





 Disruptor是一个高性能的消息传递库,基于环形缓冲区数据结构。环形缓冲区是一种线性数据结构,允许在多线程环境中进行高效的数据传递。在Disruptor中,环形缓冲区解决了消息的多播和同步问题,通过单作家原则避免了写冲突,实现了无锁并发。Disruptor利用内存屏障和CAS操作提高性能,同时支持预分配和批处理以减少垃圾回收。
Disruptor是一个高性能的消息传递库,基于环形缓冲区数据结构。环形缓冲区是一种线性数据结构,允许在多线程环境中进行高效的数据传递。在Disruptor中,环形缓冲区解决了消息的多播和同步问题,通过单作家原则避免了写冲突,实现了无锁并发。Disruptor利用内存屏障和CAS操作提高性能,同时支持预分配和批处理以减少垃圾回收。
disruptor
环形缓冲区– Disruptor背后的数据结构
Disruptor是一个高性能的库,用于在线程之间传递消息,该库由LMAX Exchange公司于几年前开发和开源。 他们创建了此软件来处理其零售金融交易平台中的巨大流量(超过600万TPS)。 在2010年,他们惊讶于每个人通过在单个线程上执行所有业务逻辑,他们的系统能达到多快的速度。 尽管在解决方案中一个线程是一个重要概念,但Disruptor(这不是业务逻辑的一部分)可以在多线程环境中工作。 Disruptor基于环形缓冲区,这绝对不是一个新概念。
环形缓冲区
环形缓冲区有很多名称。 您可能听说过循环缓冲区,循环队列或循环缓冲区。 他们的意思都是一样的。 它基本上是一个线性数据结构,其中端点指向结构的开头。 很容易将其视为没有结尾的圆形数组。
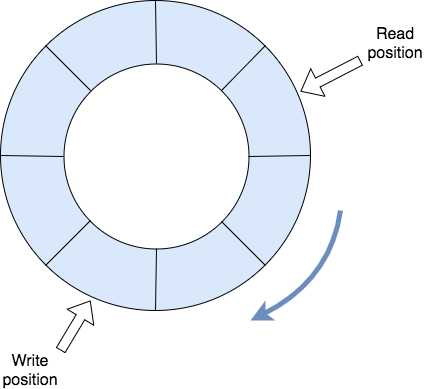
可以想象,环形缓冲区通常用作队列。 它具有读写位置,分别由消费者和生产者使用。 当读或写索引到达基础数组的末尾时,它将被设置回0。此活动通常称为“环绕”,并且需要更多说明。
环绕
考虑以下情况:我们在数组的末尾具有写入索引,而在数组的开始处具有读取索引。 包裹起来安全吗?

好吧,很容易想象一个流媒体的例子,其中不再需要过时的数据,因为不断有更新的和更相关的数据出现,但是通常,我们确实关心尚未处理的数据。 如果是这种情况,则返回错误的布尔值或阻塞(如传统的有界队列一样)都可以。 如果这些解决方案都不满足我们的要求,我们可以实现一个环形缓冲区,该缓冲区可以调整自身大小(但只有在缓冲区满时才可以调整大小,而不仅仅是生产者到达数组末尾并且可以安全地环绕)。 调整大小将需要将所有元素移动到新分配的更大数组(如果将数组用作基础数据结构),这当然是昂贵的操作。
干扰器中的环形缓冲区
环形缓冲区在Disruptor中解决什么问题? 让我们看一下Disruptor的典型用例:
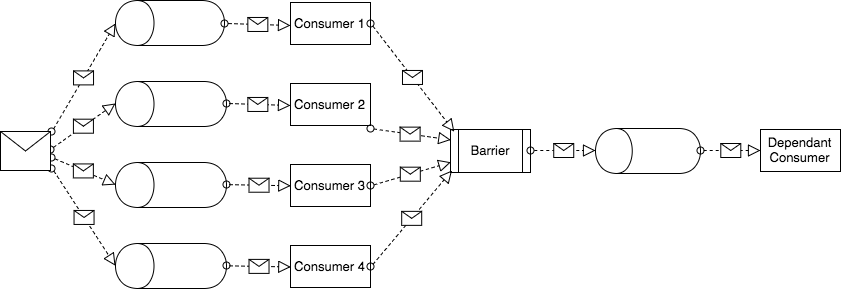
如您所见,我们将一条消息发送到多个使用者的输入队列(1-4)–因此,这是一个典型的多播(一种发布和订阅语义)。 然后我们遇到了障碍–我们希望所有消费者在继续下一步之前完成对消息的处理。 传递障碍后,消息将转到最后一个使用者的输入队列。 总而言之,我们有四个在相同数据上运行的独立(因此可能是并行的)任务(消费者1-4)和一个任务(从属消费者),这要求所有之前的任务都必须先完成才能开始工作。
在这种架构中,环形缓冲区在哪里? 好吧,环形缓冲区实际上就是这种架构。
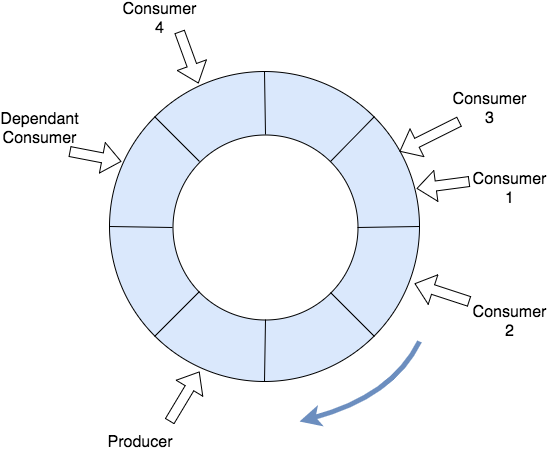
假设一条消息是环形缓冲区中的单个项目。 环形缓冲区代表我们的实际队列(如果您愿意,可以代表多个下游队列)。 每个使用者都是一个遍历循环缓冲区的单独线程(如果愿意,也可以使用队列中的消息)。
屏障的实现方式是:从属消费者无法越过需要开始处理环形缓冲区项目(消息)之前需要完成的任何消费者。
单作家原则
即使使用Disruptor的最有效方法是拥有一个生产者和多个消费者,但多生产者场景也是可能的。 在这种情况下,同一游标上可能存在写争用。 Disruptor并没有使用传统的锁来解决此问题-因此它是无锁的( BlockingWaitStrategy除外)。 相反,它依赖于内存屏障和/或高性能CAS操作。
如果从属消费者需要以前的任何消费者产生的某些数据怎么办? 消费者是否还可以修改环形缓冲区中的商品并因此成为作家? 事实证明,这里使用了一个非常简单的规则–环形缓冲区中的每个项目都由一组字段组成,并且每个字段最多具有一个允许其写入的使用者。 这样可以防止使用者之间发生任何写争用。
摘要
还有许多其他因素可以使Disruptor快速运行,例如:
- 以批处理方式使用消息
- 使用环形缓冲区中的数据局部性,CPU缓存友好的优势
- 在环形缓冲区中预先分配消息,以避免频繁垃圾回收项目(因此可以重复使用)
正如我在这里所解释的,即使环形缓冲区是一个相对简单的数据结构,它也可以轻松地用于实现更复杂的场景,而Disruptor只是一个示例。
翻译自: https://www.javacodegeeks.com/2017/12/ring-buffer-data-structure-behind-disruptor.html
disruptor















 38
38

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









