





在本系列有关Elasticsearch用例的最后一篇文章中,我们介绍了Elasticsearch提供的用于存储甚至大量文档的功能 。 在这篇文章中,我们将研究其另一个核心功能:搜索。 我正在利用上一篇文章中的某些信息,因此,如果您还没有阅读过,则应该立即阅读。
如我们所见,我们可以使用Elasticsearch存储甚至可以分布在多台机器上的JSON文档。 索引用于对文档进行分组,并且每个文档都使用某种类型存储。 分片用于在多个节点之间分配索引的一部分,副本是分片的副本,用于分配负载和容错。
全文搜索
每个人都使用全文搜索。 仅通过导航和类别就无法访问大量信息。 Google是提供大量信息即时关键词搜索的最杰出的例子。
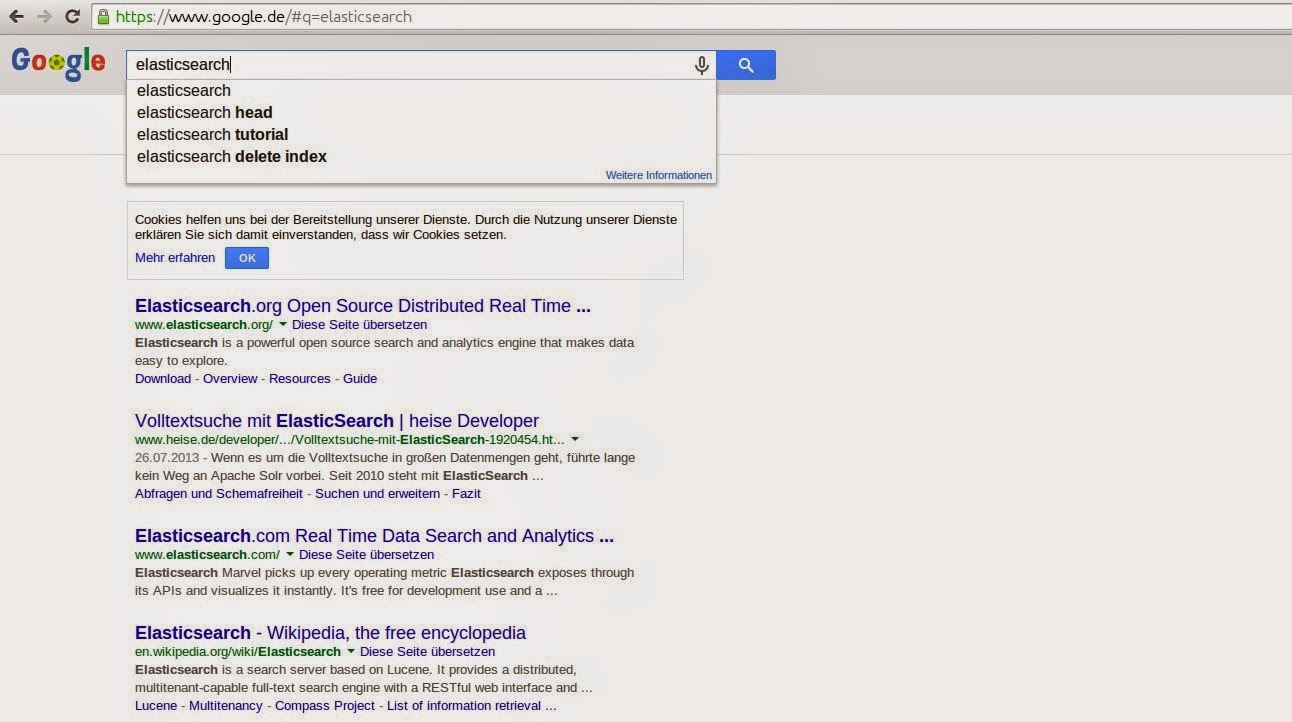
查看Google的功能,我们已经可以看到全文搜索的一些常见功能。 用户仅提供关键字,并期望搜索引擎提供良好的结果。 预计文档的相关性很好,并且用户希望在第一页上获得所需的结果。 文档的相关性可能受不同因素的影响,例如查询的术语存在于文档中。 除了获得最佳结果外,用户还希望在搜索过程中得到支持。 建议和结果摘录中的突出显示等功能可以帮助实现这一目标。
搜索非常重要的另一个领域是电子商务,其中亚马逊是主要参与者。
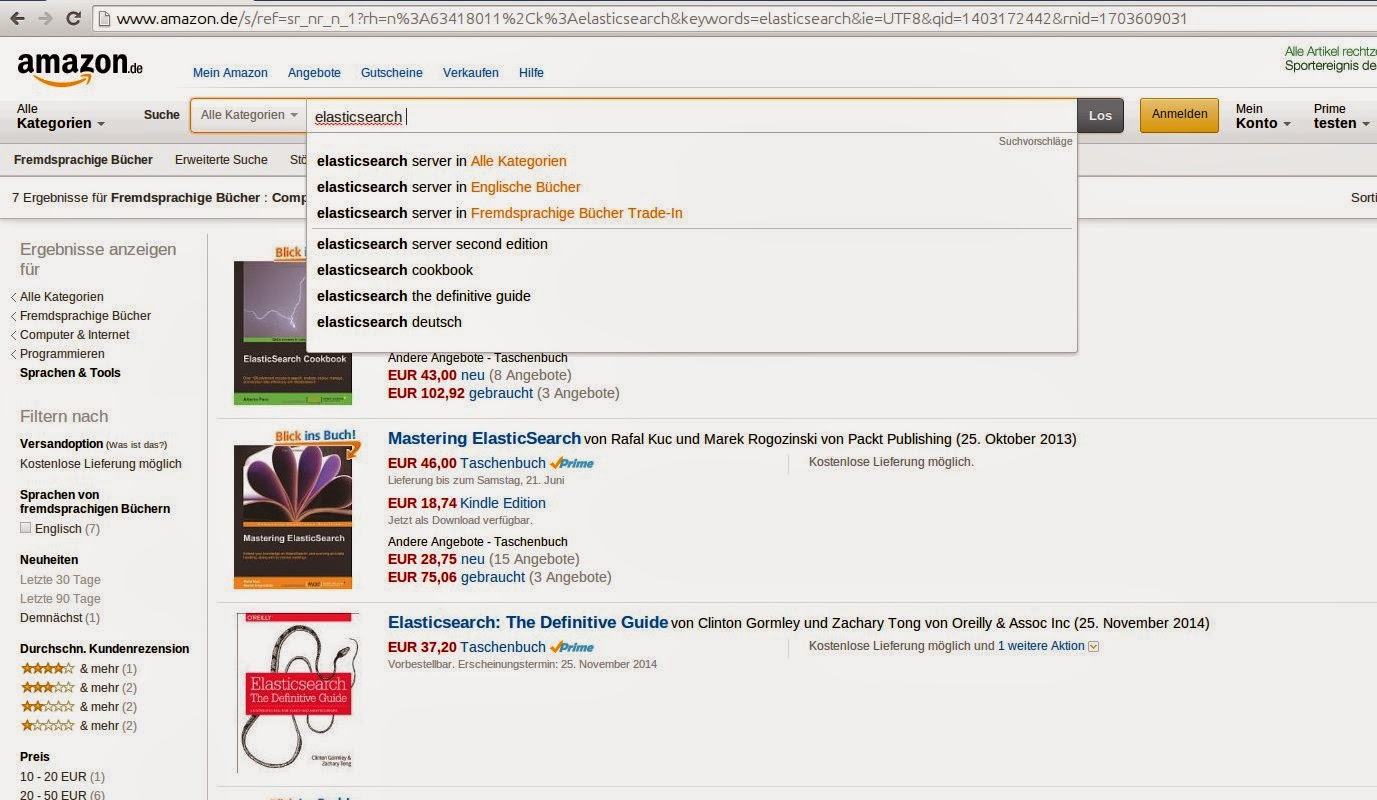
该界面看起来类似于Google的界面。 用户可以输入然后搜索的关键字。 但是也有细微的差异。 亚马逊提供的建议更为高级,还暗示可能在其中找到术语的类别。结果显示也有所不同,包括结构化的视图。 所搜索文档的结构还用于确定左侧的构面,这些构面可用于基于某些条件过滤当前结果,例如,所有结果的成本在10到20欧元之间。 最后,当涉及到诸如在线商店之类的内容时,相关性可能意味着完全不同的东西。 通常,结果清单的顺序会受到供应商的影响,或者用户可以按价格或发布日期等标准对结果进行排序。
尽管Google和Amazon均未使用Elasticsearch,但您可以使用它来构建类似的解决方案。
在Elasticsearch中搜索
与其他所有内容一样,可以使用HTTP搜索Elasticsearch。 在最简单的情况下,可以将_search端点附加到URL并添加一个参数 : curl -XGET "http://localhost:9200/conferences/talk/_search?q=elasticsearch⪯tty=true" 。 然后,Elasticsearch将按照相关性对结果进行响应。
{
"took" : 81,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.067124054,
"hits" : [ {
"_index" : "conferences",
"_type" : "talk",
"_id" : "iqxb7rDoTj64aiJg55KEvA",
"_score" : 0.067124054,
"_source":{
"title" : "Anwendungsfälle für Elasticsearch",
"speaker" : "Florian Hopf",
"date" : "2014-07-17T15:35:00.000Z",
"tags" : ["Java", "Lucene"],
"conference" : {
"name" : "Java Forum Stuttgart",
"city" : "Stuttgart"
}
}
} ]
}
}尽管我们已经搜索了某种类型,但是您也可以搜索多种类型或多种索引。
添加参数很容易,但是搜索请求可能变得更加复杂。 我们可能会要求根据标准突出显示或过滤文档。 Elasticsearch并没有为所有内容使用参数,而是提供了所谓的Query DSL ,这是在请求正文中传递并使用JSON表示的搜索API。
该查询可能是用户尝试搜索elasticsearch但却误输入了一部分的结果。 结果经过过滤,因此仅返回斯图加特市的会议讨论。
curl -XPOST "http://localhost:9200/conferences/_search " -d'
{
"query": {
"match": {
"title" : {
"query": "elasticsaerch",
"fuzziness": 2
}
}
},
"filter": {
"term": {
"conference.city": "stuttgart"
}
}
}'这次我们正在索引会议中查询所有类型的所有文档。 查询对象请求一个常见查询,即文档标题字段上的匹配查询 。 查询属性包含用户将传递的搜索词。 模糊属性要求我们还应该查找包含与所请求术语相似的术语的文档。 这将照顾到拼写错误的术语,并返回包含elasticsearch的结果。 筛选器对象要求应根据会议所在的城市筛选所有结果。 应尽可能使用过滤器,因为它们可以被缓存,并且不计算相关性,这会使它们更快。
规范化文字
随着搜索无处不在,用户对它应该如何工作也抱有一些期望。 他们可能会使用仅与文档中的术语相似的术语,而不是发布完全匹配的关键字。 例如,用户可能正在查询术语curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true" ,该术语是所包含术语curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true"的单数形式,这意味着用例在德语中: curl -XGET "http://localhost:9200/conferences/talk/_search?q=title:anwendungsfall⪯tty=true"
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 0,
"max_score" : null,
"hits" : [ ]
}
}没有结果。 我们可以尝试使用上面已经看到的模糊搜索来解决这个问题,但是有更好的方法。 我们可以在索引编制过程中对文本进行规范化,以便两个关键字都指向文档中的同一术语。
Lucene,Elasticsearch中的库搜索和存储是通过提供用于搜索的基础数据结构,即反向索引来实现的。 术语会映射到它们所包含的文档中。称为分析的过程用于拆分传入的文本并添加,删除或修改术语。

在左侧,我们可以看到两个已建立索引的文档,在右侧,我们可以看到将术语映射到包含它们的文档的倒排索引。在分析过程中,文档的内容按照特定于应用程序的方式进行拆分和转换因此可以将其放入索引中。 在这里,文本首先在空格或标点符号上分割。 然后所有字符都小写。 在最后一步中,采用依赖于语言的词干来尝试找到术语的基本形式。 这就是将我们的Anwendungsfälle转变为Anwendungsfall的原因。
在分析期间执行哪种逻辑取决于您的应用程序数据。 分析过程是确定搜索质量的主要因素之一,您可以花很多时间进行搜索。 有关更多详细信息,您可能需要看一下我关于索引数据的绝对基础的文章。
在Elasticsearch中,如何分析字段取决于类型的映射。 上周,我们看到我们可以在Elasticsearch中索引不同结构的文档,但是正如我们现在所看到的,Elasticsearch并非完全没有架构。 某个领域的分析过程只能确定一次,并且不容易更改。 您可以添加其他字段,但通常不更改现有字段的存储方式。
如果您不提供映射,Elasticsearch将对您索引的文档进行一些有根据的猜测。 它将查看在索引编制过程中看到的任何新字段,并尽其所能。 就我们的标题而言,它使用StandardAnalyzer,因为它是一个字符串。 Elasticsearch不知道我们的字符串使用哪种语言,因此它不会进行任何词干处理,这是一个很好的默认设置。
要告诉Elasticsearch使用GermanAnalyzer代替,我们需要添加一个自定义映射。 我们首先删除索引,然后再次创建它:
curl -XDELETE "http://localhost:9200/conferences/"
curl -XPUT "http://localhost:9200/conferences/“然后,我们可以使用PUT映射API传入我们类型的映射。
curl -XPUT "http://localhost:9200/conferences/talk/_mapping" -d'
{
"properties": {
"tags": {
"type": "string",
"index": "not_analyzed"
},
"title": {
"type": "string",
"analyzer": "german"
}
}
}'我们仅提供了两个字段的自定义映射。 Elasticsearch将再次猜测其余字段。 创建生产应用程序时,您很可能会预先映射所有字段,但不相关的字段也可以自动映射。 现在,如果我们再次为文档建立索引并搜索单数,将找到该文档。
高级搜索
除了我们在这里看到的功能外,Elasticsearch还提供了更多功能。 您可以使用聚合自动收集结果方面,我们将在以后的文章中介绍这些聚合。 建议者可用于为用户执行自动建议,可突出显示术语,可根据字段对结果进行排序,您可以对每个请求进行分页……。 随着Elasticsearch在Lucene的基础上发展,构建高级搜索应用程序的所有优势均已存在。
结论
搜索是Elasticsearch的核心部分,可以与其分布式存储功能结合使用。 您可以使用DSL查询来构建表达性查询。 分析是搜索的核心部分,可以通过为类型添加自定义映射来影响分析。 Lucene和Elasticsearch提供了许多高级功能,可将搜索添加到您的应用程序中。
当然,由于Elasticsearch的搜索功能和分布特性,有很多用户正在使用Elasticsearch。 GitHub使用它来让用户搜索存储库 , StackOverflow在Elasticsearch中索引其所有问题和答案 , SoundCloud则在歌曲的元数据中进行搜索。
在下一篇文章中,我们将研究Elasticsearch的另一方面:使用它来索引地理数据,这使您可以按位置和距离对结果进行过滤和排序。
翻译自: https://www.javacodegeeks.com/2014/07/use-cases-for-elasticsearch-full-text-search.html















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









