





Evan喜欢使用最新的开源技术来设计,构建和改进前沿的分布式数据和后端系统。 他是FiloDB开源分布式分析数据库以及Spark Job Server的创建者。 他领导了基于Storm,Spark,Kafka,Cassandra和Scala / Akka的多个大数据平台的设计和实现,其中包括柱状实时分布式查询引擎。 他是Apache Spark项目的积极贡献者,也是Datastax Cassandra MVP。 他从Spark 0.8开始创建了Spark应用程序,从0.6开始了Cassandra。 他是GitHub,开源和聚会的忠实拥护者,并在Strata,Spark Summit,Cassandra Summit,FOSS4G和Scala Days等各种会议上进行了演讲。 他拥有斯坦福大学的电气工程学士学位和硕士学位。
本文探讨了Spark SQL如何执行多表JOIN,以及如何使用Datastax DSE(Spark和Cassandra)和FiloDB实现真正的快速JOIN。
背景
在Tuplejump ,我们帮助不同的企业基于最新技术构建现代大数据平台。 我们的客户之一是Element Financial Services ,这是一家领先的车队管理和设备融资公司。 他们选择了Datastax Enterprise作为替换其数据仓库并为其下一个分析和BI平台提供支持的理想平台。 Datastax Enterprise通过内置的Apache Spark支持,企业功能以及Datastax的专业支持,提供了稳定,易于设置的Cassandra安装。
是什么使Datastax Enterprise,Cassandra和Spark的采用对于构建数据仓库和BI平台具有挑战性? 首先,该平台有望通过现有的BI工具满足当前的SLA,以进行报告和临时分析。 Cassandra是一个坚如磐石的分布式数据库,但其设计目的是为数千个并发的小型读写操作,而不是为涉及扫描数百万条记录的传统分析工作负载而设计的。 查询的多样性和即席性质阻止了预聚合的广泛使用。 要满足期望,就需要将平台推向极限并进行创新。 其次,由于现有查询,报告和使用模式,无法对所有表进行非规范化的常规Cassandra数据建模技术。 缓慢更改维表和其他业务需求意味着,与将ETL复杂性提高一个数量级相比,JOIN是更可取的。 JOIN在Apache Spark中还不是很有效,尽管在每个发行版中它们都在改进。 因此,我们的目标是能够在5秒内并发地在Datastax Enterprise上执行JOIN查询。
计划
我们从对事实和维度表建模开始,以便大多数查询可以表示为单分区查询。 更具体地说,给定分区键A,B和C,最快的查询发生在它们使用WHERE子句查询数据时,它们看起来像WHERE A = val1 AND B = val2 AND C = val3。 这些谓词导致一个Cassandra分区的完全匹配,并且Spark-Cassandra连接器能够将查询减少到单个Spark分区/线程,并且仅查询一个Cassandra节点。 (这通常称为谓词下推)与其他谓词组合的查询会导致多分区查询或整个表扫描,这需要几分钟的时间。 通过这种方式对表进行建模可以最大程度地发挥Cassandra的细粒度分区和过滤优势。
下一步是联接优化。 假设您有以下查询:
SELECT t1.col1, t2.col2
FROM small_table t1, big_table t2
WHERE t2.a = t1.a AND t1.a = 'XYZ'假设列a是表t1和t2的分区键。 因此,Cassandra将获得谓词下推以从表t1的单个分区读取(t1.a ='XYZ'),但由于在t2.a上没有过滤器,因此在t2上启动了全表扫描。 这真的很慢。 一种选择是强制用户手动指定其他谓词,以便您具有以下查询:
SELECT t1.col1, t2.col2
FROM small_table t1, big_table t2
WHERE t2.a = t1.a AND (t1.a = 'XYZ' AND t2.a = 'XYZ')此查询更好,因为您对表t1和t2都有分区键谓词下推。 但是,我们无需投资来更改用户行为和/或改变BI工具的使用方式,而是投资编写了一个定制的Spark Hive Thrift服务器,该服务器可以拦截SQL查询,对其进行分析并转换逻辑计划以自动扩充JOIN谓词。 (如何做应该是整篇文章的主题。)定制服务器还为我们提供了进行其他定制计划转换的机会,例如选择最佳的Cassandra表来回答给定的查询并将该表替换为查询计划中的表。 我们正在通过SPARK-13219将其中一些优化回馈给Spark。
最后,为了实现所需的并发性,我们使用FAIR调度程序模式spark.scheduler.mode = FAIR运行了Hive Thrift Server和任何其他Spark应用程序。 我们已经观察到,在群集上,即使对于占用所有线程的大型Cassandra扫描作业,Spark也能够安排在同一应用程序中运行的并发作业。
使用所有Cassandra表
这是Spark UI中的DAG和事件时间线可视化,它在小型DSE 4.8集群上运行4表JOIN报告查询。 非平凡查询包括从4个表中选择29列,3个联接列和27个分组列。 最大的表中的分区每个包含数千行。

Spark的DAG可视化是一个很好的工具,它可以显示不同的阶段,它们之间的关系以及每个阶段进行的操作。 您可以看到这里有两种不同的阶段– 7、8、9和12主要由MapPartitions和Filter组成,并且与其他阶段无关。 这些阶段是从Cassandra表并行读取数据(MapPartitions)并对其进行过滤的阶段。 阶段10、11和13是Join阶段(ShuffleHashJoin),这些行指示Spark如何执行4表联接:首先,在阶段10中联接来自7和8的数据; 然后将10的结果与9的数据相加; 等等。
通过查看事件时间表,您可以得出以下结论:
*总查询时间约为 6秒
*由于单个分区谓词下推,四个读取阶段并行发生,每个线程一个。 好极了! *读取占用大部分查询时间。 随机播放阶段的末尾是微小的,取决于读取阶段。 他们大概需要1/4秒。 *查询在两个表的读取上成为瓶颈,大约需要花费时间。 每个5秒。 这些是包含最多数据的读取。 因此,改组不是瓶颈。
总体而言,该计划运行良好。 使用具有分区键下推功能的良好数据建模,可以使读取并行化,但每个表包含在一个线程中。 我们可以做得更好并且在那些长篇小说上有所改进吗?
使用混合的Cassandra + FiloDB表
我们决定将数据从两个最大的表(一个事实表,一个大尺寸表)存储到FiloDB中 ,后者以针对快速分析/ OLAP查询进行了优化的列格式将数据存储到Cassandra中。 FiloDB具有类似于Cassandra的数据模型 ,这意味着我们可以利用相同的单分区查找策略来有效过滤查询。 当用两个大的Cassandra表代替FiloDB表时,结果如下:
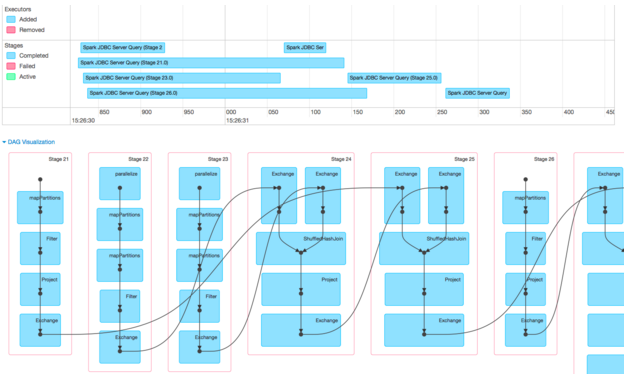
我们将重点放在事件时间线上,因为DAG除了阶段号外都是相同的。 请注意,现在的时间轴刻度为毫秒,整个4表JOIN查询仅需半秒钟即可完成! 启用此加速的原因是使用了FiloDB,它将之前的5秒读取减少到每个250ms以下。 (FiloDB阶段为22和23,在每个阶段的顶部都有“并行化”,因为FiloDB数据源使用sc.parallelize / sc.makeRDD ,而Spark Cassandra Connector具有自定义的RDD类)。
通过使用FiloDB存储最大的表,对于跨越四个表并满足所需SLA的非平凡查询,我们能够实现亚秒级的JOIN时间。 同时,该解决方案仍适用于Datastax Enterprise / Spark / Cassandra堆栈,从而简化了操作和维护,并降低了总拥有成本。
从这往哪儿走
希望您已经看到了可以组合在一起的策略和技术,这些策略和技术可以加速Spark和Cassandra上的实际JOIN查询-甚至4表JOIN都可以运行不到一秒!
有关FiloDB的更多信息,请访问我们的O'Reilly网络广播 ,或随时查看Github项目 。 有关Datastax Enterprise的更多信息,请访问登录页面 。
如果您有兴趣开发Spark,Cassandra和FiloDB等前沿大数据技术,请考虑加入我们在Element和Tuplejump的工作!















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









