





我很高兴能有机会客串博客上MAPR网站,利用一个博客这是在DataTorrent网站上公布09月09日,2015年MAPR是我们在Hadoop和大数据生态系统的重要战略合作伙伴之一。 我们拥有许多相同的理念和指导原则,例如为客户和用户提供真正的企业级产品和非常容错的,高度可用的系统。 我们也非常高兴与MapR合作开展一系列业务和合作伙伴计划。 我们期待下周由MapR赞助并在其办公室主办的Meetup 。
在此博客文章中,我想提供一些有关Apache Apex是什么以及它为什么重要的详细信息。
Apache Hadoop已经存在了十多年。 它已经成为事实上的大数据平台,允许企业通过将大数据转变为有用,有意义和创收的事物来转变其业务运营。 Hadoop承诺支持大数据,而不会产生您通常认为如此强大的处理系统所需的成本。 改变业务运营的巨大希望将继续推动该行业的高增长。
当Yahoo!的Hadoop工程师开始时,一切就开始了。 问:“我们如何建立有效的搜索索引功能?” 随后的迭代和一些启发产生了MapReduce编程模型。 尽管功能强大,但MapReduce并不完美。 掌握MapReduce需要陡峭的学习曲线。 将应用程序迁移到MapReduce几乎需要完全重写。 同样令人担忧的是,MapReduce的核心是一个批处理范例并“计算去往数据”,这对Hadoop实现其真正潜力构成了威慑。 可以预见的是,MapReduce成为阻碍大数据产品化的障碍。 顺便说一下,MapReduce有更快的替代品。 与Hadoop一样,这些模型需要更深入的专业知识,难以操作且难以掌握。 因此,Hadoop中断了大数据需求的处理方式,但仍然生产不足。 Hadoop启动十年后,只有一小部分大数据项目正在生产中。 数据正在快速增长,利用大数据的能力已成为决定性的竞争优势。 MapReduce阻碍了将其转变为数据驱动型业务的需求(实际上更多是争夺)。
事后看来,很明显,在早期,Hadoop的成功并没有预料到。 如果他们期望Hadoop的成功,那么问题就应该是:“我们如何使用大规模分布的资源?” 这个问题的答案很快就出现了,下一代的Hadoop是YARN(Hadoop 2.0)。 YARN首次带来了探索处理大数据的分布式资源如何执行“很多事情”的能力,从而超越了早期的MapReduce范式,并且超出了批处理甚至是计算到数据范式的方式。 YARN提供了使大数据不仅变大,而且用例范围更广的功能。 通过作为Hadoop促进者的启用功能,YARN推动了Hadoop发挥其真正潜力。 Hadoop的困境类似于没有消息和互联网连接等更流行功能的手机的状况。 手机在成立之初就扰乱了固定电话市场,但直到将其转变为具有令人印象深刻的功能的新型“智能手机”后,才引起了市场的热议。 毫无疑问,YARN是实现大数据梦想的更大的推动因素,有了它,Hadoop 2.0现在是真正的事实上的分布式操作系统。
需要的是基于YARN的前沿平台,能够从根本上实现Hadoop的潜力
现在正是时候,不仅要生产大数据,而且要了解如何启动它可以确保实现更大的业务目标。 这是一项艰巨的任务,需要易于部署的平台,除了日常的IT专业知识外,不需要任何其他东西,并且可以轻松与现有IT基础架构集成,同时确保迁移的简便性。 在设计新时代的Hadoop平台时,需要通过缩短从构建到启动的应用程序生命周期来缩短产品上市时间的方法,从而加快企业收益的实现。 他们还必须减少开发人员开发时间,DevOps投入运营,并最终减少获得业务洞察的时间。 诸如此类的平台将需要学习,适应和改变,以满足大数据世界的新兴需求。
让我们看一下构建这些平台的主要原则:
- 简洁专长
完全理解大数据非常困难,但是可以做的是使平台保持简单,并且无需深厚的专业知识,同时又保证了易于迁移。 无论是简单的工作流程还是简单的API,重点都应该放在“利用当前的专业知识来获取更多收益”上。 一个简单的API可以消除与Hadoop生态系统进行交互时进行大量更改的需求,从而使该平台可行并足以满足不断增长的数据需求。 大数据必须远离“学习新范例的专业知识并获得高薪”。 智能电话不会增加学习新事物的负担,那么为什么要使用大数据呢? 座右铭必须是“开放,拥有简单的API,并继续保持其简单性。” 简而言之,该平台必须启用用户定义功能(UDF)才能利用全部功能。 更好的是,业务逻辑应该仅是用户定义的功能,仅此而已。 - 代码重用
代码重用不仅是在单个流应用程序中重用代码,而且还可以在任何地方使用它,无论是流工作还是批处理作业。 大数据平台应该能够巧妙地处理批处理以及流式传输作业,同时使用户能够按原样使用其代码。 因此,平台应该利用动态数据架构,以实现流和批处理的统一。 处理无界数据的平台可以轻松处理无界数据。 此外,借助动态数据架构,结果几乎可以即时处理,从而减少了时间并降低了业务连续性所需的成本。 - 可操作性
在大数据中,功能开发的成本最多为20%(我很宽容),而可操作性的成本至少占总成本的80%。 在我的Yahoo! 几天,我们将80%以上的资源用于运营任务。 在Yahoo!中确实如此。 Hadoop以及Yahoo! 金融。 理想的平台应本机支持可操作性,以后不要再碰了。 企业应该只能专注于业务逻辑,因为这是他们最能理解的,仅此而已。 操作任务不是他们的核心专业知识,应该“外包”到平台,因此,可操作性必须与用户定义的代码一起使用。 这将使平台能够满足独特的业务需求。 强制用户代码中的操作方面导致大数据项目失败。 - 利用对Hadoop的投资
最后,新时代的大数据平台应该能够实现对大数据(即Hadoop)的投资程度。 它已经是事实,已经存在。 Hadoop生态系统的核心(HDFS,YARN)正在Swift成熟。 一个新平台应该是YARN原生的。 平台必须在本地充分利用Hadoop的所有成熟度,尤其是YARN。 随着YARN的成熟,它将继续提高正常运行时间,容错能力,安全性,多租户等。 与在YARN外部运行或不是为YARN本地构建的平台相比,原生YARN平台的支持和开发成本结构要低得多。 更多的YARN本机功能将导致更少的群集,从而转化为更高的可操作性。
Apache Apex是业界首个实现大数据颠覆性承诺的YARN本机引擎
由于很难完整地设想大数据,因此该平台必须能够以批处理范式,流式范式或同时以这两种方式成为推动大数据处理需求的基础。 Apache Apex是业界唯一的开源企业级引擎,能够处理批处理数据和流数据需求。 Apache Apex旨在为在高度数据密集型环境中运营的企业带来最高价值。
这就是Apache Apex是使大数据项目成功的首选解决方案的原因:
- 简洁专长
Apache Apex API非常简单。 应用程序是多个运算符的有向无环图(DAG)。 操作员开发人员仅需要实现一个简单的“ process()”调用。 该API允许用户插入任何函数(或UDF)来处理传入事件。 单线程执行和应用程序级JAVA专业知识是Apex支持大数据团队在数周内开发应用程序并允许他们在短短三个月内投入使用的主要原因。 Apex不仅易于部署和自定义,而且易于获得利用其全部功能所需的专业知识。 - 代码重用
开发人员需要最少的培训才能在Apache Apex上构建大数据应用程序。 而且,他们不需要对业务逻辑进行重大更改; 对其现有代码进行最小的调整就足够了。 功能规范与操作规范的完全分离大大提高了现有代码的重用性。 此外,Apex支持定义可重用模块。 它使相同的业务逻辑既可用于流又可用于批处理。 Apex是一个动态数据平台,可统一处理无限制数据(流作业)或文件中的有限制数据(批处理作业)的永无止境的流。 组织可以构建适合其业务逻辑的应用程序,并在批处理和流作业之间扩展应用程序。 Apache Apex架构可以处理消息总线,文件系统,数据库或任何其他来源的读写。 只要这些源具有可以在JVM内运行的客户端代码,该集成就可以无缝运行。 - 可操作性
从文件读取的能力是必需的,但不是使用动态数据平台进行批处理的充分方面。 另一方面是它必须满足企业可操作性SLA要求。 Apex旨在增强可操作性,因此基于Apex构建的应用程序只需要担心业务逻辑。 为了实现本机的容错能力,Apex平台可确保不会丢失数据,备份主数据(元数据),并且同样重要的是,应用程序状态会保留在HDFS(持久存储)中。 企业可以根据需要选择其他具有HDFS接口的持久性存储。 使用Apex,容错是Hadoop固有的,不需要Hadoop之外的其他系统来保持状态,也不需要用户编写任何额外的代码。 Apex应用程序可以从Hadoop中断中恢复到持久存在于HDFS中的已知状态。 在同一个Hadoop集群中运行两个不同版本的Apex应用程序很容易,甚至可以动态更改应用程序。 它易于操作和升级应用程序。 一旦应用程序运行,就不会有新的调度开销,除非应用程序或YARN请求更改资源。 Apex具有内置的动态数据结构,可在单个内核上以每秒百万个事件为单位的数据流。 因此,Apex是一个易于使用,高度可扩展的平台,该平台基于与Hadoop相同的安全标准构建。
下图显示了在多租户Hadoop集群中运行的Apex应用程序:
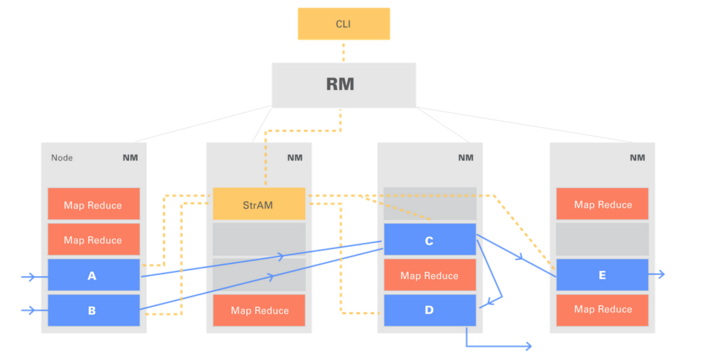
- 集成和易用性
Apex平台附带对Web服务和指标的支持。 这使得易于使用并易于与当前数据管道组件集成。 DevOps团队可以使用现有系统和仪表板以最小的更改来监视正在运行的数据,从而轻松地与当前设置集成。 Apex具有不同的连接器,并且易于添加更多连接器,因此可以轻松地与现有数据流集成。
此图显示了将Apex与其他来源/目的地集成的简便性:
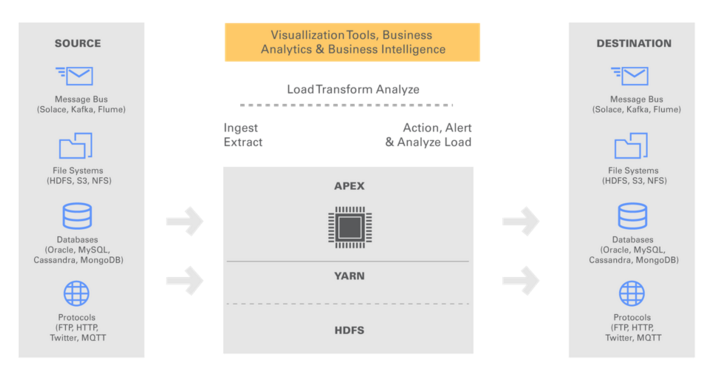
- 利用对Hadoop的投资
Apex是一个本地YARN大数据移动平台,其愿景是利用现有的分布式操作系统,而不是构建另一个操作系统。 就像MapReduce一样,它没有:资源调度程序和管理,分布式文件系统,安全设置,分布式操作系统中可用的其他常用实用程序。 Apex在将HDFS用作默认持久状态存储的同时,充分利用了所有YARN功能,而不会与YARN重叠。 充分利用企业在Hadoop方面的专业知识,硬件和集成方面的所有投资。 YARN的成熟度提高将转化为一个完全成熟的平台,该平台能够处理庞大的数据量,同时确保运营成本永不落伍。
该图显示了在利用Hadoop投资时如何轻松地重用Apex:
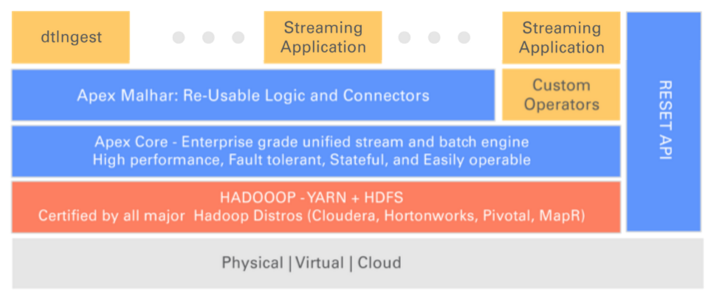
- 马尔哈尔
Apex随Malhar一起提供-操作员库。 这些用于流行消息总线,文件系统和数据库的数据源和目标的预先构建的运算符,使组织可以体验业务逻辑的加速发展。 这样可以大大缩短产品上市时间,从而在开发和启动大数据项目方面获得更大的成功。
此图显示了Malhar的不同类别的运营商:
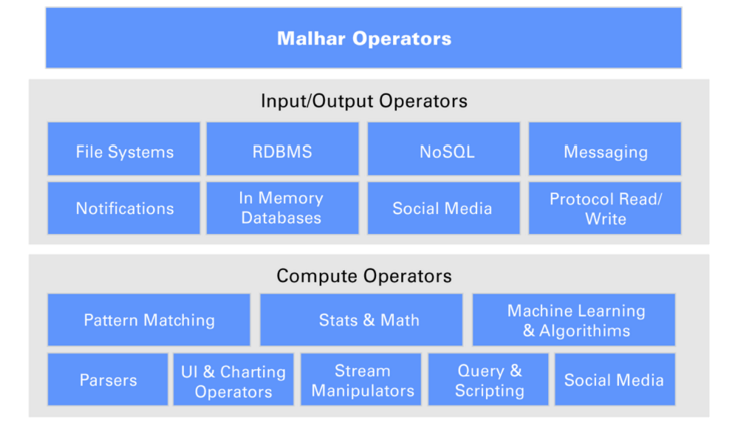
如果您想有所作为,请成为Apex贡献者。 与我们一起开发业界唯一的开源,企业级统一流和批处理平台! Apache Apex是一个非常开放的社区,我们计划以开放的,社区驱动的方式开发新功能时,我们会积极鼓励其参与:
- Apache Apex正在酝酿之中 ,其代码有两种版本, Apex-Core和Apex-Malhar 。 加入Apex 社区并订阅我们的论坛。
- Apache Apex的关联公司包括Apple,巴克莱,CapitalOne,DataChief,E8security,General Electric和Silver Spring Networks。 我们欢迎每个人加入我们,共同发展下一代生态系统,这将提高大数据项目的成功率。
- 有关更新,请加入Apex 聚会。















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









