







Disruptor是如何做到如此高性能的?其底层依赖了哪些数据结构和算法?
1.基于循环队列的“生产者-消费者模型”
循环队列这种数据结构,就是我们今天要讲的内存消息队列的雏形.
实现最简单的“生产者-消费者模型”。
public class Queue {
private Long[] data;
private int size = 0, head = 0, tail = 0;
public Queue(int size) {
this.data = new Long[size];
this.size = size;
}
public boolean add(Long element) {
if ((tail + 1) % size == head) return false;
data[tail] = element;
tail = (tail + 1) % size;
return true;
}
public Long poll() {
if (head == tail) return null;
long ret = data[head];
head = (head + 1) % size;
return ret;
}
}
public class Producer {
private Queue queue;
public Producer(Queue queue) {
this.queue = queue;
}
public void produce(Long data) throws InterruptedException {
while (!queue.add(data)) {
Thread.sleep(100);
}
}
}
public class Consumer {
private Queue queue;
public Consumer(Queue queue) {
this.queue = queue;
}
public void comsume() throws InterruptedException {
while (true) {
Long data = queue.poll();
if (data == null) {
Thread.sleep(100);
} else {
// TODO:...消费数据的业务逻辑...
}
}
}
}
2.基于加锁的并发“生产者-消费者模型”
无锁导致的后果:
-
多个生产者写入的数据可能会互相覆盖;
-
多个消费者可能会读取重复的数据。
可以对add方法加锁或采用CAS方式,不过导致速度变慢
3.基于无锁的并发“生产者-消费者模型”
Disruptor的实现思路:
-
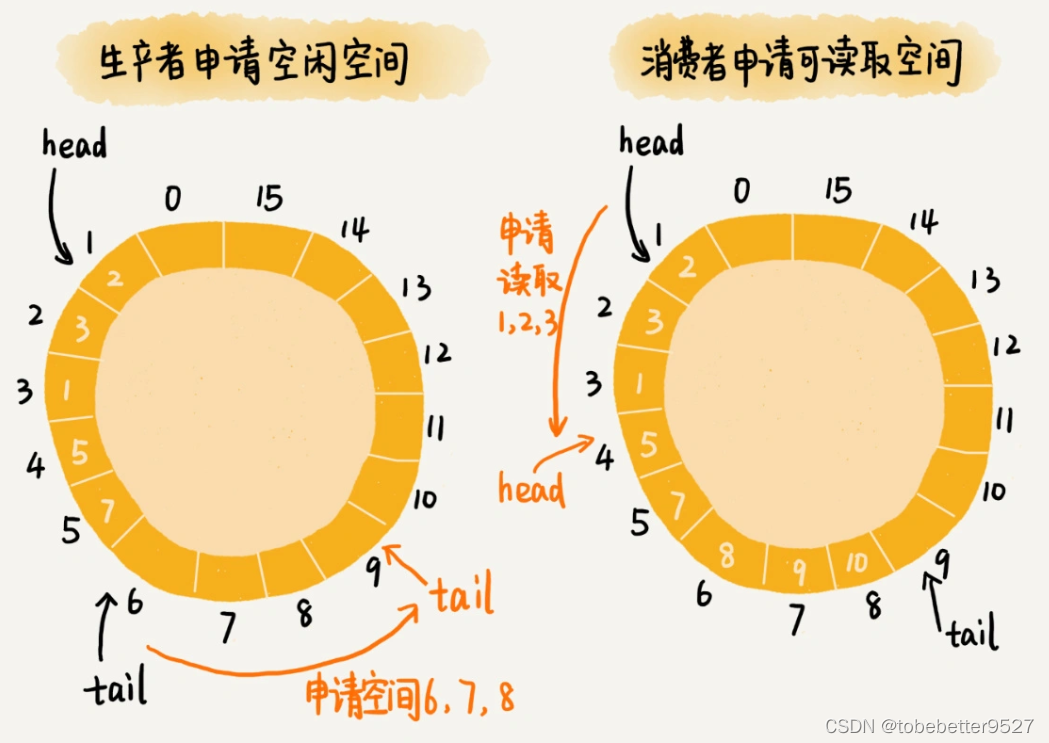
对于生产者,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的n个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,从刚刚的描述中,我们可以看出,申请存储单元的过程是需要加锁的。
-
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
-
不过,还有一个需要特别注意的地方,那就是,如果生产者A申请到了一组连续的存储单元,假设是下标为3到6的存储单元,生产者B紧跟着申请到了下标是7到9的存储单元,那在3到6没有完全写入数据之前,7到9的数据是无法读取的。这个也是Disruptor实现思路的一个弊端。















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









