





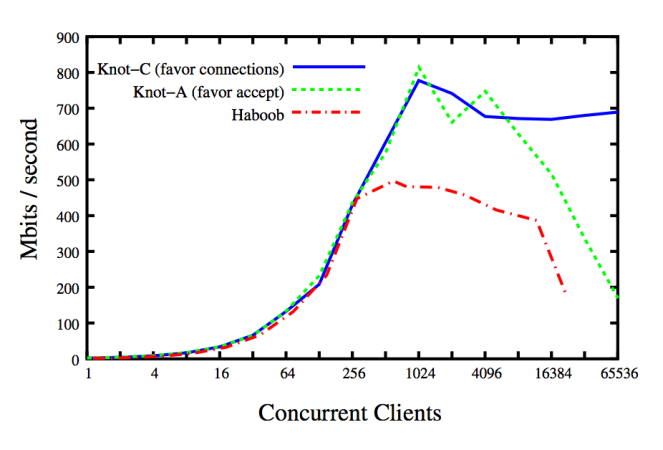
结不仅是网络服务器,而且是Haboob。 区别在于并发模型:结是基于线程的,而Haboob是基于事件的[9]。 显然,从基准测试结果来看,一旦活动的并发客户端数量变得相关,那么poll() / epoll()机制就会成为严重的瓶颈(在特定情况下,在16384个客户端上,垃圾回收几乎没有发生,基准测试无法继续进行) 。 为了清楚起见,“赞成连接”和“赞成接受”是网络服务器的两种不同的线程调度策略。
埃里克·布鲁尔(Eric Brewer)是伯克利大学的计算机科学家,他提出了著名的CAP定理[15]。 在一系列论文中,他试图揭露和解决围绕基于线程的并发及其固有可伸缩性的误解。 特别是,在两篇开创性的著作《 为什么事件不是一个好主意 》 [9]和“ Internet服务的可伸缩线程 ” [8]中,他比较了基于事件和基于线程的可伸缩服务器的性能,证明了线程模型几乎可以线性伸缩。具备操作系统(OS)功能:一旦操作系统受到硬件的反压,就会发生垃圾回收,并且会影响整体可伸缩性。 还有一点很有趣:在2003年,只有当成千上万的线程正在处理活动的网络连接时,才会发生这种破坏。 有趣,不是吗?
让我们浏览文献中的一些资源,以讨论基于线程的并发的优点,尤其是在现代硬件体系结构上。
历史药
在这些情况下,一张图片值一千字。
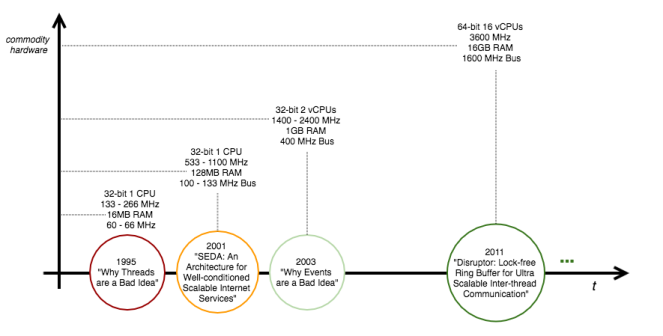
在[6]中从处理器时间轴查找硬件。 实际上,随着最近几年硬件的改进,技术趋势在于利用具有大量多线程功能的硬件并行性。 当前的努力是在针对CPU绑定的应用程序的无锁和无等待的非阻塞同步算法和数据结构[7]领域。 无锁超可伸缩数据结构的示例包括LMAX Disruptor [16](每秒2600万次操作,平均延迟为52ns )和Azul无锁Hashtable [17](每秒30至5000万次操作) 。
一些事实
从一台典型的商用计算机中可以获取一些数字,以对其内存和线程的默认限制进行基准测试。 特别是,掌握每个过程的i很有意思。 可分配的虚拟内存量; ii。 每个用户的堆栈大小iii。 最大进程数,最后是每个系统iv。 最大线程数。
# linux kernel version
[hailpam@jarvis ~]$ uname -r
3.10.0-229.11.1.el7.x86_64
# allocable virtual memory
[hailpam@jarvis ~]$ ulimit -v
unlimited
# stack size
[hailpam@jarvis ~]$ ulimit -s
8192
# maximum number of processes per user
[hailpam@jarvis ~]$ ulimit -u
4096
# maximum number of threads
[hailpam@jarvis ~]$ cat /proc/sys/kernel/threads-max
255977附带说明一下,Linux内核3.1版于2011年末发布。从数据来看,从现代Linux操作系统的系统,进程和用户角度看,实际上并不需要担心可分配给以下对象的线程数。通过利用现代硬件架构的多核功能,可以扩展到数千个活动连接[8,9]。
事件/线程二元论剖析
在设计用于现代Internet服务的可伸缩网络服务器时,总是会提出一个问题:每个连接一个线程是否足够可伸缩,还是应该采用无阻塞IO?
基于事件和线程的模型是双重的[1],这意味着使用一个模型开发的程序可以直接映射到另一个模型的程序; 两种模型在逻辑上都是等效的,即使它们使用不同的技术和构造也是如此; 由于两个模型都采用了调度技术,因此两个模型的性能实际上是相同的。
Lauer和Needham(70年代后期)的对偶论点提出了一些有趣的观点,将Event和Threads并列放置。
| 大事记 | 线程数 |
| 事件处理程序 | 监控 |
| 事件循环 | 排程 |
| 事件处理程序接受的事件类型 | 导出功能 |
| 发送回复 | 从程序返回 |
| 调度邮件,等待回复 | 执行阻止过程调用 |
| 等待消息变量 | 等待条件 |
根据对偶论证,当实现等效逻辑时, 两个模型都产生相同的阻塞点 。 说, 给定可比较的执行环境 ,这两个模型应该能够实现相同的性能。
IO与CPU并行度
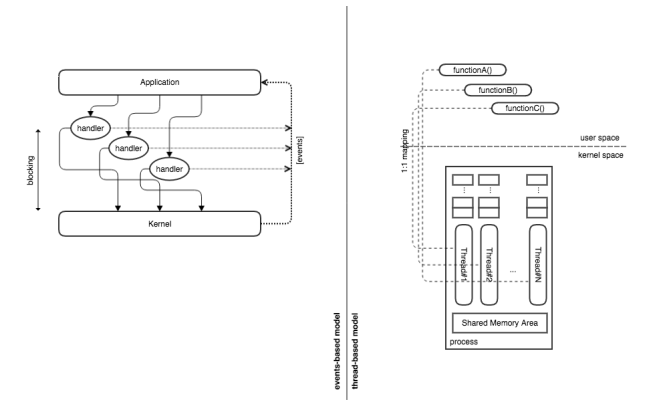
对于IO操作,可以采用两个基本模型:1.阻塞或2.非阻塞。
阻塞模型基于操作系统的功能,每当执行IO操作时,CPU便将CPU时间分配给不同的进程/线程:IO进程完成后,IO进程/线程将被挂起,新的进程/线程将被激活。发出一个信号以唤醒挂起的进程/线程,并使实际活动的线程/线程进入睡眠状态。 另一方面,非阻塞模型基于应用程序的功能,可在循环中连续轮询单个进程/线程内的IO操作状态:连续检查文件描述符状态,并且只要其中一个已被新缓冲发出进一步的调用以检索此类数据。 直观地讲,轮询策略是操作系统内核在下面用来检查设备状态的机制。 在应用程序级别具有这种机制,直观上看起来就像是一种重量级的重复工作。
注意分段事件驱动的体系结构(SEDA)[12]能够将两个并行级别组合在一起,以提供卓越的性能。
关于任务管理
可以考虑三种主要技术: 串行 , 协作和抢占式 。
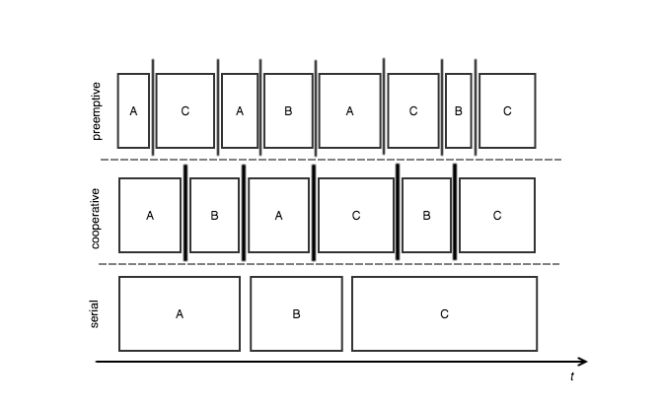
序列号 。 最简单的方法:先到先得。 任务从开始到结束依次执行。 显然,没有任务交错。
合作社 。 任务根据它们自己的时间片进行交错,这是任务执行的协作模型,因为任务是根据特定的执行时间范围分配CPU时间的:每个任务可以将CPU时间放弃给具有相同优先级的另一个任务。 如上所述,任务是交错的,但是与典型的抢先式调度相比,模式是不同的。
抢先 。 任务没有顺序执行; 它们通过指示任务何时能够执行新工作单元的信号传递机制进行交错。 它可以很容易地与基于优先级的调度逻辑相结合,因为信令机制能够中断正在运行的任务。 在这种模型中,调度程序完全控制交织策略,因此,所获得的吞吐量可能不是最佳的。
Linux内核从版本2.6.3 [4]开始采用完全公平调度(CFS)策略。 CFS调度程序采用由Red-back树支持的运行队列来最大化CPU时间分配:任务轮询是O(1)操作,任务入队是O(log N)操作,其中N是实际任务数。 这样的调度程序使用优先级优先权:有了适当的信号机制,一旦高优先级的任务进入运行队列并满足公平性,内核就可以停止正在运行的任务。
任务与堆栈管理
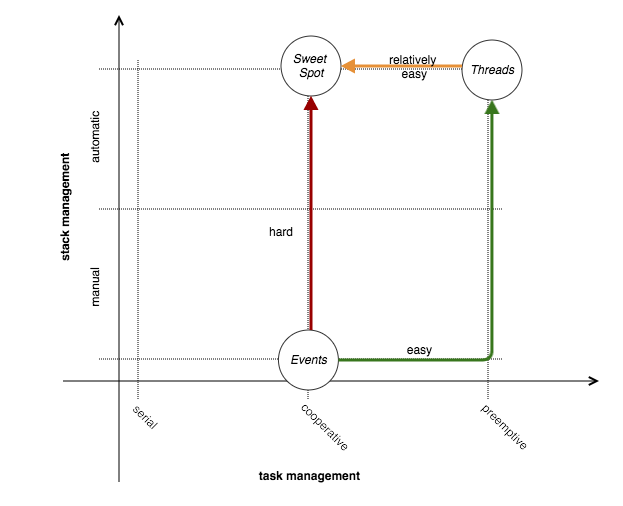
调用堆栈是编程中的基本概念,编译器采用此数据结构来保留处理上下文在子例程调用中的跳入和跳出。 另一方面,任务是任何OS的固有工作单元,实际上,甚至进程也被内核任务计划程序视为要在CPU单元上计划的许多任务。
显然,进程或线程的堆栈由内核管理,该内核通过交换此类堆栈以及一些CPU寄存器的值来交换上下文,从而谨慎地切换上下文,基于线程的并发性可从中受益。 通过事件驱动的编程,并发显然是使用一个轮询线程并从IO设备的并行性中受益的:所有事情都在应用程序中发生,因此,每个事件类的处理堆栈都应由应用代码显式管理。
事件驱动的设计实现了一种协作式任务调度的形式:特定的处理程序处理是工作单元,而处理程序之间的更新实现了调度流程。 另一方面,基于线程的设计实现了抢占式任务调度的形式,特别是这种调度完全与OS内核调度耦合。
在[5]中,对这两个模型进行了分析,目的是找到这两种方法之间的最佳结合点 :使用基于线程的并发的正确组合,同时处理无阻塞的IO,这一概念由Matt Welsh与其SEDA进行了修改[12 ]。 相同的工作[5]强调了用于处理非阻塞IO的纯基于事件的编程的内在复杂性和可扩展性限制,因此,在上图中,从“事件”到“最佳点”的路径很难。 ; 最好将目标从“线程”转移到“最佳位置”。
事件固有的复杂性
可以理解,事件引发了三个基本问题:控制反转,多核处理器和侦听器生命周期[9]。
控制反转
堆栈撕裂现象[5]:在堆上重建的堆栈。 对于不支持/不提供闭包的命令式编程语言,回调是理想的选择,因此异步回调代表基于事件的IO的设计模式:每当感兴趣的事件冒泡时,都会注册并调用回调。 回调遭受堆栈撕裂的问题,该问题包括需要将处理堆栈保存在堆栈外:一旦调用回调函数以继续IO操作,就需要重新激活上下文,以便始终如一地恢复任何操作。先前的操作。 显然,上下文必须保存在堆栈外,因为回调函数本身实际上是使用其实际参数分配到堆栈上的:调用是无状态的,在堆栈上是实际需要的数据量,通常对应到实际的输入参数值。 上下文需要保存在堆上,并作为输入参数传递给回调。 此模型非常复杂且不自然:堆栈展开应该能够为当前计算返回任何上下文,而不是回调,因为回调的本质与空间和时间处理例程无关。 关键在于操作的顺序性质,这些操作通过基于事件的方法分为连续的异步子操作。
注意封闭减轻了堆栈撕裂的问题,但就直观而言,在复杂的情况下并不能完全解决。
多核处理
事件循环中的处理程序应顺序运行,以避免破坏全局状态。 引入事件锁定将非常复杂。
侦听器生命周期
处理程序在注册之前一直存在。 如果每当事件不再发生时都不会发生注销,则该处理程序将永久存在而不会存在:它是一个泄漏,就像在内存管理中一样。
线程固有的简单性
显而易见,从工程角度来看,线程模型具有内在的简单性。 让我们讲一些基本要点。
顺序编程
根据定义,线程是执行的顺序单元。 指令在钝化和重新激活之间一个接一个地执行:任何算法都按照思想编写。
自动上下文切换
OS级别的信号处理轻量级且成本低廉的上下文切换。
编译器和操作系统支持
顺序存储器模型可以由编译器优化。 另一方面,操作系统负责处理这些轻量级进程及其资源分配的整个工作。
本机POSIX Linux线程
LinuxThreads库在历史上一直存在设计缺陷以及与POSIX标准的合规性问题。 该库基本上是通过将父进程克隆到新的可运行进程中来创建线程的。 从这里开始,不可伸缩的信令,重量级上下文切换以及PID管理等具体问题。 由IBM和Red Hat工程师组成的工作组致力于解决上述问题,并发布了高性能的POSIX兼容版本的线程库。 从Linux内核的2.6版本(2003年末)开始,集成了NPTL库,为内核提供了出色的线程管理可扩展性:优化了clone()之类的系统调用,引入了tkill()之类的系统调用来专门指示线程引入了线程ID作为处理轻量级进程标识符的机制,并引入了基于条件的锁定原语,例如futex() 。 除其他事项外,相同版本的Linux内核在进程调度方面进行了重大改进:引入了新的恒定时间调度程序,以简化NPTL集成,并利用了上述系统调用带来的更高级别的可伸缩性。
所有讨论的改进都带来了优化的,轻量级的上下文切换,这些上下文切换在共享内存的正确使用的线程以及所有其他处理程序之间。 NPTL将Linux内核推向了几乎零成本的线程管理 ,因为它为大量使用线程的应用程序(如网络服务器)提供了卓越的性能。
线程和阻塞IO
有人会说,旧的设计原理再次有意义。 随着NPTL的引入,即使在一般情况下,Brewer的结果也是有意义的,因此Linux OS也是如此。 [11]中的Paul Tyma展示了与阻塞IO和多线程相比,非阻塞IO的明显性能差距:阻塞IO的基准测试速度平均提高了25%,吞吐量提高了25%,如下图所示(感谢P泰玛也是)
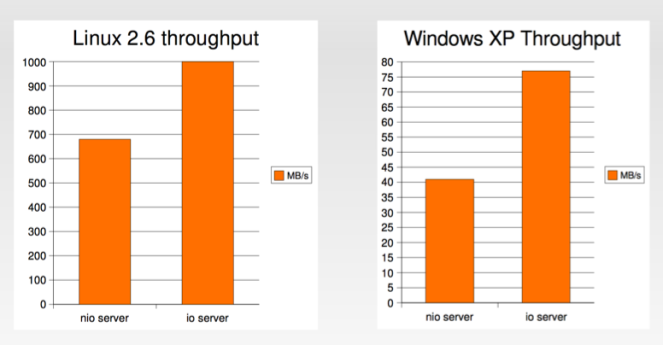
这种性能背后的原理在于事件处理的开销:重建堆栈,处理堆栈和容纳多样性是在应用程序级别几乎不会影响性能的因素。 如果想一想从文件描述符(FD)中检索数据所需的基本系统调用数(在FD列表上进行定期轮询,并在有新数据可用时进行系统检索),这一点就显而易见。 并且,另一方面,如果OS Kernels用于执行相同的操作,则应用程序不是“可比较的运行时”。
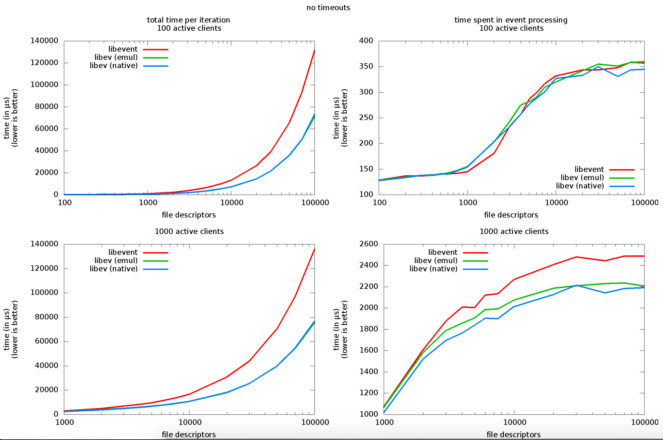
libev(用于C / C ++开发的最佳NIO库之一)的有趣基准测试[13]突出显示了该库为处理i而引入的相关开销。 插座, ii。 事件观察者和iii。 活动客户端:从1000个FD和100个活动客户端中,事件处理开销非常相关(数百微秒),并且在1000到10000之间,此类开销几乎翻了一番,几乎没有扩展性。
回顾[9]中提出的初始结果,该结果描述了基于线程的服务器胜过基于事件的服务器,并浏览了许多有趣的概念和技术,同时发现了基于事件的编程的关键问题,现在一切都应该显然,这是有道理的:对于超可扩展的网络服务器,应该采用如此复杂的SEDA体系结构来达到最佳位置,但是对于相对优异的性能,基于线程的模型就足够了。
结论
在此旅程中,出现了一些有趣的事情: i。 如果目标是操作系统驱动的可扩展性,那么对于现代硬件体系结构而言,事件是个坏主意。 从操作系统的角度来看,线程的成本几乎为零。 引用的论文和链接有助于加强一些概念,这些概念通常是误解的来源。
作为总结,以及到目前为止的叙述的总和,可以说: 基于事件的并发对我来说很难。 程序, ii。 测试和iii。 跟踪整个控制流程,而且这是处理堆栈的不自然方法(请参阅堆栈翻录[5])。 在这一点上,有人会认为基于线程的并发很难实现。 程序, ii。 测试和iii。 跟踪总体控制流程,这是一个公平的声明; 显然,与基于事件的并发相比,基于线程的方法要简单得多 ,这是驻留在操作系统驱动的策略中的原因,这些策略不必在应用程序级别进行复制(应用开销要少得多)。
此外,由于直观的,基于线程的并发与现代的多核硬件体系结构自然契合:如果设计上使用几个OS级线程,仅具有48个vCPU的商用服务器就是巨大的浪费。 你同意吗?
参考文献
[1] 关于操作系统结构的双重性 , http: //cgi.di.uoa.gr/~mema/courses/mde518/papers/lauer78.pdf [2] Threads vs Event ,弗吉尼亚理工大学, http:// courses .cs.vt.edu / cs5204 / fall09-kafura / Presentations / Threads-VS-Events.pdf [3] 线程与事件 , http: //berb.github.io/diploma-thesis/original/043_threadsevents.html [4 ] 完全公平的调度程序 ,Wikipedia, https://zh.wikipedia.org/wiki/Completely_Fair_Scheduler [5] 没有手动堆栈管理的合作任务管理 ,Usenix, http://www.stanford.edu/class/cs240/readings/usenix2002 -fibers.pdf [6] 英特尔微处理器列表 ,维基百科, https: //en.wikipedia.org/wiki/List_of_Intel_microprocessors [7] 非阻塞算法 ,维基百科, https: //en.wikipedia.org/wiki/Non -blocking_algorithm [8] 随想曲:Internet服务的可扩展线程 ,伯克利大学, http://capriccio.cs.berkeley.edu/pubs/capriccio-sosp-2003.pdf [9] 为什么事件是一个坏主意 ,伯克利大学, http://capriccio.cs.berkeley.edu/pubs/threa
DS-hotos-2003.pdf [10] 本地POSIX Linux的线程 ,草案设计, https://www.akkadia.org/drepper/nptl-design.pdf [11]数千个线程和阻塞IO,的HTTPS:// WWW .mailinator.com / tymaPaulMultithreaded.pdf [12] 状况良好的Internet服务的分段事件驱动架构 ,斯坦福大学, http://www.cs.cornell.edu/courses/cs614/2003sp/papers/Wel01.pdf [13] ] Libev Benchmark , http: //libev.schmorp.de/bench.html [14] 为什么线程是一个坏主意 ,斯坦福大学, https://web.stanford.edu/~ouster/cgi-bin/papers/threads .pdf [15] CAP定理 ,维基百科, https: //en.wikipedia.org/wiki/CAP_theorem [16] LMAX Disruptor , https: //lmax-exchange.github.io/disruptor/ [17] Azul无锁哈希表 , http: //www.azulsystems.com/events/javaone_2007/2007_LockFreeHash.pdf [18] LMAX Disruptor性能结果 , https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results
翻译自: https://www.javacodegeeks.com/2016/08/scaling-thousands-threads.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









