






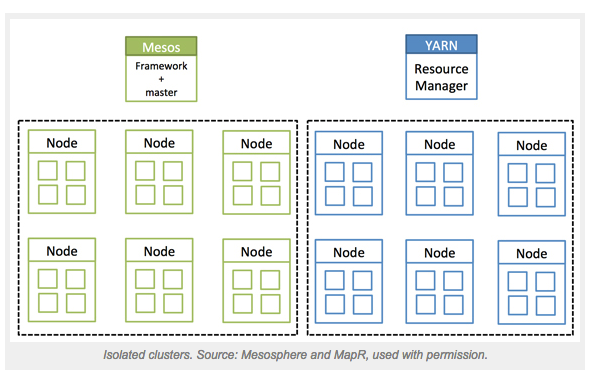
这是两个孤立集群的故事。 第一个集群是Apache Hadoop集群。 这是一个孤岛,其资源与Hadoop及其流程完全隔离。 第二个集群是我对不属于Hadoop集群的所有资源的描述。 之所以将它们分解,是因为Hadoop通过Apache YARN(又是另一个资源协商器)来管理自己的资源。 这对Hadoop很好,但是当队列中没有大数据工作负载时,这些资源经常会被利用不足。 然后,当进行大数据作业时,这些资源就被拉到了极限,很可能需要更多的资源。 当您在岛上时,这可能会很难。
Hadoop是要拆除墙壁(尽管是数据孤岛的墙壁),但是要拆除墙壁。 发生的事情是,虽然拆除了一些墙,但其他类型的墙却在原处升起。
Apache Mesos是另一种技术,也意在拆除墙壁-但是Mesos通常被定位为管理“第二集群”,这些集群是所有其他非Hadoop工作负载。
这是故事的真正起点,其中包括Mesos和YARN的这两个孤岛。 它们经常相互抵触,好像它们不兼容。 事实证明他们在一起工作,这就是我的故事。
Mesos和YARN的简要说明
Mesos和YARN之间的主要区别在于它们的设计优先级以及它们如何进行调度工作。 Mesos旨在成为整个数据中心的可扩展全局资源管理器。 它是2007年在加州大学伯克利分校设计的,并在Twitter和Airbnb等公司的生产中得到了加强。 YARN的创建是出于扩展Hadoop的必要性。 在YARN之前,资源管理已嵌入Hadoop MapReduce V1中,必须删除它才能帮助MapReduce扩展。 MapReduce 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5004
5004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









