





Evan喜欢使用最新的开源技术来设计,构建和改进前沿的分布式数据和后端系统。 他领导了基于Storm,Spark,Kafka,Cassandra和Scala / Akka的多个大数据平台的设计和实现,其中包括柱状实时分布式查询引擎。 他是Apache Spark项目的积极贡献者,Datastax Cassandra MVP,并且是开源Spark Job Server的共同创建者和维护者。 他是GitHub,开放源代码和聚会的忠实拥护者,并在Spark Summit,Cassandra Summit,FOSS4G和Scala Days等各种会议上进行了演讲。
引入FiloDB
如果您是大数据分析师,或为快速分析查询构建大数据解决方案,则您可能熟悉列式存储技术。 HDFS的开源Parquet文件格式节省了空间,并为Spark和Impala等查询引擎提供了强大动力,而Amazon Redshift之类的云解决方案则使用列式存储来加快查询速度并最小化I / O。 作为一种文件格式,Parquet直接用于实时数据摄取时更具挑战性。 对于诸如IoT,时间序列和事件数据分析之类的应用程序,由于它们的高写入可扩展性和易于使用基于幂等,基于主键的数据库API的结合,许多开发人员已转向NoSQL数据库(例如Apache Cassandra)。 大多数NoSQL数据库不是为快速,批量分析扫描而设计的,而是为高度并发的键值查找而设计的。 缺少的解决方案是将数据库API的易用性,NoSQL数据库的可伸缩性与用于快速分析的列存储技术相结合。
柱状。
我很高兴宣布FiloDB,这是来自TupleJump的新的开源分布式列式数据库。 FiloDB旨在摄取各种类型的流数据,包括机器,事件和时间序列数据,并对它们运行非常快速的分析查询。 在四个字母的首字母缩写词中,它是OLAP解决方案,而不是OLTP。
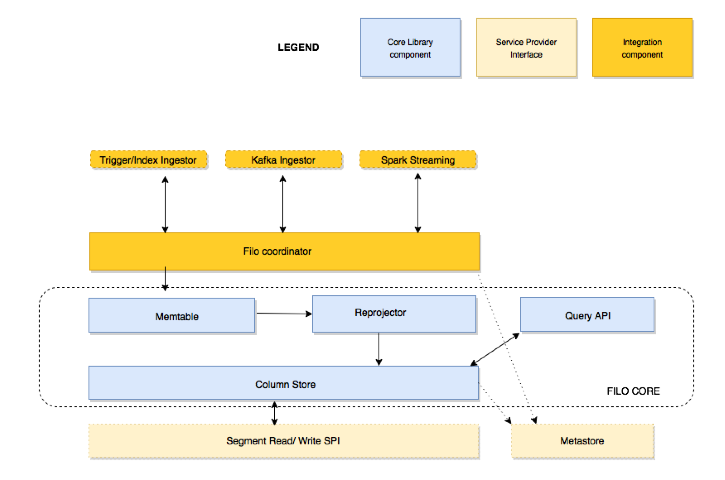
- 分布式 – FiloDB从一开始就设计为在同类最佳的分布式,横向扩展存储平台上运行,例如Apache Cassandra。 查询在Apache Spark中并行运行以进行横向扩展即席分析。
- 列式 – FiloDB通过将列式存储布局与字典压缩等不同的节省空间技术结合使用,为分析查询带来了突破性的性能水平。 在分析查询方面,性能可与Parquet媲美,并且比Cassandra 2.x上的Spark快一两个数量级。 有关POC性能的比较,请参见cassandra-gdelt回购。
- 版本化 –同时,行级,列级操作和内置版本化为FiloDB提供了比单独使用基于文件的技术(例如Parquet)更灵活的功能。
您的数据库以实现快速流式传输+大数据
FiloDB是为流应用程序设计的。 从Apache Kafka轻松轻松地一次提取数据流事件,时间序列和IoT应用程序-并通过使用SQL的易用性实现极其快速的即席分析。 每行由分区键和排序键键控,并且使用同一键的写是幂等的。 幂等写入使事件数据的存储一次即可。 FiloDB进行了艰苦的工作,以高效且经过读取优化的排序格式存储数据。
FiloDB + Cassandra + Spark =闪电般的分析
FiloDB利用Apache Cassandra作为其存储引擎,并利用Apache Spark作为其计算层。 Apache Cassandra是当今使用最广泛的,坚如磐石的分布式数据库之一,具有很好的操作特性。 许多人正在将Apache Spark与他们的Cassandra表结合起来,以便对Cassandra数据进行更加丰富的分析,而不仅仅是使用本地Cassandra CQL接口。 但是,将大量数据从Cassandra加载到Spark仍然非常缓慢,特别是对于分析和临时查询(例如平均或计算两列数据之间的相关性)而言。 这是因为Cassandra CQL表以面向行的方式存储数据。 FiloDB为Cassandra坚如磐石的存储技术带来了高效的列式存储以及Apache Spark的灵活性和丰富性的好处,与Cassandra 2.x相比,分析查询的速度提高了100倍。
轻松提取+ SQL + JDBC + Spark ML
FiloDB使用Apache Spark SQL和DataFrames作为主要查询机制。 这使您可以对数据运行熟悉的SQL查询,并使用Spark的JDBC连接器轻松连接Tableau等工具来查询数据。 同时,Spark的全部功能都可用于您的数据,包括机器学习MLlib库和用于图形处理的GraphX。
通过Spark DataFrames提取数据也非常容易。 这意味着您可以轻松地从任何JDBC数据源,Parquet和Avro文件,Cassandra表等中提取数据。 这包括轻松地从Spark Streaming和Apache Kafka插入数据。
FiloDB + SMACK适用于一切。
使用Kafka + Spark + Cassandra + FiloDB为整个Lamba架构实现提供动力。 无需同时使用Cassandra和Hadoop来实现复杂的Lambda双重摄取管道! 您可以将SMACK堆栈(Spark / Scala,Mesos,Akka,Cassandra,Kafka)用于您的分析堆栈的大部分,从而可以减少基础架构的投资。
叫什么名字

我喜欢甜点,而Filo面团是必不可少的成分。 可以将数据的列和版本视为层,而FiloDB则将这些层包装在一个美味的高性能分析数据库引擎中。
自豪地使用Typesafe堆栈构建
FiloDB使用Typesafe反应堆构建,可用于高性能分布式计算和异步I / O(Scala,Spark和Akka) 。
我在2015年卡桑德拉峰会上的演讲幻灯片!
如果您想了解更多信息,我鼓励您查看我在Cassandra Summit 2015上的幻灯片,我在该幻灯片上介绍了FiloDB,Spark和Cassandra! 回购和更多详细信息(如路线图)在下面的讨论中进行了介绍。
翻译自: https://www.javacodegeeks.com/2015/10/introducing-filodb.html















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









