





这篇博客文章介绍了在MapR集群上部署Mesos,Marathon,Docker和Spark的步骤,并使用此部署运行各种作业以及Docker容器。
这是我们将要使用的组件:
- Mesos:一个开源集群管理器。
- 马拉松:集群范围内的初始化和控制系统。
- Spark:开源集群计算框架。
- Docker:自动在软件容器内部署应用程序。
- MapR融合数据平台:将Hadoop和Spark与实时数据库功能,全局事件流和可伸缩企业存储相集成,以支持新一代大数据应用程序。
假设条件
本教程假定您已经启动了MapR 5.1.0集群并正在运行。 为了进行测试,可以将其安装在单节点环境中。 但是,在此示例中,我们将在3节点的MapR集群上部署Mesos,例如:
- Mesos主站:MAPRNODE01
- 中观奴隶:MAPRNODE02,MAPRNODE03
让我们开始吧!
先决条件
# Make sure Java 8 is installed on all the nodes in the cluster
java -version
# If Java 8 is not yet installed, install it and validate
yum install -y java-1.8.0-openjdk
java -version
# Set JAVA_HOME to Java 8 on all the nodes
echo $JAVA_HOME
# If JAVA_HOME isn't pointing towards Java 8, fix it and test again
# Please make sure that: /usr/lib/jvm/java-1.8.0-* is matching your java 8 version
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-2.b17.el7_1.x86_64/jre
# Load and validate the newly set JAVA_HOME
source /etc/profile
echo $JAVA_HOME现在,您已经设置了正确的Java版本。 让我们继续安装Mesos存储库,以便我们可以从中检索二进制文件。
安装Mesos存储库
请确保安装与您的CentOS版本匹配的正确的Mesos存储库。
# Validate your CentOS version
cat /etc/centos-release
# for CentOS 6.x
rpm -Uvh http://repos.mesosphere.com/el/6/noarch/RPMS/mesosphere-el-repo-6-2.noarch.rpm
# for CentOS 7.x
rpm -Uvh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm现在我们已经安装了Mesos存储库,是时候开始安装Mesos和Marathon了。
安装Mesos和马拉松
# On the node(s) that will be running the Mesos Master (e.g., MAPRNODE01):
yum install mapr-mesos-master mapr-mesos-marathon
# On the nodes that will be running the Mesos Slave (e.g., MAPRNODE02, MAPRNODE03):
yum install mapr-mesos-slave
# Run on all nodes to make the MapR cluster is aware of the new services
/opt/mapr/server/configure.sh -R
# Validate the Mesos Web UI to see the master and slave http://MAPRNODE01:5050从外壳启动Mesos作业
# Launch a simple Mesos job from the terminal by executing:
MASTER=$(mesos-resolve `cat /etc/mesos/zk`)
mesos-execute --master=$MASTER --name="cluster-test" --command="sleep 5"除了控制台输出之外,该控制台输出将显示正在创建的任务并将状态更改为TASK_RUNNING,然后变为TASK_FINISHED,您还应该在Mesos控制台UI的框架页面上看到一个新终止的框架: http:// MAPRNODE01:5050
使用Marathon启动Mesos作业
通过将浏览器指向http:// MAPRNODE01:8080打开Marathon,然后单击“创建应用程序”
# Create a simple app to echo out 'hello' to a file.
ID: cluster-marathon-test
CPU's: 0.1
Memory: 32
Disk space: 0
Instances: 1
Command: echo "hello" >> /tmp/output.txt
# Click "Create Application"检查Marathon控制台( http:// localhost:8080 )以查看正在部署和启动的作业:

也:
# Check the job output to see "hello" being written constantly
tail -f /tmp/output.txt通过将浏览器指向http:// localhost:5050来检查Mesos中的活动任务

最后,通过打开Marathon控制台( http:// MAPRNODE01:8080 )破坏应用程序,单击“ cluster-marathon-test”应用程序,然后从配置下拉列表中选择“ destroy”:
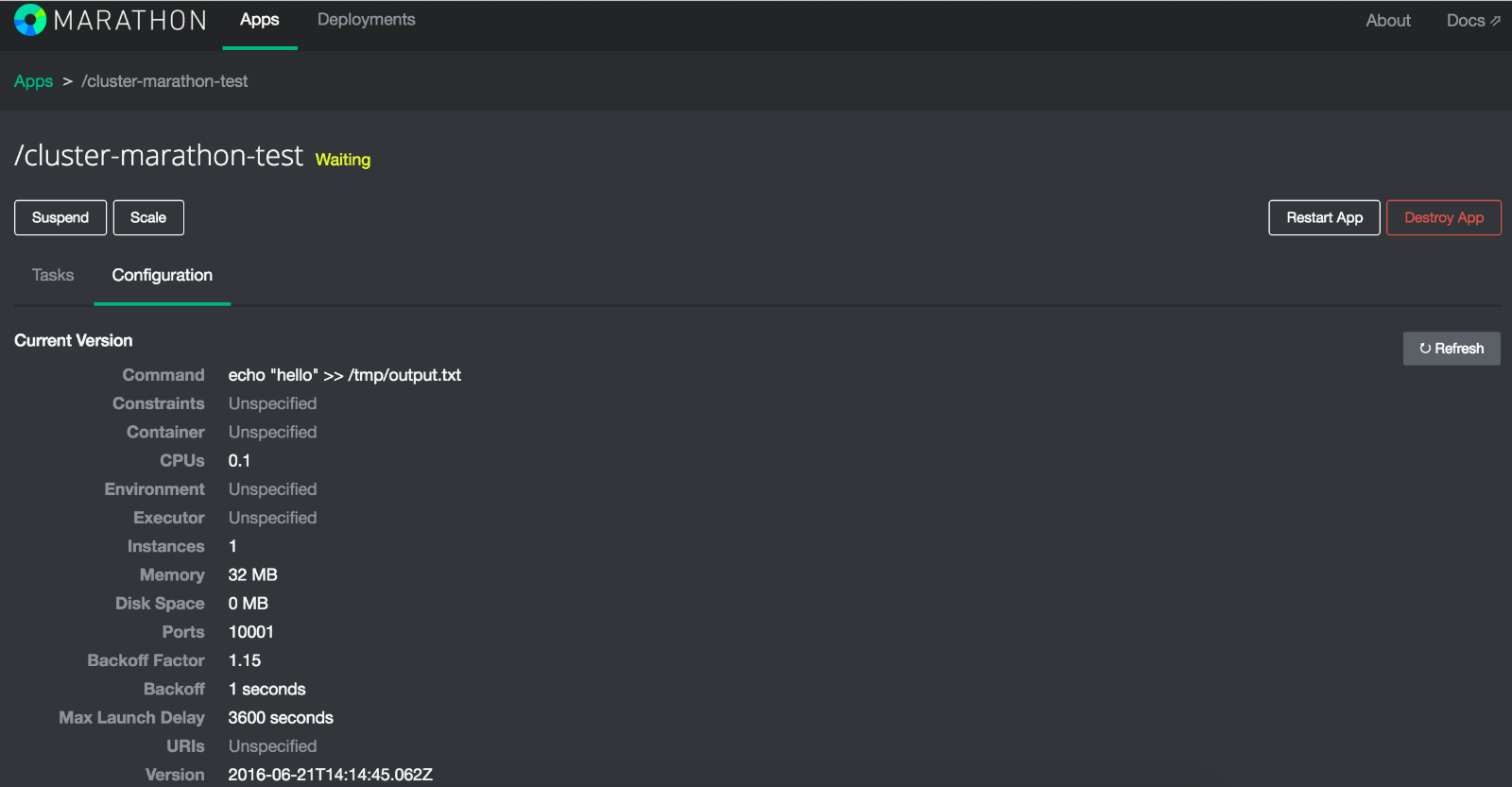
在Mesos上启动Docker容器
现在我们已经运行了Mesos,可以轻松地大规模运行Docker容器。 只需在运行Mesos Slave的所有节点上安装Docker,然后开始启动这些容器:
在所有Mesos Slave节点上安装docker
# Download and install Docker on all Mesos Slave nodes
curl -fsSL https://get.docker.com/ | sh
# Start Docker
service docker start
chkconfig docker on
# Configure Mesos Slaves to allow docker containers
# On all mesos slaves, execute:
echo 'docker,mesos' > /etc/mesos-slave/containerizers
echo '5mins' > /etc/mesos-slave/executor_registration_timeout
# Restart the mesos-slave service on all nodes using the MapR MCS现在我们已经安装了Docker,我们将使用Marathon启动一个简单的Docker容器,该容器是本示例的Httpd Web服务器容器。
# Create a JSON file with the Docker image details to be launched on Mesos using Marathon
vi /tmp/docker.json
# Add the following to the json file:
{
"id": "httpd",
"cpus": 0.2,
"mem": 32,
"disk": 0,
"instances": 1,
"constraints": [
[
"hostname",
"UNIQUE",
""
]
],
"container": {
"type": "DOCKER",
"docker": {
"image": "httpd",
"network": "BRIDGE",
"portMappings": [
{
"containerPort": 80,
"protocol": "tcp",
"name": "http"
}
]
}
}
}
# Submit the docker container using the created docker.json file to Marathon from the terminal
curl -X POST -H "Content-Type: application/json" http://MAPRNODE01:8080/v2/apps -d@/tmp/docker.json指向浏览器以打开Marathon( http:// localhost:8080 )并找到httpd Docker容器:
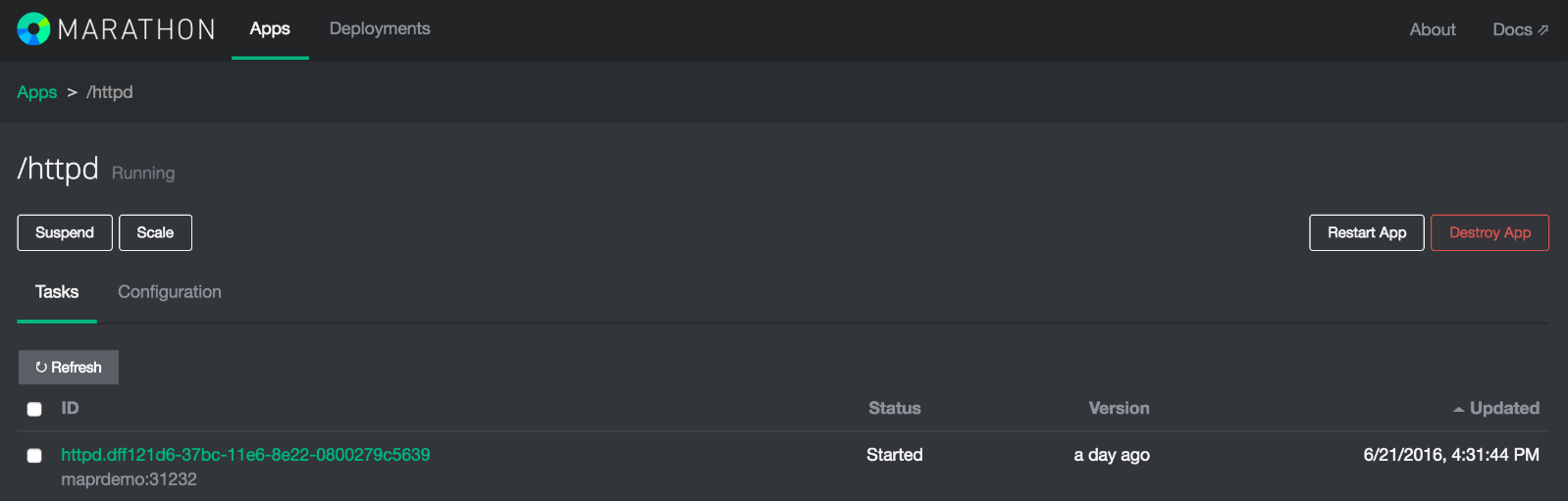
在ID字段下,Marathon将公开指向Docker容器的超链接(请注意,端口将有所不同,因为它将动态生成)。 单击它,您将连接到httpd容器:
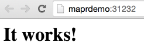
您现在已经使用Marathon在Mesos上成功启动了Docker容器。 您可以使用相同的方法在Mesos基础架构上启动任何种类的Docker容器。 此外,您可以使用MapR独特的NFS功能将Docker容器连接到MapR Converged Data Platform上的任何数据,而不必担心将在哪个物理节点上启动Docker容器。此外,如果要将您的Docker容器安全地连接到MapR-FS,强烈建议使用MapR POSIX客户端。 我在下面的社区帖子中描述了如何实现这一目标:
能够在我们的Mesos集群上启动Docker容器,让我们继续在同一基础架构上启动Spark Jobs。
在Mesos上安装并启动Spark作业
# Install Spark on the MapR node (or nodes) from which you want to submit jobs
yum install -y mapr-spark-1.6.1*
# Create the Spark Historyserver folder on the cluster
hadoop fs -mkdir /apps/spark
hadoop fs -chmod 777 /apps/spark
# Tell the cluster that new packages have been installed
/opt/mapr/server/configure.sh -R
# Download Spark 1.6.1 - Pre-built for Hadoop 2.6
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.6.1-bin-hadoop2.6.tgz
# Deploy Spark 1.6.1 on the MapR File System so Mesos can reach it from every MapR node
hadoop fs -put spark-1.6.1-bin-hadoop2.6.tgz /
# Set Spark to use Mesos as the execution framework
vi /opt/mapr/spark/spark-1.6.1/conf/spark-env.sh
# Set the following parameters, and make sure the libmesos version matches your installed version of Mesos
export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos-0.28.2.so
export SPARK_EXECUTOR_URI=hdfs:///spark-1.6.1-bin-hadoop2.6.tgz启动一个简单的spark-shell命令以在Mesos上测试Spark:
# Launch the Spark shell job using Mesos as the execution framework
/opt/mapr/spark/spark-1.6.1/bin/spark-shell --master mesos://zk://MAPRNODE01:5181/mesos
# You should now see the Spark shell as an active framework in the Mesos UI
# Execute a simple Spark job using Mesos as the execution framework
val data = 1 to 100
sc.parallelize(data).sum()使用spark-submit将Spark作业提交给Mesos:
# Run a Spark Submit example to test Spark on Mesos and MapR
/opt/mapr/spark/spark-1.6.1/bin/spark-submit \
--name SparkPiTestApp \
--master mesos://MAPRNODE01:5050 \
--driver-memory 1G \
--executor-memory 2G \
--total-executor-cores 4 \
--class org.apache.spark.examples.SparkPi \
/opt/mapr/spark/spark-1.6.1/lib/spark-examples-1.6.1-mapr-1605-hadoop2.7.0-mapr-1602.jar 10故障排除
考虑到涉及的组件数量,对Mesos,Marathon,Spark和Docker等各种组件进行故障排除以发现潜在问题可能会有些挑战。 以下是五个故障排除提示:
# 1. Marathon port number 8080
This port number might conflict with the Spark Master as this runs on the same port.
# 2. Log information
The Mesos Master and Slave nodes write their log information into on the respective nodes:
/var/log/mesos/
# 3. Marathon as well as some generic Mesos Master and Slave logging ends up in /var/log/messages
tail -f /var/log/messages
# 4. Enable extra console logging by executing the following export prior to running spark-submit on Mesos
export GLOG_v=1
# 5. Failed to recover the log: IO error
This error message may occur if you previously ran Mesos as the root user and are
now trying to run it as non-root users (for example, the mapr user).
# Full error message in /var/log/messages:
# Failed to recover the log: IO error /var/lib/mesos/replicated_log/LOCK: Permission denied
chown -R mapr:mapr /var/lib/mesos/replicated_log/结论
在此博客文章中,您学习了如何在MapR融合数据平台之上部署Mesos,Marathon,Docker和Spark。 您还使用Shell提交了各种作业,并启动了Spark作业以及Docker容器。
如果您要将Docker容器安全地连接到MapR融合数据平台,请在此处阅读我的社区文章:
如果您有任何反馈或疑问,请在下面的评论部分中发布。















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









