





编者注:如果您想了解有关使用Spark的更多信息,则可以免费获得一本名为《 Apache Spark入门:从开始到生产》的书 。
如果您正在考虑使用大数据,您可能想知道应该使用哪些工具。 如果尝试启用Hadoop上的SQL,则可能正在考虑使用Apache Spark或Apache Drill。 尽管这两个都是具有使用Hadoop处理数据能力的出色项目,但它们都有两个截然不同的目标。 这两个项目都执行分布式数据处理,但是它们彼此之间有很大的不同。 为工作选择合适的工具是一项重要的任务。
项目目标
这两个项目之间有些相似之处。 Apache Drill和Apache Spark都是支持Hadoop的分布式计算引擎。 他们俩的进入门槛都很低。 两者都是开源的,都不需要Hadoop集群即可开始使用。 真正需要的只是一台个人计算机。 可以将它们下载到任何台式机操作系统(包括Windows,Mac OS X或Linux)上,也可以在虚拟机中运行,以避免使系统混乱。 Spark包含许多子项目,与Drill直接比较的部分是SparkSQL 。
SQL的不同方法反映了两个项目在设计理念上的主要差异。 Drill从根本上说是一个ANSI SQL:2003查询引擎,尽管它功能强大到令人难以置信。 编写您的查询,它们将针对数据源运行,无论该数据源是您计算机上的文件,Hadoop集群还是NoSQL数据库 。 另一方面,Spark是碰巧具有SQL查询功能的通用计算引擎。 这使您可以对数据进行很多有趣的事情,从流处理到机器学习。
在Drill中,您可以使用SQL查询来编写查询,与使用Microsoft SQL Server,MySQL或Oracle几乎相同。 在Spark中,您可以使用Python,Scala或Java编写代码来执行SQL查询,然后处理这些查询的结果。 最重要的是,SparkSQL中的查询不是用ANSI SQL编写的。 SparkSQL仅支持SQL功能的子集。
ANSI SQL与SQL类似
Drill支持ANSI SQL:2003。 如果您已经熟悉SQL,这意味着您可以将自己的技能直接转移到勇敢的NoSQL和大数据的新世界。 SparkSQL仅支持SQL的子集作为其查询语言。 尽管前者由于遵循SQL标准而最易于使用,但后者通常足以提取数据以使用Spark处理它。
对于大多数想要使用Spark处理数据的人来说,拥有SQL子集可能不会成为一个大问题,因为大多数人将使用非常简单的SQL语法。 从某些文件或数据库中选择SELECT列,也许加入几个不同的文件,并抛出where子句以限制结果。 但是,当进入稍微复杂的SQL语法(如嵌套的select语句)时,仅SparkSQL就不够用了。
数据格式和来源
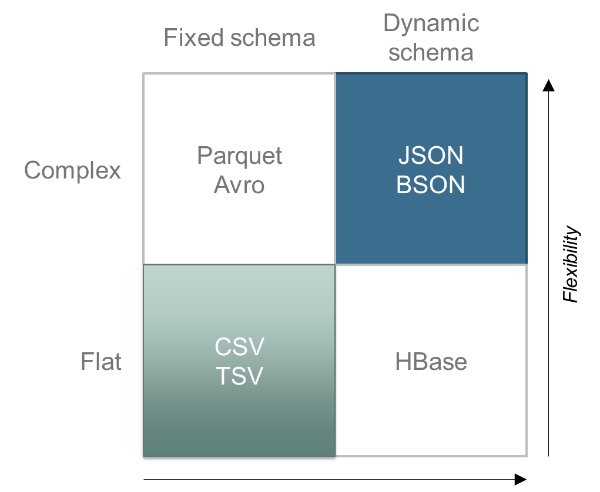
Apache Drill利用JSON数据模型在多种不同的数据格式和数据源上运行SQL查询,其中一些包括:HBase,MapR-DB,Cassandra,MongoDB,MySQL,CSV,Parquet,Avro,当然还有JSON。 SparkSQL也可以查询许多相同的数据源和格式,但是Spark和Drill与数据源交互的方法差异很大。
Drill可以同时查询来自任何或所有这些数据源或格式的数据,并且可以将功能推入底层存储系统。 Drill真正不同于SparkSQL的地方在于其对JSON数据进行操作的能力。 为了使Drill能够处理更复杂的JSON数据结构,它提供了一些高级功能,作为ANSI SQL的扩展。 其中之一是FLATTEN命令,它可以处理数据数组。 此函数分隔数组的条目,并为数组中的每个值的每个完整记录创建一行。 KVGEN –键值生成–启用查询数据,其中数据列的名称实际上是元数据。 如果您不知道要查询的字段名称,这将非常有用。 我建议仔细阅读Drill文档以进行更高级的操作。
在Apache Drill中,所有数据在内部都表示为简单或复杂的JSON数据结构,以这种方式表示时,Drill可以即时发现模式。 这允许可以动态变化并经常更改的复杂数据模型-非常适合非结构化或半结构化用途。
当处理不同的数据格式时,Drill的分布式体系结构显着提高了性能,并且Drill可以通过向量化一次处理许多记录。 更好的是,Drill优化查询并即时生成代码以提高效率。
利用现有工具
访问钻取有多种选择。 可以通过Drill Shell,Web界面,ReST界面或JDBC / ODBC驱动程序进行访问。 可以从其交互式外壳程序或JDBC / ODBC驱动程序中使用SparkSQL。 根据驱动程序的实现方式,驱动程序之间会有性能差异,但是由于两个项目都具有JDBC / ODBC支持,因此最大的区别在于SQL支持。
Apache Drill受到Tableau,Qlik,MicroStrategy,Webfocus甚至Microsoft Excel等许多商业智能(BI)工具的支持,以查询大数据。 这种集成使Apache Drill吸引了那些已经在他们最喜欢的BI工具上进行了大规模投资的人,这些人正在对其最喜欢的BI工具进行投资。 由于大多数BI用户只想查询数据,因此Drill非常适合。 尽管Spark具有类似SQL的语法,但对于这种用例而言,它往往是一个不足的选择。
该Apache Drill文档和Apache Spark文档将详细介绍如何设置JDBC和ODBC驱动程序。
意见与安全
当涉及到数据保护时,大数据可能意味着很大的麻烦。 许多组织需要采取某种方式来确保只有经过授权的人员才能访问敏感数据。 这对于像医疗保健这样的行业需要遵守诸如HIPAA之类的法规,或者对于需要保护诸如社会安全号码之类的敏感客户信息的金融行业而言,这一点至关重要。
视图可以聚合来自多个源的数据,并隐藏数据源的潜在复杂性。 通过模拟进行安全保护可以利用视图。 模拟和视图一起在文件级别提供了细粒度的安全性。 数据所有者可以创建一个视图,该视图从原始数据源中选择一些有限的数据集。 然后,他们可以授予文件系统特权,让其他用户执行该视图以查询基础数据,而无需赋予用户直接读取基础文件的能力。
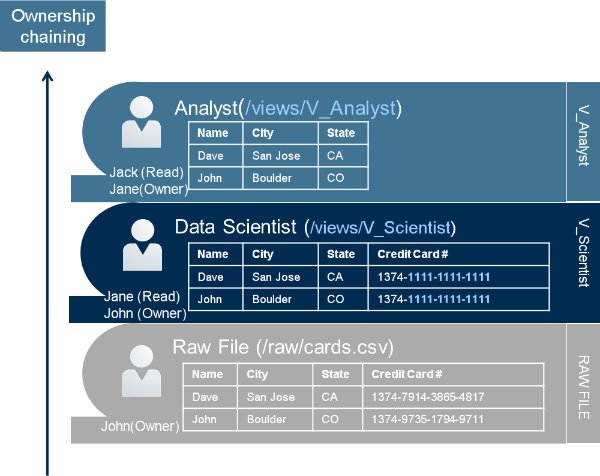
通过这种模拟模型对安全性的最大好处是,它不需要额外的安全性数据存储来管理此访问。 它利用了文件系统权限,因此非常易于使用和设置。
Spark确实具有这种范围。 如果使用案例简化了通过视图,隐私或数据安全性访问数据源的考虑,那么使用Drill会更好。
结论
关键的一点是,Drill被设计为几乎所有内容的分布式SQL查询引擎,而Spark是提供一些有限SQL功能的通用计算引擎。 如果仅考虑将Spark用于SparkSQL,我的建议是重新考虑并朝Apache Drill的方向发展。
如果您需要执行复杂的数学,统计或机器学习,那么Apache Spark是一个不错的起点。 如果不是这种情况,那么Apache Drill是您想要的地方。
如果您需要使用Apache Spark,但是感觉它的SQL支持不能满足您的需求,那么您可能想考虑在Spark中使用Drill。 由于Drill具有JDBC驱动程序,Spark可以利用这种驱动程序,因此Spark可以使用Drill来执行查询。 如果您同时需要Apache Spark和Apache Drill的功能,请不要排除它。
我鼓励您自己尝试一下。 您可以单独下载它们并自己安装它们,也可以在MapR沙箱中同时获得它们。 这将使您可以在自己的计算机上使用这些功能强大的系统。
翻译自: https://www.javacodegeeks.com/2015/12/apache-spark-vs-apache-drill.html















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









