





在本系列的最后一篇文章中,我们了解了如何使用Logstash,Elasticsearch和Kibana进行日志文件分析。 本周,我们将研究使用Elasticsearch和Kibana对任何数据进行分析的一般功能。
用例
我们已经看到Elasticsearch可用于存储大量数据 。 除了将数据放入数据仓库之外,Elasticsearch还可用于进行分析和报告。 另一个用例是社交媒体数据 :如果公司可以轻松地搜索品牌,他们可以查看品牌发生了什么。 可以从多个来源(例如Twitter和Facebook)提取数据,然后将其合并到一个系统中。 使用Kibana之类的工具可视化数据可以帮助您探索大型数据集。 最终,诸如Elasticsearchs Aggregations之类的机制可以帮助找到查看数据的新方法。
集合体
聚合提供了现在已弃用的方面所提供的功能,但还提供了更多功能。 他们可以合并和计算来自不同文档的值,因此可以向您显示数据中包含的内容。 例如,如果您在Elasticsearch中索引了推文,则可以使用术语聚合来查找最常见的主题标签。 有关在Elasticsearch中 为tweet编制 索引的详细信息, 请参阅Twitter River 上的这篇文章以及Logstash的Twitter输入上的这篇文章 。
curl -XGET "http://localhost:9200/devoxx/tweet/_search" -d'
{
"aggs" : {
"hashtags" : {
"terms" : {
"field" : "hashtag.text"
}
}
}
}' 聚合的关键字使用AGGS要求, hashtags是我选择识别结果的名称和术语聚集数给定域的不同条款(免责声明:对于一个分片设置的条款聚集可能不完全准确)。 该请求可能会导致如下所示:
"aggregations": {
"hashtags": {
"buckets": [
{
"key": "dartlang",
"doc_count": 229
},
{
"key": "java",
"doc_count": 216
},
[...] 结果可用于我们选择的名称。 聚合会将计数放入包含值和计数的存储桶中。 这与构面的工作原理非常相似,只是名称不同。 在此示例中,我们可以看到dartlang标签共有229个文档,而java标签dartlang包含216个文档。
这也可以仅用方面来完成,但还有更多:聚合甚至可以合并。 现在,您可以在第一个聚合中嵌套另一个聚合,每个聚合将为您提供更多符合其他条件的存储桶。
curl -XGET "http://localhost:9200/devoxx/tweet/_search" -d'
{
"aggs" : {
"hashtags" : {
"terms" : {
"field" : "hashtag.text"
},
"aggs" : {
"hashtagusers" : {
"terms" : {
"field" : "user.screen_name"
}
}
}
}
}
}'我们仍然要求对标签进行术语汇总。 但是现在我们嵌入了另一个聚合,一个用于处理用户名的术语聚合。 这将导致类似这样的情况。
"key": "scala",
"doc_count": 130,
"hashtagusers": {
"buckets": [
{
"key": "jaceklaskowski",
"doc_count": 74
},
{
"key": "ManningBooks",
"doc_count": 3
},
[...]现在,我们可以看到使用了特定哈希文本的用户。 在这种情况下,一个用户经常使用一个标签。 这是仅凭查询和构面不容易获得的信息。
除了我们在这里看到的术语“聚集”以外,还有许多其他有趣的聚合可用,并且每个发行版中都会添加更多的聚合 。 您可以在存储区聚合(如术语聚合)和指标聚合之间进行选择,这些指标可从存储区计算值,例如,平均值或其他统计值。
可视化数据
除了我们上面看到的JSON输出之外,该数据还可以用于可视化。 这甚至可以为非技术受众准备。 Kibana是通常用于日志文件数据的选项之一,但可以用于各种数据,例如,我们上面已经看到的Twitter数据。
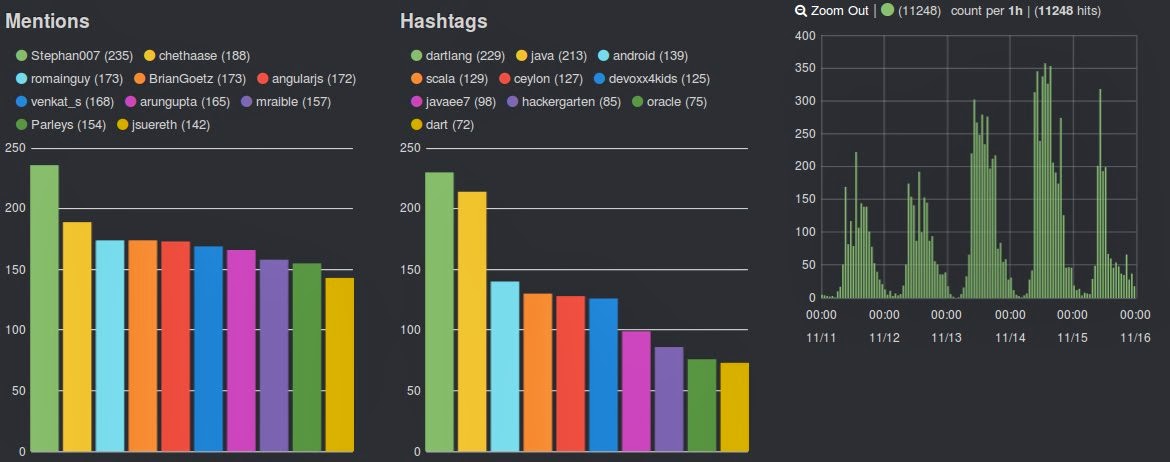
有两个条形图,显示提及和主题标签的术语频率。 我们已经很容易看到哪些值占主导地位。 另外,右侧的日期直方图显示了大多数推文的发送时间。 总而言之,这些可视化可以提供仅在组合数据时才能看到的趋势方面的大量价值。
该图显示了Kibana 3,它仍然依赖于facet功能。 Kibana 4将改为提供对聚合的访问。
结论
这篇文章结束了有关Elasticsearch用例的系列。 我希望您喜欢阅读它,也许您在此过程中学到了新知识。 我不能再花那么多时间写博客了,但是新的帖子将会来。 请随时关注此博客。
翻译自: https://www.javacodegeeks.com/2014/12/use-cases-for-elasticsearch-analytics.html















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









