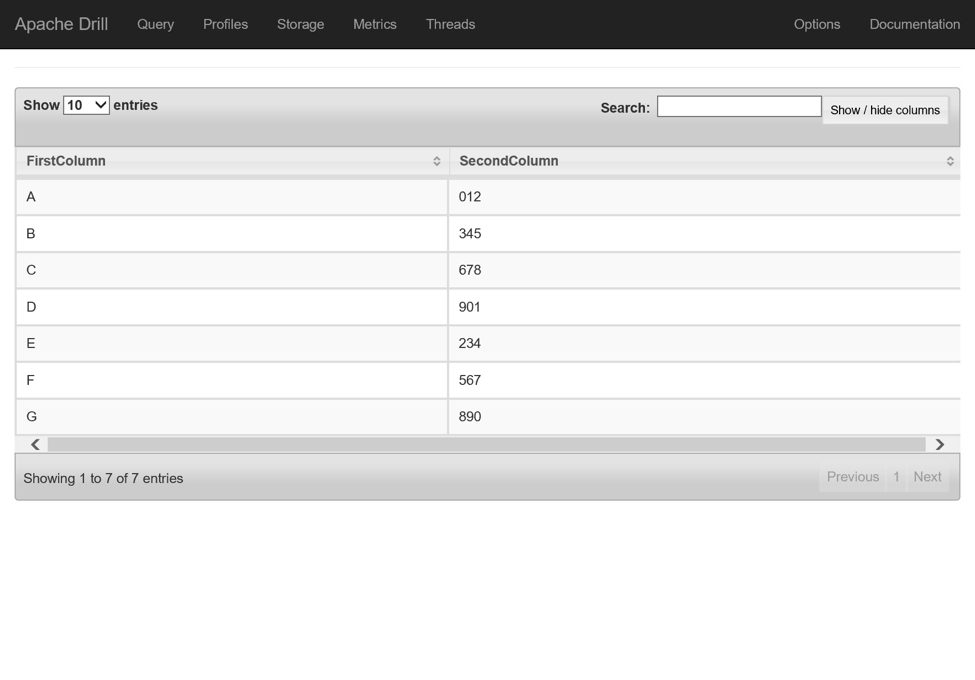
要查询加载到存储帐户中的test.txt文件,请输入以下查询:
SELECT columns[0] as FirstColumn, columns[1] as SecondColumn FROM mydatafiles.`test.txt`注意在此查询中,文件名以反引号引起来,但插件名称不需要。 有关查询文本文件的更多信息,请参阅本文档 。
连接到Azure SQL数据库
将Drill连接到Azure SQL数据库的步骤比使用Azure存储帐户执行的步骤要简单一些。 首先,我将SSH到节点0,然后使用clustershell将最新的SQL Server JDBC驱动程序下载到群集中的每个节点:
sudo clush -a "wget https://download.microsoft.com/download/0/2/A/02AAE597-3865-456C-AE7F-61... " sudo clush -a "tar -xzvf sqljdbc_6.0.7728.199_enu.tar.gz" sudo clush -a "mv sqljdbc_6.0/enu/sqljdbc*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/" sudo clush -a "rm -r sqljdbc*"
接下来,我将打开Drill控制台,导航到“存储”页面,并使用以下配置(使用服务器名称,数据库名称,用户名和密码的适当替换)创建一个新插件:
{
"type": "jdbc",
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver",
"url": "jdbc:sqlserver://mydatabasesrv.database.windows.net:1433;databaseName=mydatabase",
"username": " myusername ",
"password": " mypassword ",
"enabled": true
}
创建后(使用mydatabase的名称),我可以使用一个简单的查询来测试连接性:
SELECT * FROM mydatabase.sys.objects; 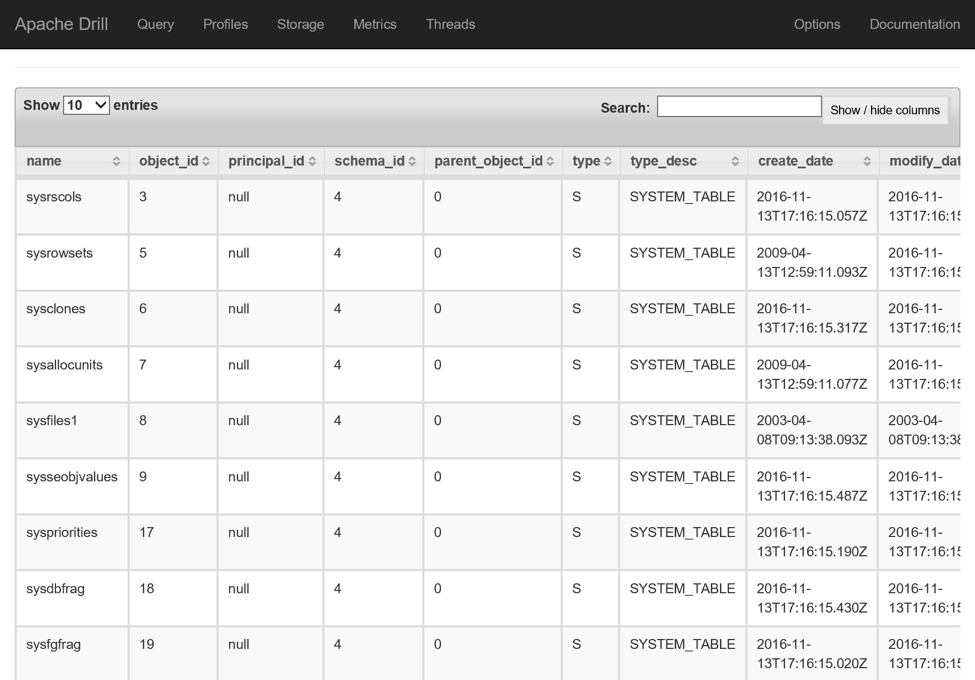
在本文中,您学习了如何使用启用Drill的群集来查询Azure存储帐户以及Azure SQL数据库。 在下一篇文章中,我们将回顾如何使用Microsoft Power BI将此群集用作数据源。















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









