





 本文介绍了如何使用TF-IDF算法解决URL中的非结构化数据分类问题。通过MapReduce实现,针对URL的动态和静态部分进行区分,提高了服务匹配的准确性,减少了误分类。在实际应用中,该解决方案在不同URL设计的示例中表现出了99%以上的改进效果。
本文介绍了如何使用TF-IDF算法解决URL中的非结构化数据分类问题。通过MapReduce实现,针对URL的动态和静态部分进行区分,提高了服务匹配的准确性,减少了误分类。在实际应用中,该解决方案在不同URL设计的示例中表现出了99%以上的改进效果。
在这篇文章中,我将分享我对URL中的非结构化数据进行分类的经验。 我最终使用TF-IDF算法解决了手头的问题,并认为分享这些经验会很有趣。
这篇文章仅专注于解决问题,但是由于所使用的上下文与Plumbr有关,因此首先为不熟悉Plumbr的读者提供一些背景知识:
- Plumbr监视最终用户与应用程序的交互 。 每个这样的交互称为交易
- 事务 按消耗的实际端点分组在一起 。 例如,如果用户单击Web应用程序中的“添加到购物车”按钮,则从此类URL中提取的端点可能是“ / cart / add / {item}”。 这些端点称为 服务 。
对于使用特定服务的事务失败或速度慢于预期的情况,Plumbr还会在源代码中公开根本原因。 作为Plumbr用户的主要利益,该产品的这一部分与本文内容无关。 因此,请不要忘记此功能。
作为完整的披露:该职位是对我最近毕业的硕士论文的总结。 科学 塔尔图大学研究所 。 除了在大学里攻读学位外,我还是Plumbr工程团队的一员,所以我将自己的工作和研究联系在一起在这两个方面都受益是很自然的。
问题
我解决的问题与使交易与实际服务匹配有关。 为了理解当前的问题,让我们看一个例子。
让我们拥有一个Web应用程序,最终用户可以通过http://www.example.com上的传统HTTP GET / POST方法访问该应用程序。 达到此应用程序的实际交易可能如下所示:
- http://www.example.com/invoices/12345?action=pay
- http://www.example.com/invoices/98765?action=pay
- http://www.example.com/invoices/search?from=01-01-2015
- http://www.example.com/invoices/search?from=01-01-2015&to=31-01-2015
对于人类读者来说,很明显,上述四个事务正在访问两个不同的服务。 前两个交易是对发票“ 12345”和“ 98765”的付款尝试,后两个交易是在特定时间范围内搜索发票。
现在眼前的问题正盯着我们。 由于URL中特定资源或参数的标识符趋向于更改,因此仅应用字符串比较的简单方法会使我们无法使用最简单的应用程序。
为了确定是否确实如此,我确实对来自Plumbr的实际生产部署的数据集进行了测试。 该测试通过受监视的应用程序将幼稚的交易分组应用于服务。
结果清楚地证实了我的假设,因为39.5%的应用程序最终检测到5,000多个服务。 在11.6%的应用程序中,服务数量超过50,000。
这证实了我们的期望。 在他们的头脑中,没有人会考虑将500个不同的功能耦合到一个应用程序中,更不用说将5,000或50,000耦合在一起了。
解决方案
确认存在问题后,我现在必须确保只要事务在URL中具有动态部分(例如参数或资源标识符),我们就能够从URL中识别动态部分并将事务正确分组。
因此,即将进行的数据分析的需求可以汇总为:
- 区分URL中的“动态”和“静态”部分。
- 通过从URL中删除动态部分来规范化URL。
- 从规范化的URL生成服务名称,该名称仍具有足够的语义供人类理解实际的服务。
- 生成将服务的URL分组的正则表达式。
准备数据
在描述实际使用的算法之前,让我们探讨在进行实际分析之前需要解决的挑战之一。 要开始从URL识别动态和静态部分,我们需要标记URL。 然后,可以使用标记化URL来比较URL的每个部分,同时识别动态和静态部分。
一开始似乎很容易。 在每个正斜杠和&符上标记化的简单方法显然是不够的,因为数据集中只有不到一半的应用程序仅使用斜杠和&符来格式化URL。 其余一半的应用程序使用了完全不同的方法。 为了让您有个想法,请看以下从真实数据集派生的示例:
- http://www.example.com/invoices.pay.12345
- http://www.example.com/invoices-pay-12345
- http://www.example.com/invoices/pay&id=12345
显然,尽管REST标准很流行,但URL设计是特定于应用程序的,不能保证适用于一个应用程序的特征对于另一应用程序将是相同的。
因此,我最终从访问的数据中提取了一组已知的定界符,并运行了为每个应用程序选择正确定界符的算法。 选择标准基于对90%以上的案例中出现的定界符进行选择,以进行后续分析。
选择算法
现在已经对URL进行了标记,我们需要一种对完全非结构化和不可预测的数据执行分类的方法。 这种分类将为我们建立动态/静态令牌检测的基础。 将任务分类提炼后,选择的算法相当简单。 我使用MapReduce编程模型实现了一种流行的文本挖掘和信息检索算法,称为TF-IDF 。
TF-IDF是两种统计技术的组合,TF –术语频率和IDF –反向文档频率。 TF-IDF分数的主要好处是,其值会随着单词在文档中出现的次数增加而增加,但会因文档集合中单词的出现而被抵消。 这有助于确认以下事实:在我们案例的URL部分中,某些单词出现的频率更高。 TF和IDF有许多变体,但分数计算技术不同。 图1和2( 由Wikimedia提供 )分别说明了TF和IDF分数计算的几种改编。


就此博客帖子而言,我们应将URL视为没有任何预定义结构的文本文档。 为了获得更好的说明,让我们分析书籍的文本挖掘案例。 假设我们要查找10本书中最重要的单词的列表,这样当我键入某些单词时,我想选择该单词似乎最“相关”的书。 例如,如果我写“ gunslinger”一词,我想看看斯蒂芬·金(Stephen King)的《 黑暗塔:枪手》 。
对于这种情况,我们要排除常用的词,例如:“和”,“或”,“具有”等。我们可以通过使用原始频率公式和反向文档频率来计算术语频率来完成此任务。 我们唯一需要的是单词分隔符,据我们在书中所知道的,通常是空格。
如果计算出的分数接近于0,则意味着给定单词在书中很少见,这意味着可以将其标记为特定于书。 另一方面,高分表明在大多数书籍中都观察到所选单词。 通常,诸如“ and”,“ or”,“ with”之类的词具有较高的TF-IDF分数。
因此,我们可以考虑在单个应用程序中以相同方式使用不同URL的事务。 考虑到我们已经确定了定界符的事实,我们可以为任何应用程序为URL的每个部分计算TF-IDF得分,并将得分值交给我们。 基于此值,我们可以将URL部分分类为动态或静态。
TF-IDF使用MapReduce
多年来, MapReduce编程模型证明了其在文本挖掘,信息检索和其他各种大数据处理任务中的效率。 该模型受到几乎在任何功能编程语言中普遍使用的地图和折叠功能的影响。 MapReduce编程模型基于键值对,其中map生成特定键的值,而相同键的值分配给相同的reducer。 但是在探讨MapReduce实现细节之前,我们需要看一下map和fold函数在函数式编程中的外观。
Map将给定功能应用于列表的每个元素,并提供修改后的列表作为输出。
map f lst: (’a -> ’b) -> (’a list) -> (’b list)折叠将给定的功能应用于列表中的一个元素和累加器(必须预先设置累加器的初始值)。 之后,将结果存储在累加器中,并对列表中的每个元素重复此操作。
fold f acc lst: (acc -> ’a -> acc) -> acc -> (’a list) -> acc让我们看一下使用map和fold函数的squre示例的简单总和。 如前所述,Map将给定功能应用于列表的每个元素,并为我们提供了修改后的列表。 对于上述任务,我们有一个整数列表,我们希望每个数字都为2的幂。 所以我们的地图函数看起来像这样:
(map (lambda (x) (* x x))
'(1 2 3 4 5))
→ '(1 4 9 16 25)至于Fold,由于我们要有元素的总和,因此需要将累加器的初始值设置为0,然后可以将+作为函数传递。
(fold (+) 0 '(1 2 3 4 5)) → 15地图和折叠的平方和的组合看起来像这样:
(define (sum-of-squares v)
(fold (+) 0 (map (lambda (x) (* x x)) v)))
(sum-of-squares '(1 2 3 4 5)) → 55如果我们考虑对URL进行TF-IDF计算,则需要为每个URL应用给定函数,并使用MapReduce通过预定义的公式折叠计算结果。 为了计算术语频率和逆文档频率,我们需要为几个中间步骤生成数据,例如每个URL中的单词计数,URL集合中的单词总数等。
因此,就算法设计和实现而言,在单个MapReduce任务中计算所有内容可能会不堪重负。 为了解决这个问题,我们可以将任务分为四个相互依赖的MapReduce迭代,这将使我们有可能对数据集进行逐步分析,并且在最终迭代期间,我们将有可能为数据集中的每个URL部分计算得分。
第一次MapReduce迭代
在第一次MapReduce迭代期间,我们需要将每个URL分成多个部分并分别输出每个URL部分,其中URL标识符和部分本身将被定义为键。 这将使简化程序有可能计算出数据集中特定URL部分的总数。
实现将类似于:
地图 :
- 输入:(原始URL)
- 功能:将URL分成多个部分,然后输出每个字符。
- 输出:(urlPart; urlCollectionId,1)
减少 :
- 输入:(urlPart; urlCollectionId,[counts])
- 功能:将所有计数总和为n
- 输出:(urlPart; urlCollectionId,n)
第二次MapReduce迭代
对于第二次迭代,映射函数的输入是第一次迭代的输出。 map函数的目的是修改第一次迭代的键值,以便我们可以收集每个URL部分出现在给定集合中的次数。 这将使简化器有可能计算每个集合中的总项数。
该实现大致如下:
地图 :
- 输入–(urlPart; urlCollectionId,n)
- 功能–我们需要将键更改为仅集合标识符,然后将URL部件名称移到值字段中。
- 输出–(urlCollectionId,urlPart; n)
减少 :
- 输入–(urlCollectionId,[urlPart; n])
- 功能–我们需要将URL集合中的所有n求和为N,然后再次输出每个URL部分。
- 输出–(urlPart; urlCollectionId,n; N)
第三MapReduce迭代
第三次迭代的目标是计算集合中URL的部分频率。 为此,我们需要将具体URL部分的计算数据发送到reducer,因此map函数应将urlCollectionId移动到value字段,并且键应仅包含urlPart值。 经过这样的修改,reducer可以计算urlPart在不同集合中出现了多少次。
实现将类似于:
地图 :
- 输入–(urlPart; urlCollectionId,n; N)
- 功能–将urlCollectionId移至值字段
- 输出–(urlPart,urlCollectionId; n; N; 1)
减少 :
- 输入–(urlPart,[urlCollectionId; n; N; 1])
- 函数–将集合中urlPart的总数计算为m 。 将urlCollectionId返回到关键字段
- 输出–(urlPart; urlCollectionId,n; N; m)
第四次MapReduce迭代
此时,我们将拥有所有必需的数据来计算每个URL部分的术语频率和反转文档频率,例如:
- n –给定URL部分出现在集合中的次数
- N –不同URL集合中给定URL部分的出现次数。
- m –集合中URL部分的总数。
对于TF,我们将使用以下公式:
![]()
其中f表示给定单词在文档中出现的次数。 现在,我们可以使用以下公式计算逆文档频率:
![]()
其中N是文档总数, n t是文档中的术语数。 我们不需要在最后阶段使用reduce函数,因为对给定集合中的每个URL部分都进行了TF-IDF计算。
实现应如下所示:
地图 :
- 输入 –(urlPart; urlCollectionId,n; N; m)
- 函数 –根据n; N; m和D计算TF-IDF。其中D是URL集合的总数。
![]()
- 输出 –(urlPart; urlCollectionId,score)
结果
为了让您了解所选择的方法是否真的有效,让我们看两个URL设计完全不同的示例。 帐户A使用“。” 作为分隔符和帐户B –“ /”。 在两种情况下,幼稚方法检测到的服务数量都不好:帐户A中有105,000个服务,帐户B中有275,000个服务。
该解决方案能够成功检测每个帐户的分隔符,并为每个URL部分计算TF-IDF分数。 标识的动态零件已替换为静态内容,类似于以下示例:
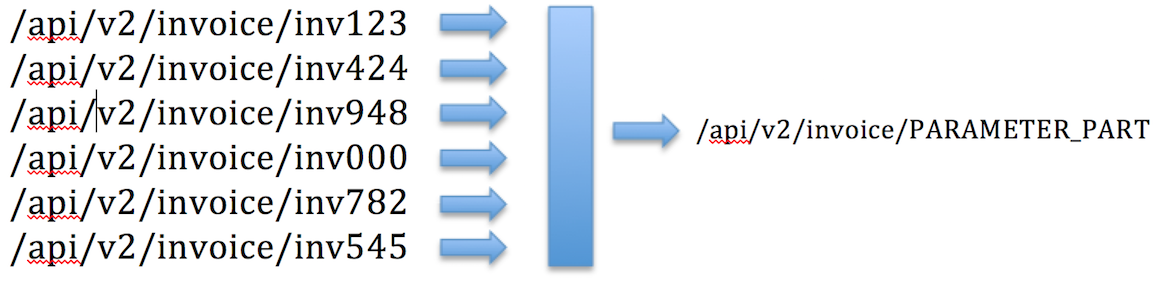
两个帐户的分类改进了99%以上,因此帐户A的服务仅为320,帐户B的服务为195。
结果的质量也得到了实际应用程序所有者的确认,因此在两种情况下,使用的方法都非常有效。
结束语
公平地说,当前的Plumbr并不像本文的简介部分中所述将其当前的服务检测基于纯字符串比较。 相反,它应用了许多不同的技术来缓解该问题。 这些包括特定于框架的(Spring MVC,Struts,JSF等)服务检测和模式匹配,以实现简单的重复令牌。
但是,我从描述的算法中收到的结果证明了该算法的实际部署。 我已经在7月开始将这种方法嵌入到我们实际的产品部署中。
翻译自: https://www.javacodegeeks.com/2016/07/applying-tf-idf-algorithm-practice.html















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









