





在这篇文章中,我们将讨论构建用于信用卡欺诈检测的实时解决方案。
实时欺诈检测分为两个阶段。 第一阶段涉及对历史数据进行分析和取证,以构建机器学习模型,该模型可用于生产中以对现场事件进行预测。
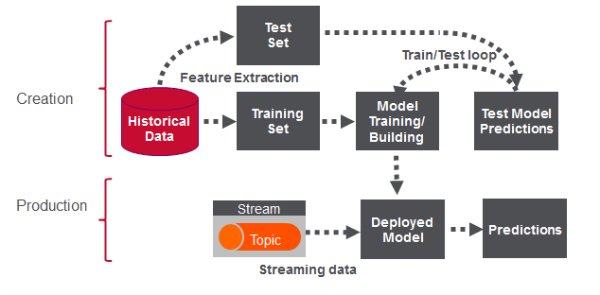
建立模型
分类
分类是一类有监督的机器学习算法,该算法基于已知项目的标记示例(例如,已知交易为欺诈或非交易)来识别项目所属的类别(例如,交易是否为欺诈)。 分类采用具有已知标签和预定功能的一组数据,并学习如何基于该信息对新记录进行标签。 功能就是您提出的“如果有问题”。 标签是这些问题的答案。 在下面的示例中,如果它走路,游泳和像鸭子一样嘎嘎叫,则标签为“鸭子”。

让我们来看一个汽车保险欺诈的例子:
- 我们要预测什么?
- 这是标签:欺诈金额
- 您可以用来预测的“如果有问题”或属性是什么?
- 这些是功能,要构建分类器模型,请提取最有助于分类的感兴趣功能。
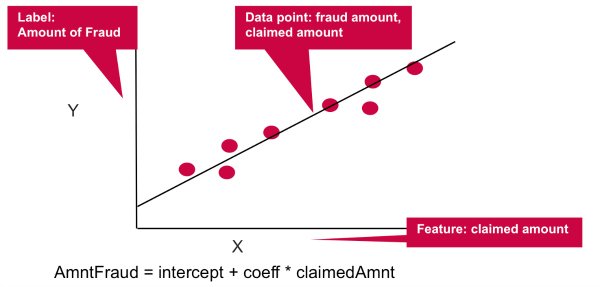
线性回归模型对Y“标签”和X“特征”之间的关系进行建模,在这种情况下,是欺诈量与索赔额之间的关系。 该系数用于衡量特征,要求的数量,标签上的欺诈量的影响。
多元线性回归对两个或多个“特征”与响应“标签”之间的关系进行建模。 例如,如果我们要对欺诈量与索赔人年龄,索赔额和事故严重性之间的关系进行建模,则多元线性回归函数应如下所示:
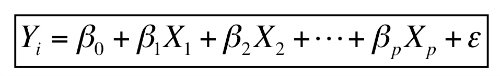
AmntFraud =截距+ coeff1 *年龄+ coeff2 *声明的Amnt + coeff3 *严重性+错误。
系数衡量每个功能对欺诈量的影响。
让我们以信用卡欺诈为例:
- 示例功能:交易金额,商户类型,距上次交易的距离和时间。
- 示例标签:欺诈可能性
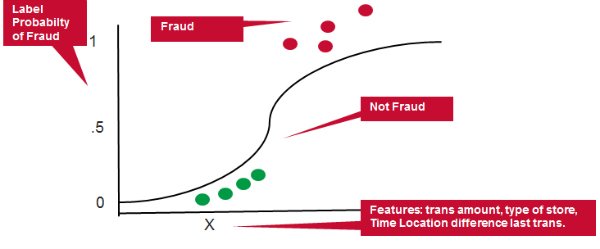
Logistic回归通过使用Logistic函数估计概率来测量Y“标签”和X“特征”之间的关系。 该模型预测用于预测标签类别的概率。
- 分类:确定哪个类别(例如欺诈或非欺诈)
- 线性回归:预测价值(例如欺诈金额)
- Logistic回归:预测概率(例如欺诈概率)
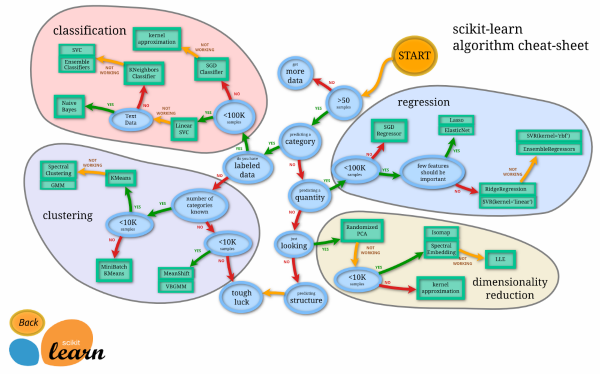
线性回归和逻辑回归只是机器学习中使用的几种算法,本备忘单中还显示了更多算法。
特征工程
特征工程是将原始数据转换为机器学习算法的输入的过程。 功能工程在很大程度上取决于用例的类型和潜在的数据源。
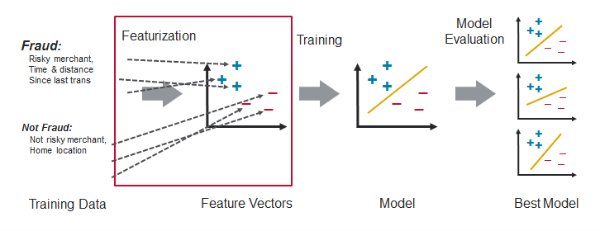
(参考Learning Spark )
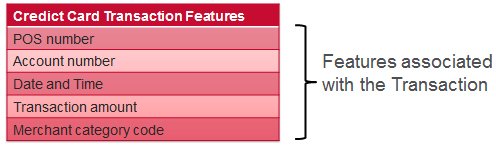
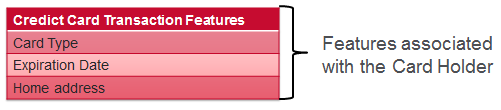
深入研究功能工程的信用卡欺诈示例,我们的目标是将普通卡使用与欺诈卡使用区分开。
- 目标:我们正在寻找使用持卡人而非持卡人的人
- 策略:我们要设计功能来衡量近期和历史活动之间的差异。
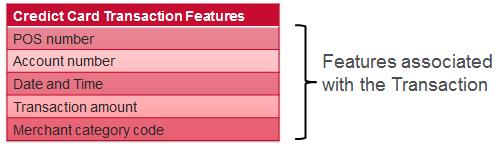
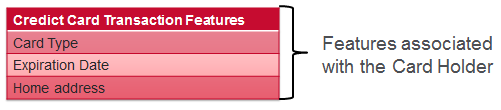
对于信用卡交易,我们具有与交易关联的功能,与持卡人关联的功能以及从交易历史记录导出的功能。 每个示例的一些示例如下所示:

模型构建工作流程
典型的监督式机器学习工作流程包括以下步骤:
- 特征工程可将历史数据转换为用于机器学习算法的特征和标签输入。
- 将数据分为两部分,一部分用于构建模型,另一部分用于测试模型。
- 使用训练功能和标签构建模型
- 使用测试功能测试模型以获取预测。 将测试预测与测试标签进行比较。
- 循环直到对模型精度满意为止:
- 调整模型拟合参数,然后重复测试。
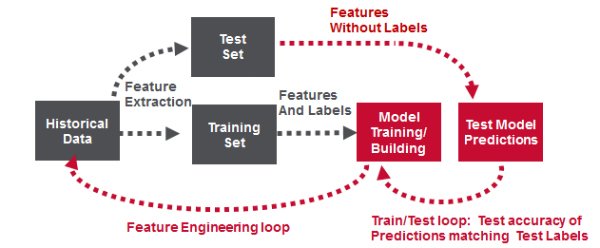
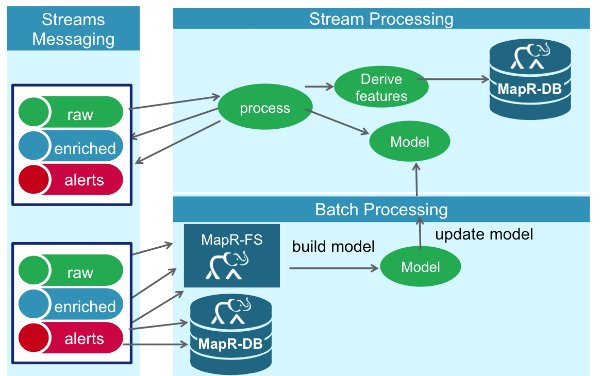
生产中的读取时间欺诈检测解决方案
下图显示了实时欺诈检测解决方案的高级架构,该解决方案具有大规模的高性能。 信用卡交易事件是通过支持Kafka .09 API的MapR Streams消息传递系统传递的。 使用已部署模型的Spark Machine Learning,通过Spark Streaming处理并检查事件是否存在欺诈。 支持posix NFS API和HDFS API的MapR-FS用于存储事件数据。 MapR-DB是支持HBase API的NoSql数据库,用于存储和提供对信用卡持有人资料的快速访问。
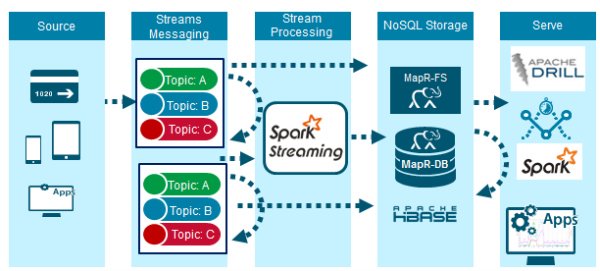
流式数据提取
MapR Streams是一个新的分布式消息传递系统,它使生产者和消费者可以通过Apache Kafka 0.9 API实时交换事件。 MapR Streams主题是消息的逻辑集合,这些消息将事件分类。 在此解决方案中,分为3类:
- Raw Trans:原始信用卡交易事件。
- 充实:信用卡交易事件充实了持卡人的功能,这些功能预计不会欺诈。
- 欺诈警报:信用卡交易事件充实了持卡人的功能,这些功能被认为是欺诈行为。
主题进行了分区,从而将并行消息传递的负载分散在多个服务器上,从而提供了更快的吞吐量和可伸缩性。
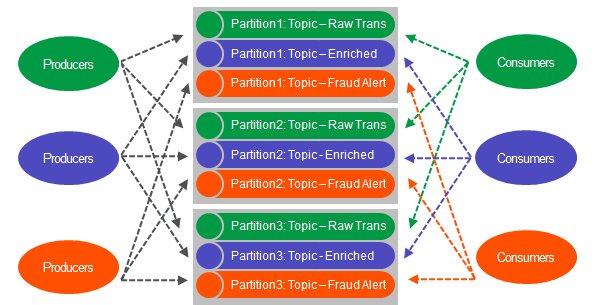
使用Spark Streaming的实时欺诈预测
Spark Streaming使您可以使用相同的Spark API进行流处理和批处理,这意味着为脱机机器学习编写的模块化模块化Spark函数可以重新用于实时机器学习。
使用Spark Streaming进行实时欺诈检测的数据流如下:

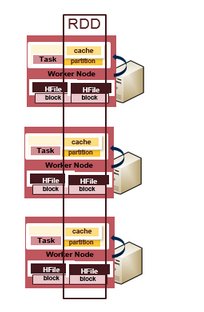
1)原始事件作为DStreams进入Spark Streaming,DStreams内部是RDD序列。 RDD类似于Java集合,只是RDD中包含的数据元素在整个集群中进行了分区。 RDD操作是对内存中缓存的数据并行执行的,这使得机器学习中经常使用的迭代算法可以更快地处理大量数据。
2)解析信用卡交易数据以获得与交易关联的功能。
3)使用帐号作为行键从MapR-DB中读取持卡人功能和个人资料历史记录。
4)使用最新的交易数据重新计算某些衍生特征。

5)使用模型算法运行特征以产生欺诈预测分数。
6)将丰富的派生功能的非欺诈事件发布到丰富的主题。 具有派生功能的欺诈事件将发布到欺诈主题。
信用卡活动的存储
阅读时不会从主题中删除消息,并且主题可以具有多个不同的使用者,这允许不同的使用者出于不同的目的处理相同的消息。
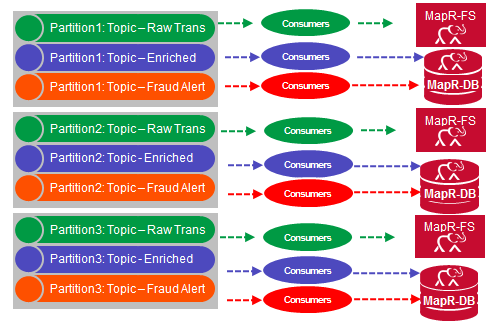
在此解决方案中,MapR Streams使用者读取并存储所有原始事件,丰富的事件和警报,并将其存储到MapR-FS,以进行将来的分析,模型训练和更新。 MapR Streams消费者阅读丰富的事件和警报以更新MapR-DB中的持卡人功能。 警报事件还用于实时更新仪表板。
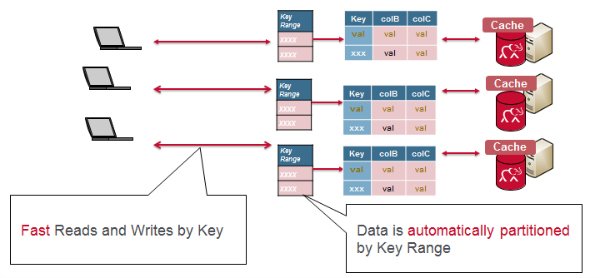
使用MapR-DB快速读写
使用MapR-DB(HBase API),可以通过键范围在群集中自动对表进行分区,并且每个服务器都是表子集的源。 按键范围对数据进行分组可提供真正快速的按行键读写。
同样,对于MapR-DB,表的每个分区子集或区域都有一个读写缓存。 内存中有最近读取或写入的数据以及缓存的列族; 所有这些都提供了真正的快速读写。
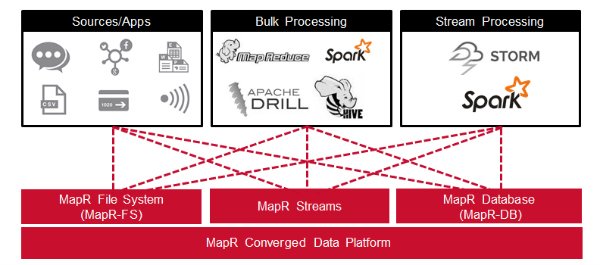
我们刚才讨论的用例体系结构的所有组件都可以与MapR融合数据平台一起在同一集群上运行。 将MapR流与所有其他组件放在同一群集上有几个优点。 例如,仅维护一个集群就意味着更少的基础架构来进行配置,管理和监视。 同样,在同一群集上具有生产者和使用者意味着与群集之间以及应用程序之间复制和移动数据有关的延迟更少。
摘要
在此博客文章中,您了解了MapR融合数据平台如何将Hadoop和Spark与实时数据库功能,全局事件流和可伸缩企业存储集成在一起。















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









