






概述
一提到数据存储马上我们就会想到数据库, 一想数据库就会想到 Oracle, MySQL等关系数据库。
其实今天摆在我们面前有更多选择, 例如
- 迷你版的关系数据库 SQLite
- 流行的开源数据库 MySQL
- 强大的开源数据库 PGSQL
- 时间序列数据库 InfluxDB
和众多的 NoSQL 数据存储系统
- Cassandra
- Riak
- Redis
- MongoDB
以及分布式文件存储系统
- HDFS
- Swift (Openstack Object Storage)
Cassandra 是 NoSQL 的典型代表产品, 具有极佳的线性可扩展性和高可用性, 同时性能也不错, 跨Data center的复制也还行, 不足之处在于它做不到强一致性, 不要指望写入Cassandra的数据, 别人立马就能正确无误地由读出来. 与大多数NOSQL产品一样, 它所能保证的只能是最终一致性.
先复习一下相关理论
CAP
著名的CAP理论提出一致性,可用性,分区容错性,三者不可兼得
C:Consistency,一致性, 在不同的地方和时间点上数据总是一致的
A:Availability,可用性, 在任何地点和时间都可以使用服务
P:Partition tolerance,分区容错性,即使出现网络故障系统依然具有可靠
大多数 nosql 产品都选择了牺牲强一致性,保证可用性和分区容错性,以及最终一致性,Cassandra 也是如此
ACID
传统关系数据库用 ACID 来保证强一致性, 这个 Cassandra 是做不到的
A: Atomicity,原子性
C: Consistency,一致性
I: Isolation,隔离性
D: Durability,持久性
BASE
大多数 NOSQL 系统采用的方式
BA:Basically Available,基本可用
S:Soft State,软状态,即中间可能不一致的状态
E:Eventually Consistent,最终一致性
分布式哈希表和一致性哈希
DHT-distributed hash table 分布哈希表, 一种去中心化的分布式系统, 提供类似于哈希表查找服务, 键值对存储在DHT中, 任何参于的节点都可根据 key 来存储相应的值
DHT的特点是
- 独立自主性: 各个节点各自为战, 不需要中央的协调和控制节点
- 容错性: 任何一个节点加入,离开或损毁, 系统依然可用
- 可扩展性: 可以任意增加节点以提高系统容量
打个比方, 我有一篮12个鸡蛋, 可以放在三个篮子里
用最简单的取余法, 将鸡蛋编号0~17除以3, 每个篮子里放4个鸡蛋
假如增加或减少一个篮子, 都不是问题, 我只要根据编号取余一下子就能确定地找到那个鸡蛋
当然这里的取余法太 low 了, 虽然数据分布绝对均匀, 但是一旦增减篮子我们就需要移动鸡蛋来满足约束条件
一致性哈希就是比取余法更高级点的哈希算法, 一致性表示即使有篮子的增减, 无需移动数据依然可以根据编号确定地找到想找的鸡蛋, 并且通过虚拟节点技术使得数据分布也比较均匀
举例如下
package com.github.walterfan.util;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Collection;
import java.util.Map;
import java.util.SortedMap;
import java.util.TreeMap;
interface HashFunction {
Integer hash(String keyStr);
}
class MD5Hash implements HashFunction {
public Integer hash(String keyStr) {
byte[] bKey=mac("MD5", keyStr);
return ((int) (bKey[3] & 0xFF) << 24)
| ((int) (bKey[2] & 0xFF) << 16)
| ((int) (bKey[1] & 0xFF) << 8)
| (bKey[0] & 0xFF);
}
public static byte[] mac(String alga, String str) {
MessageDigest md;
try {
md = MessageDigest.getInstance(alga);
return md.digest(str.getBytes());
} catch (NoSuchAlgorithmException e) {
throw new IllegalArgumentException(e);
}
}
}
public class ConsistentHash<T> {
private static Log logger = LogFactory.getLog(ConsistentHash.class);
private final HashFunction hashFunction;
private final int numberOfReplicas;
private final SortedMap<Integer, T> circle = new TreeMap<Integer, T>();
public ConsistentHash(HashFunction hashFunction, int numberOfReplicas,
Collection<T> nodes) {
this.hashFunction = hashFunction;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
public void add(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.put(hashFunction.hash(node.toString() + i), node);
}
}
public void remove(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove(hashFunction.hash(node.toString() + i));
}
}
public T get(String keyStr) {
if (circle.isEmpty()) {
return null;
}
int hash = hashFunction.hash(keyStr);
if (!circle.containsKey(hash)) {
SortedMap<Integer, T> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap
.firstKey();
}
return circle.get(hash);
}
public String toString() {
StringBuilder sb = new StringBuilder("");
for(Map.Entry<Integer, T> entry : circle.entrySet()) {
sb.append(entry.getKey());
sb.append("=");
sb.append(entry.getValue());
sb.append("\n");
}
return sb.toString();
}
/**
* @param args
*/
public static void main(String[] args) {
java.util.List<String> nodes = new java.util.ArrayList<String>(3);
nodes.add("1");
nodes.add("2");
ConsistentHash<String> continuum = new ConsistentHash<String>(new MD5Hash(), 8, nodes);
String strID = "16580";
String node = continuum.get(strID);
System.out.println("select node: " + node + " for " + strID);
java.util.Map<String, Integer> statMap = testDistribution(continuum);
System.out.println(statMap);
continuum.add("3");
node = continuum.get(strID);
System.out.println("add node 3, select node: " + node + " for " + strID);
java.util.Map<String, Integer> statMap1 = testDistribution(continuum);
System.out.println(statMap1);
continuum.remove("3");
node = continuum.get(strID);
System.out.println("remove node 3, select node: " + node + " for " + strID);
java.util.Map<String, Integer> statMap2 = testDistribution(continuum);
System.out.println(statMap2);
}
private static java.util.Map<String, Integer> testDistribution(
ConsistentHash<String> continuum) {
java.util.Map<String, Integer> statMap = new java.util.HashMap<String, Integer>();
for(int i = 10000; i < 20000; i++) {
String svr = continuum.get("server" + i);
//System.out.println(i + ". server: " + svr);
Integer cnt = statMap.get(svr);
if(null == cnt) {
statMap.put(svr, 1);
} else {
statMap.put(svr, cnt + 1);
}
}
return statMap;
}
}
输出如下
select node: 2 for 16580
{1=5891, 2=4109}
add node 3, select node: 2 for 16580
{1=4703, 2=2517, 3=2780}
remove node 3, select node: 2 for 16580
{1=5891, 2=4109}
安装
brew install cassandra22
工具
cqlsh
./cqlsh 192.168.3.5 -u test - pass
node tool
./nodetool -h 192.168.3.5 ring
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 1015.55 KB 256 100.0% 9ec3a333-81bc-4945-9db1-ef1a13b62cde rack1
CQL
类似 SQL , 详细语法参见 http://docs.datastax.com/en/dse/5.1/cql/cql/cql_reference/cql_commands/cqlCommandsTOC.html
SELECT * from system.schema_keyspaces limit 10;
SELECT * from system.schema_columnfamilies limit 10;
SELECT * from system.schema_columns limit 10;
创建一个表空间
CREATE KEYSPACE pims
WITH REPLICATION = {
'class' : 'NetworkTopologyStrategy',
'datacenter1' : 1
} ;
架构及特点
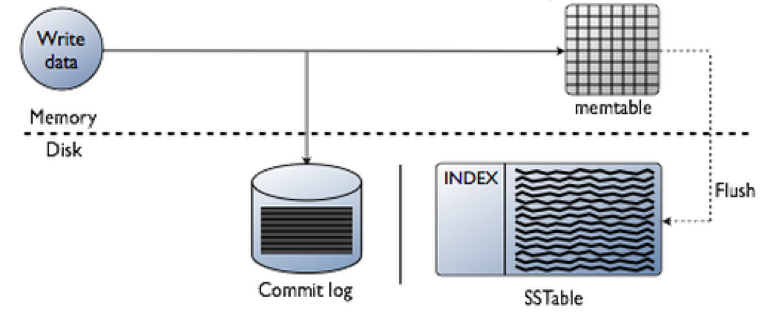
Cassandra 写的时候是将数据追加到可用节点的 commit log 上, 因而速度很快
- 将数据追加到 commit log 上
- 更新内存的数据结构 memTable
- 内存数据如果超过了最大限值, 则储存到磁盘上的 SSTable 中
相比之下, Cassandra 读的速度比较慢, 因为它要根据主键至少读取两个节点, 经过数据比较后得出结果
参见 Cassandra Architecture in brief
Gossip 协议
流言协议, 俗话说, 流言蜚语, 一传十, 十传百, 尽人皆知. Gossip 协议就是采用了类似的方法将消息迅速从一个结点复制到其他结点. 传递时需要注意的就是传递的广度和深度, 不要造成回环
具体实现可参见 https://github.com/apache/incubator-gossip
Gossiper 类随机选择一个节点来发送消息 GossipDigestSyncMessage, 接收消息节点发回确认消息, 发送节点回应, 这轮消息同步即完成 (send-receive-ack), 如果同步失败, 则将此节点标记为可疑节点, 连续发生同步失败则可认为此节点已经挂掉了, 具体算法为 Phi Accural Failure Detection.
核心结构
Node 节点
也就是你存储数据的地方, 一般我们至少部署三台Cassandra 节点
在读写的时候同时向三台节点发出请求, 任意两台返回响应即可
N < W + R
N 为复制的节点数
W 为写数据的最少返回节点数
R 为读数据的最少返回节点数
3 < 2 + 2
如果是 7 台节点, 复制因子设为3, 根据key 哈希过后会找到三台结点,依然是
3 < 2 + 2
复制因子设为4, 那就是7 < 4 + 4, 不过一般复制到三个结点也就够了
datacenter 数据中心
一组相关节点的集合, 可以是物理上的一个数据中心, 也可以是虚拟的数据中心
一般我们认为不同的数据中心应该位于不同的网络位置. 一个数据中心内的节点是在同一个网段中的
Cluster 集群
A cluster contains one or more datacenters. It can span physical locations.
一个集群包含一个或多个数据中心, 它可能会跨越多个物理位置.
Commit log 提交Log
All data is written first to the commit log for durability. After all its data has been flushed to SSTables, it can be archived, deleted, or recycled.
所有的数据都会先写到commit log中持久化, 当数据被刷新到 SSTables 后, 相关的commit log可以被归档,删除或回收
Table 表
类似于关系数据库, 表就是行的集合, 行由列组成, 列又分为主键和值
SSTable 排序字串表
排序的字符串表(SSTable)是一种不可变的数据文件, Cassandra定期向其写入memtable。 SSTables仅可追加数据, 按顺序存储在磁盘上,Cassandra为每个表保留一张 SSTable.
数据模型
| Cassandra | RDBMS |
|---|---|
| Key | primary key |
| Column family | table |
| Keyspace | database |
| Cluster | server |
Cassandra 的 data model 设计与关系数据库大为不同, 在设计模型不能完全照搬传统关系型数据库的那一套
- 不用想方设法减少写次数
在cassandra 中对于大量的写操作有所优化, 效率很高, 相比之下, 读操作更加耗时
- 不用想方设法减少重复数据
磁盘空间不是大问题, 与其遵循数据库范式千方百计地减少重复次数, 不如增加冗余以减少读的次数
除此之外, Cassandra 没有 Join 操作, 这个在分布式架构下这也绝非我们想要做的
基本目标
-
- 在集群中均匀分布数据
记录是按照 primary key 的第一个元素 partition key 的哈希在集群中分布的, 所以要挑选一个易于均匀分布的 primary key
-
- 尽量减少跨分区读数据
分区是一组行记录的集合, 共享相同的partition key , 当你执行一个查询时, 你要尽可能从尽量少的分区中读取
这两条原则看起来有一点点矛盾, 第一条是针对写,第二条是针对读,在设计数据结构时要做好平衡和取舍
数据重复不是问题, 数据结构可以灵活, 只能根据 Key 进行查询
在设计数据模型时可以按以下步骤
步骤1: 根据需求, 把查询和修改哪些数据一一列举出来
数据是查询多还是修改多, 查询多的数据最好放在一个分区里, 修改多的数据最好放在不同的分区中
步骤2: 创建表时尽量使查询和读取落在一个分区里,宁愿多写一点,也不要跨区或表读取
注意事项
我们在使用 Cassandra Driver 提供的 CQL 时, 常错误地和 SQL 搞混了
注意
Insert == Update , 所有的插入和修改本质上都是 Set
由于 Cassandra 没有行级锁,如何处理并发情况下的竞态条件(race condition) 呢?
一是写完以后于读一下, 如果比较之后发现不是当初写的, 直接向客户端报错, 提示冲突, 写入不成功
二是使用 Cassandra 2.0 之后提供的轻量级事务, 比如
INSERT INTO USERS (login, email, name, login_count)
values ('jbellis', 'jbellis@datastax.com', 'Jonathan Ellis', 1)
IF NOT EXISTS
And an an example of resetting his password transactionally:
UPDATE users
SET reset_token = null, password = ‘newpassword’
WHERE login = ‘jbellis’
IF reset_token = ‘some-generated-reset-token’
Cassandra 的技术细节和内部实现再另行研究总结, 这里就此打住.
参考资料
客户端配置
- Address: 127.0.0.1:9042
- Username
- Password
- LocalDataCenter
- ConsistencyLevel
- Keyspace
- RetryPolicy
- ReadTimeout
- ConnectTimeout
Cassandra ConsistencyLevel
- ANY
- ONE
- TWO
- THREE
- QUORUM
- ALL
- LOCAL_QUORUM
- EACH_QUORUM
- SERIAL
- LOCAL_SERIAL
- LOCAL_ONE
驱动
Java Driver
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>3.1.2</version>
</dependency>
<dependency> <groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-mapping</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-extras</artifactId>
<version>3.1.2</version>
</dependency>
Python Driver
Cassandra源码:
git clone http://git-wip-us.apache.org/repos/asf/cassandra.git















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









