





微服务调用微服务
您可能会说:“等等。 您已经写了一个博客, 告诉我微服务最困难的部分是我的数据 。 那么,最困难的部分是什么? 那? 或致电您的服务?”
实际上,微服务有很多困难的部分。 Blogosphere / conferencesphere / vendorspehere倾向于使微服务浪漫化,但是从技术角度来看,我们正在构建分布式系统。 分布式系统很难。
我与Red Hat的主要战略客户紧密合作,以帮助他们成功地解决这些难题,实施服务体系结构以保持竞争力,创新并成功地创造业务价值 。 我也非常关注开源社区中技术的发展速度。 跟我来@christianposta,因为我经常说/写/讨论这些话题。 但是我的背景是集成和异步消息传递,所以眼前的话题是我的内心深处和亲爱的:使用各种对话模式让服务彼此对话 。
当我们继续迭代围绕服务体系结构的这些概念时,不可避免地必须处理这些难题的主要根源。 我希望当您探索并开始实现微服务时,您已经看到并消化了分布式计算的谬论。 但是我也推荐Jeff Hodges的 “有关年轻血液的分布式系统的说明” 。
我觉得我们对某些问题的过去解决方案一直在追尾。 我们一直在寻找“我们如何让开发人员编写将交付价值并尝试抽象化分布式系统的业务逻辑”的圣杯。 我们通过使用本地接口(mmmm… CORBA , DCOM , EJB等)抽象化网络来完成使服务调用看起来像本地调用的工作。 但是后来我们知道这是个坏主意。 然后,我们转而使用诸如WSDL / SOAP /代码生成之类的方法来摆脱那些其他协议的脆弱性,但是我们继续相同的做法(SOAP客户端代码生成?)。 实际上,有些人确实使这些方法起作用,并且他们有很多伤痕要显示。 让我们看看简单地调用服务时遇到的一些问题:
- 故障或延迟
- 重试
- 路由
- 服务发现
- 可观察性

或延迟...
当我们向服务发送消息时会发生什么? 为了便于讨论,该请求被分解为较小的块并通过网络进行路由。
由于这种“网络”,我们处理了分布式计算的谬论。 我们的应用程序通过异步网络进行通信,这意味着对时间没有一个统一的理解。 服务以他们自己对“时间意味着”的理解为生,并且可能与其他服务不同。 更重要的是,这些异步网络根据路径的可用性,拥塞,硬件故障等来路由数据包。不能保证消息会在有限时间内到达其预期的收件人(请注意,“同步”网络,这些网络对时间有统一的了解。
太烂了。 现在,不可能确定失败或只是缓慢。 但是,如果客户要求在我们的售票网站上搜索音乐会,我们就不想等到宇宙消融之后。 我们希望做出响应,并且有时会失败请求。 因此,我们将超时添加到我们的服务中。 但是,不只是将超时添加到其服务中。
当您发出下游请求时,我们不能放慢速度,因为我们的下游流网络交互很慢。 需要考虑一些超时设置:
- 建立与下游服务的连接需要多少时间,我们才能发送请求
- 我们是否正在回复我们的要求
快速的旁注:将系统构建为服务体系结构的巨大优势是速度 ,其中包括对系统进行更改的速度。 我们重视系统的自治性和频繁部署。 但是,当我们这样做时,我们会很快发现自己处于超时无法正常工作的奇怪情况。
考虑到我们的客户端应用程序将超时设置为3s,以从推荐引擎获得响应。 但是推荐引擎也参考相关引擎。 因此,它以超时设置为2s进行呼叫。 这应该没问题,因为我们的上游服务呼叫最多等待3秒。 但是,如果相关引擎必须与促销服务对话,该怎么办? 如果超时最终设置为5s怎么办? 即使在潜在操作下,我们对相关性引擎的测试(单元,本地,集成)似乎也可以通过所有测试,这是因为我们的超时时间设置为5秒,并且升级服务用的时间不长,或者相关性引擎在结束后正常结束了通话超时时间过去了。
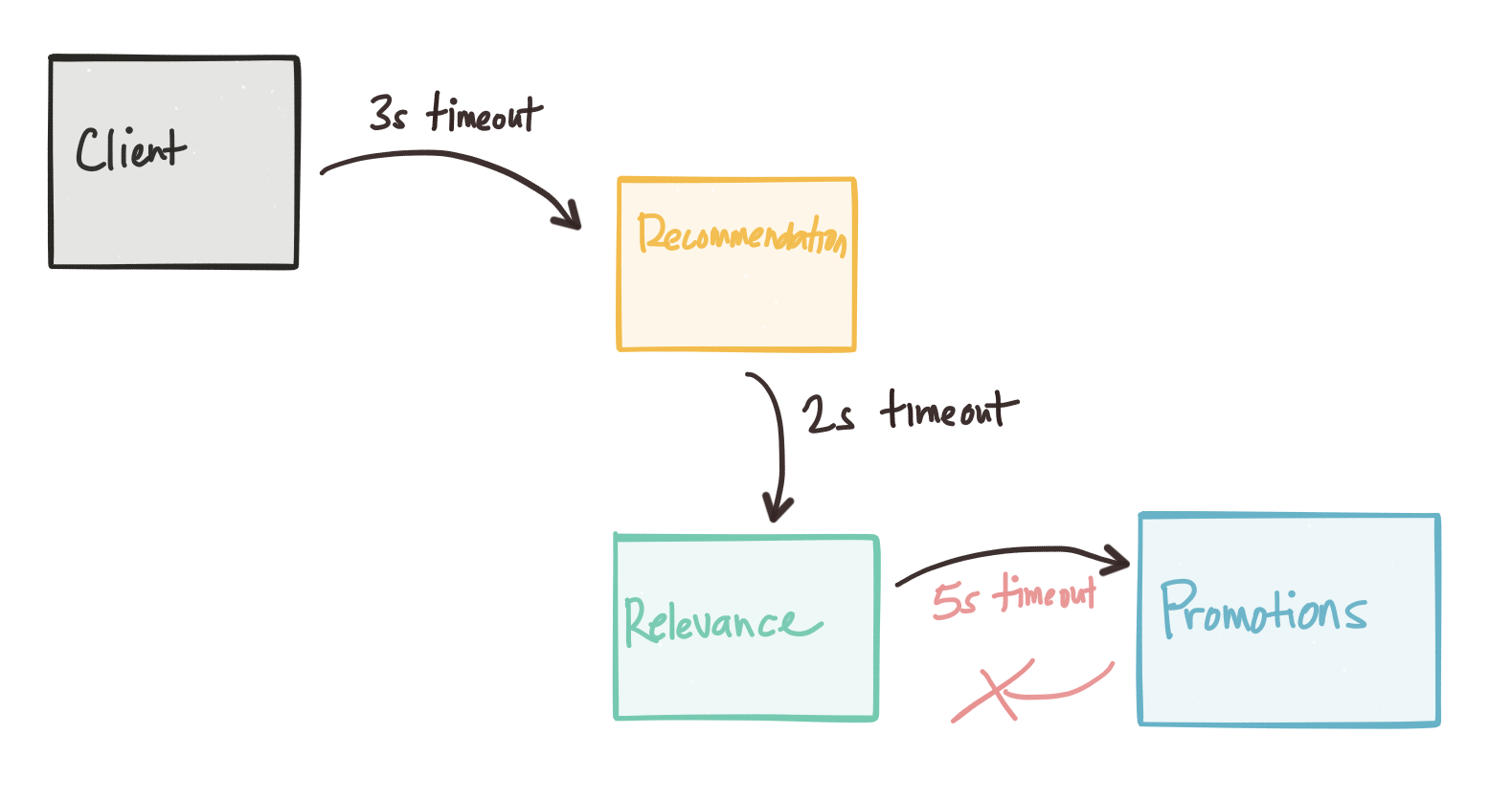
当大量的电话打进来时,我们最终遇到的是一个令人讨厌的,很难调试的情况(或没有……这可能随时发生,因为我们的网络是“异步的”吗?)。 超时很棒,直到超时为止。
重试
由于在分布式系统中我们确实没有任何限时保证,因此当事情花费太长时间时,我们将需要在某些时候超时。 现在,我们最终陷入“超时后该怎么办?”的情况。 我们是否向调用者抛出了讨厌的HTTP 5XX? 我们是否对3个简单的事情采取一些建议, 以使微服务具有弹性并承诺理论和后备? 还是我们重试?
如果重试,如果正在拨打一个更改下游服务上的数据的呼叫,该怎么办? 检查前面提到的3-easy-things博客,但是从我的博客(和相关的演讲) 的数据/一致性角度来看,我也涵盖了其中的一些内容, 微服务最困难的部分是我的数据 。
但是更有趣的是,如果我们的下游服务开始失败并且最终重试每个请求怎么办? 如果我们有10或100个推荐引擎实例称为关联引擎,但关联引擎正在超时,该怎么办? 我们最终得到了“ 雷电群问题”的一个变体。 即使我们尝试补救并慢慢恢复受影响的服务,这也最终终止了我们的服务。
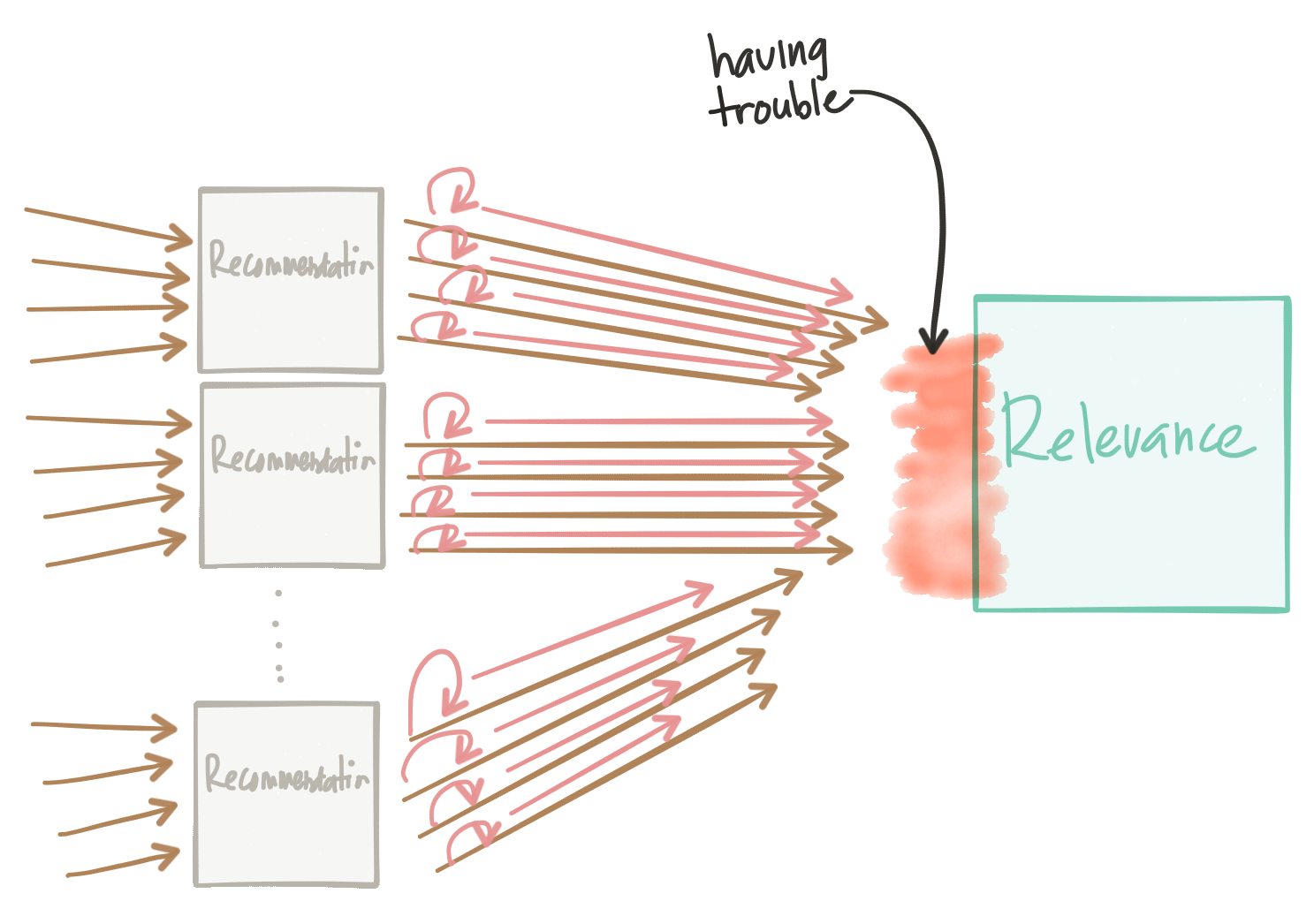
我们需要谨慎对待重试策略。 指数重试退避可以提供帮助,但可能仍然遇到相同的问题。
路由
因为我们牢记弹性来部署服务,所以理想情况下,我们有多个实例在不同的容错区域中运行,因此某些区域可能会发生故障,而不会降低我们服务的可用性。 但是随着事情开始失败,我们需要一种解决这些失败的方法。 但是我们可能还有其他原因在容错区域之间/之间进行业务流量路由。 也许某些“区域”被实现为我们的服务的地理部署,作为备份; 从延迟的角度来看,也许在正常操作期间无法让我们的流量流向我们的备份实例就太昂贵了。 也许总是以这种方式路由流量会花费太多金钱。 因此,我们可能希望围绕这些考虑因素来调整流量。
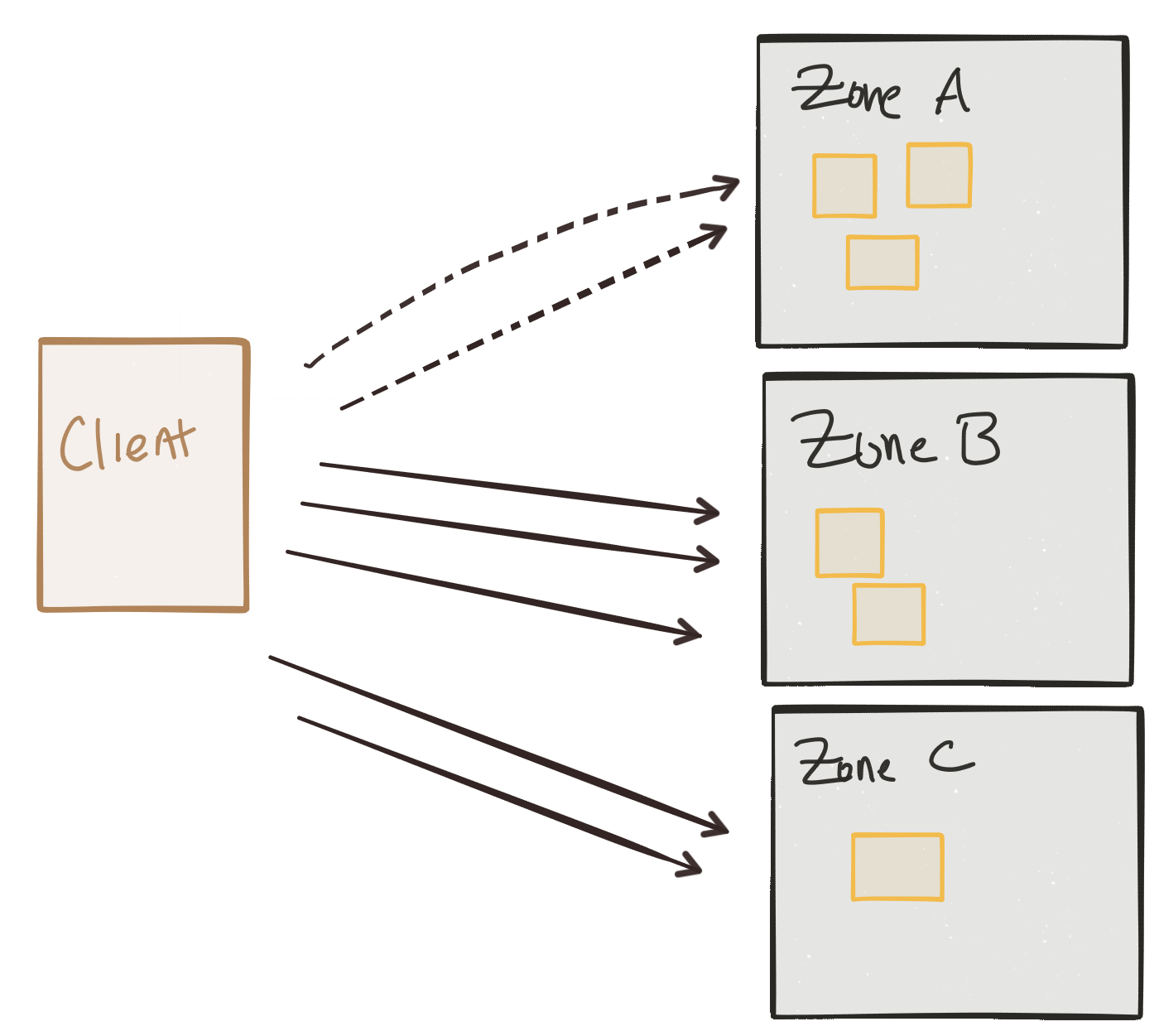
也许您想像这样路由入口客户端流量,但是服务间通信呢? 为了彼此之间满足客户请求而必须相互交谈的服务之间出于相同考虑而进行的路由呢?
容错区域之间的路由变化可能是围绕异常服务的路由或负载均衡请求,或者是周期性缓慢的服务? 我们希望将路由调整为可以跟上我们的服务电话的服务。 继续将流量发送到似乎无法跟上的服务几乎没有意义。
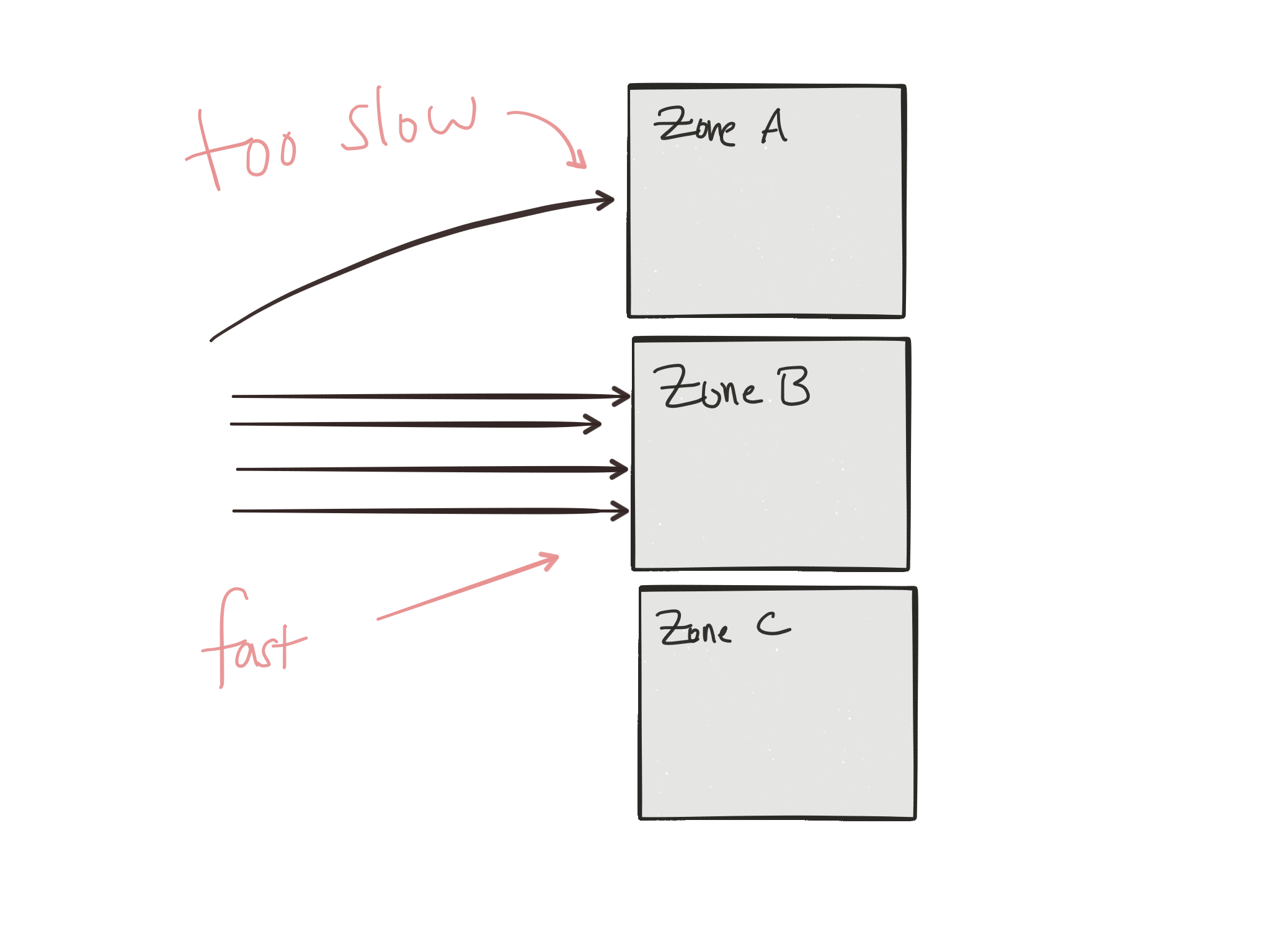
当我们谈论如何部署新版本的服务时,我们可以讨论路由的更多技巧。 如前所述,我们希望在服务之间保持一定程度的自主权,以便我们可以快速迭代并推出更改。 我们希望不中断我们的依赖服务,因此,如果我们可以将部分流量路由到我们的新版本,并将其绑定到我们的构建和发布策略中(例如, 蓝/绿,A / B测试,金丝雀发布 ) ,该怎么办? 。 这变得很快。 我们如何确定要路由的流量? 也许我们正在生产中使用的临时“临时环境”中进行测试。 也许我们只是在进行一次未宣布/黑暗的发布。 也许是A / B测试。 但是如果我们涉及某种状态怎么办。 我们需要考虑数据模式的演变,多版本数据库的实现等。
服务发现
除了前面讨论的一些弹性考虑因素之外,在一个预期会失败的环境中,我们如何发现我们的协作者服务? 我们如何知道他们在哪里以及如何与他们交谈? 在传统的静态拓扑中,我们的应用程序将配置有我们需要与之交谈的服务的URL / IP。 我们还将构建这些依赖服务以“永不失败”。 但是不可避免地,它们会以某些无法预料的方式失败(或部分失败)。 但是在弹性的环境中,应该期望我们合作者的这种行为。 这些下游服务可以自动扩展,重塑到不同的容错区域,或者只是被某些自动化杀死并重新启动。 这些服务的客户端需要能够在运行时发现它们并使用它们,而与拓扑的外观无关。
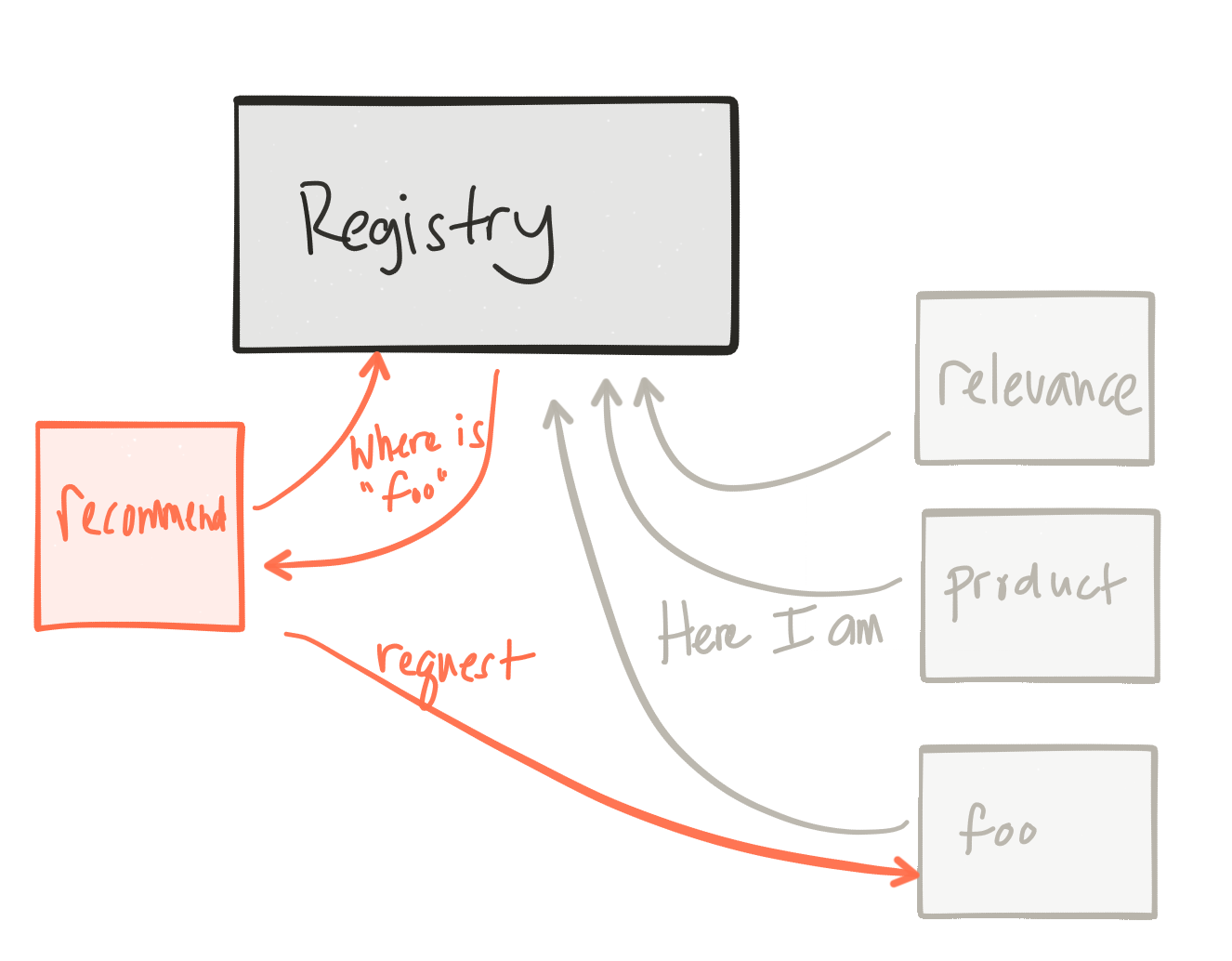
这不是要解决的新问题,但是在弹性环境中变得困难。 像DNS之类的东西根本不起作用(除非您很幸运能够在Kubernetes中运行:) )。
信任您的服务架构
我已将最重要的考虑因素/问题留到了最后。 微服务是关于快速对系统进行更改。 如果您不信任自己的系统,那么您将不愿意对其进行更改。 您将放慢版本。 如果部署速度较慢,则意味着周期时间会更长。 这意味着您可能会尝试部署更大的更改。 您将需要团队之间的更多协调。 您将开发出“这就是我们一直以来所采取的态度”,直到您抑制了企业的IT能力。 听起来有点熟?
您需要信任您的系统架构。 有了整体,您至少可以相信是否将“整体中的某个地方”搞砸了。 在服务体系结构中,所有赌注都没有了。 您怎么知道事情失败了怎么办? 您可能具有基础结构(物理/虚拟私有/公共/都属于..容器?)的一些复杂组合,并且中间件,服务,框架,语言和每种服务都有自己的发布节奏,无数种部署。 如果请求“缓慢”,您甚至从哪里开始?
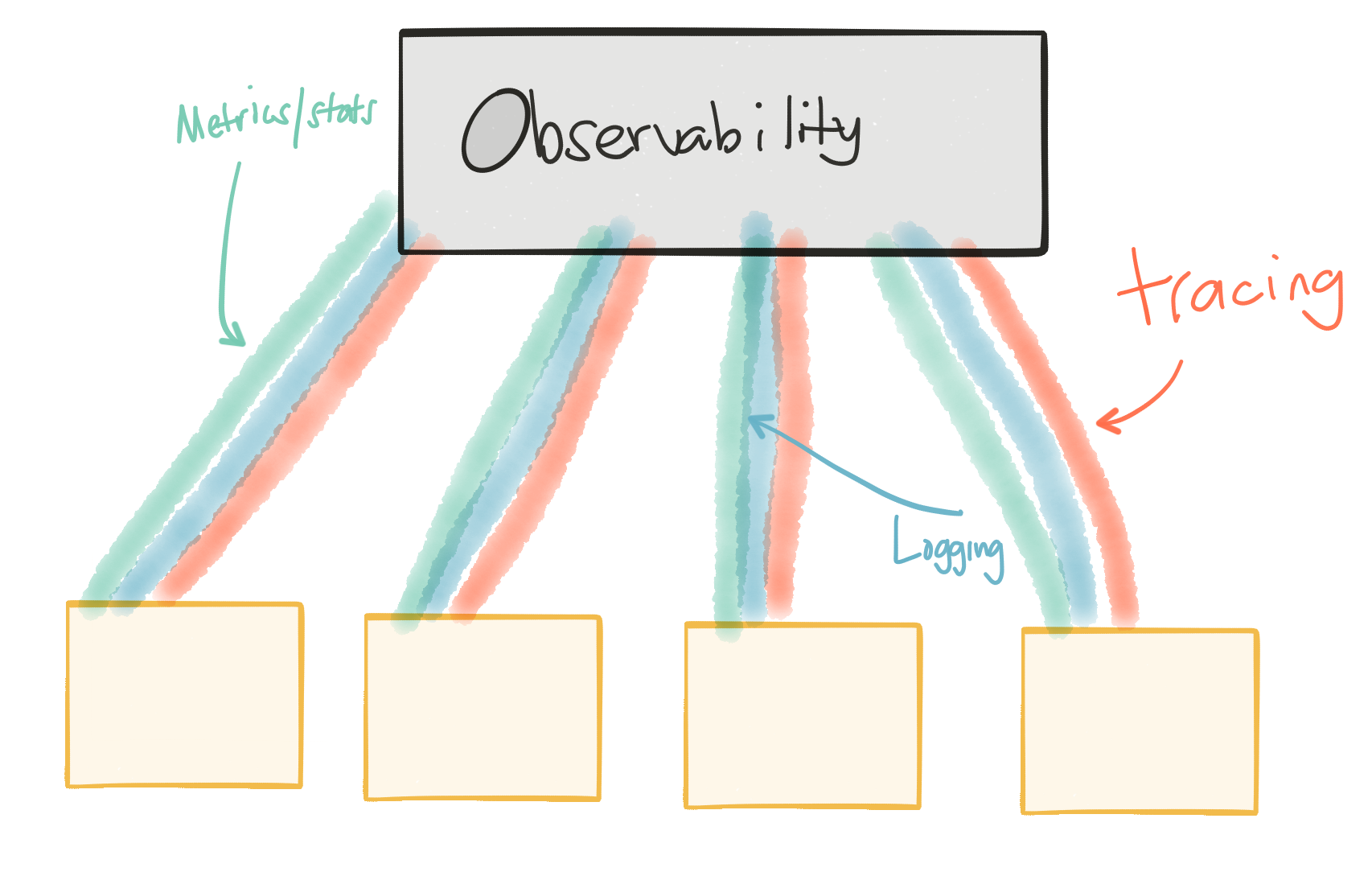
您的系统需要强大的“可观察性”。 您需要有用/有效的日志记录,指标和跟踪。 如果我们要快速迭代和发布服务,则需要以数据为驱动力,了解更改的影响,在有意义的地方回滚,或者快速发布新版本以解决负面观察。 我们系统的所有部分都必须能够提供可靠的可观察性(日志记录/度量标准/跟踪)。 我们对数据的信任程度越高,我们对服务体系结构的信任程度就越高,对更改的信心就越大。
回顾一下:我们正在解决……
因此,回顾一下……并进行更深入的研究,当我们的服务调用其他服务时,我们需要解决以下问题:
- 服务发现
- 自适应路由/客户端负载平衡
- 自动重试
- 超时控制
- 背压
- 限速
- 指标/统计信息收集
- 追踪
- A / B测试/流量调整/请求屏蔽
- 服务重构/请求屏蔽
- 跨服务调用执行服务截止日期/超时
- 服务之间的安全性
- 边缘网关/路由器
- 手术/精细/按请求路由
- 强制服务隔离/离群值检测
- 故障注入(即,注入延迟?丢弃入口/出口数据包?)
- 内部发布/黑暗发布
别人做了什么?
如果您看看Google / Twitter / Amazon / Netflix员工是如何解决此问题的,那么您可以说他们蛮力地为此提出了解决方案。 他们(简单的解释)基本上说:“好吧,我们将使用Java / C ++ / Python并投入无数的蛮横的工程技术来构建库来帮助我们的开发人员解决这个问题。” Google创建了Stubby。 Twitter 创建了Finagle ,Netflix创建了Netflix OSS并将其开源。等等,其他人也这样做了,尽管可能不像某些互联网公司那样在投资水平和投资额上。 甚至我们(fabric8团队)也使用原始的Fabric8.io 1.x(已弃用)进行了此操作。
对于其他任何人,此方法都有一个大问题:
您不是Netflix。
我的意思不是居高临下。 我只是说,投资大量的工程/金钱来解决这些问题的方法是不切实际的。 我们看到对微服务感兴趣的公司类型有兴趣这样做,以实现价值加速和创新。 这是他们没有专门知识的领域。
所以也许您可以重用他们的解决方案?
这导致了另一个非常有趣的问题:
您将得到一个非常复杂的,临时的,部分实现的解决方案
这样想吧。 我与之互动的许多客户都是Java商店。 他们考虑为Java服务解决此问题。 因此,自然而然地,他们倾向于Netflix OSS或Spring Cloud之类的东西。 棒极了! 但是他们的NodeJS服务呢? 那他们的Python服务呢? 他们的遗留应用程序如何? 我敢说他们的perl脚本怎么样?
每种语言对这些问题都有自己的实现。 每个都以不同的质量实现。 它不像获取开源库并将其填充到您的应用程序中那样简单。 您将必须测试和验证每个实现。 您负责服务体系结构,而不是这些库。 实现/语言/版本的这种泛滥的可能性很高,很快就会成为无法克服的复杂性。
我看到的另一种建筑气味:
我们正在应用层实现底层网络功能
我喜欢Buoyant的 Oliver Gould在谈到这些问题(路由,重试,速率限制,电路中断等)时真正讲到的第5层考虑:
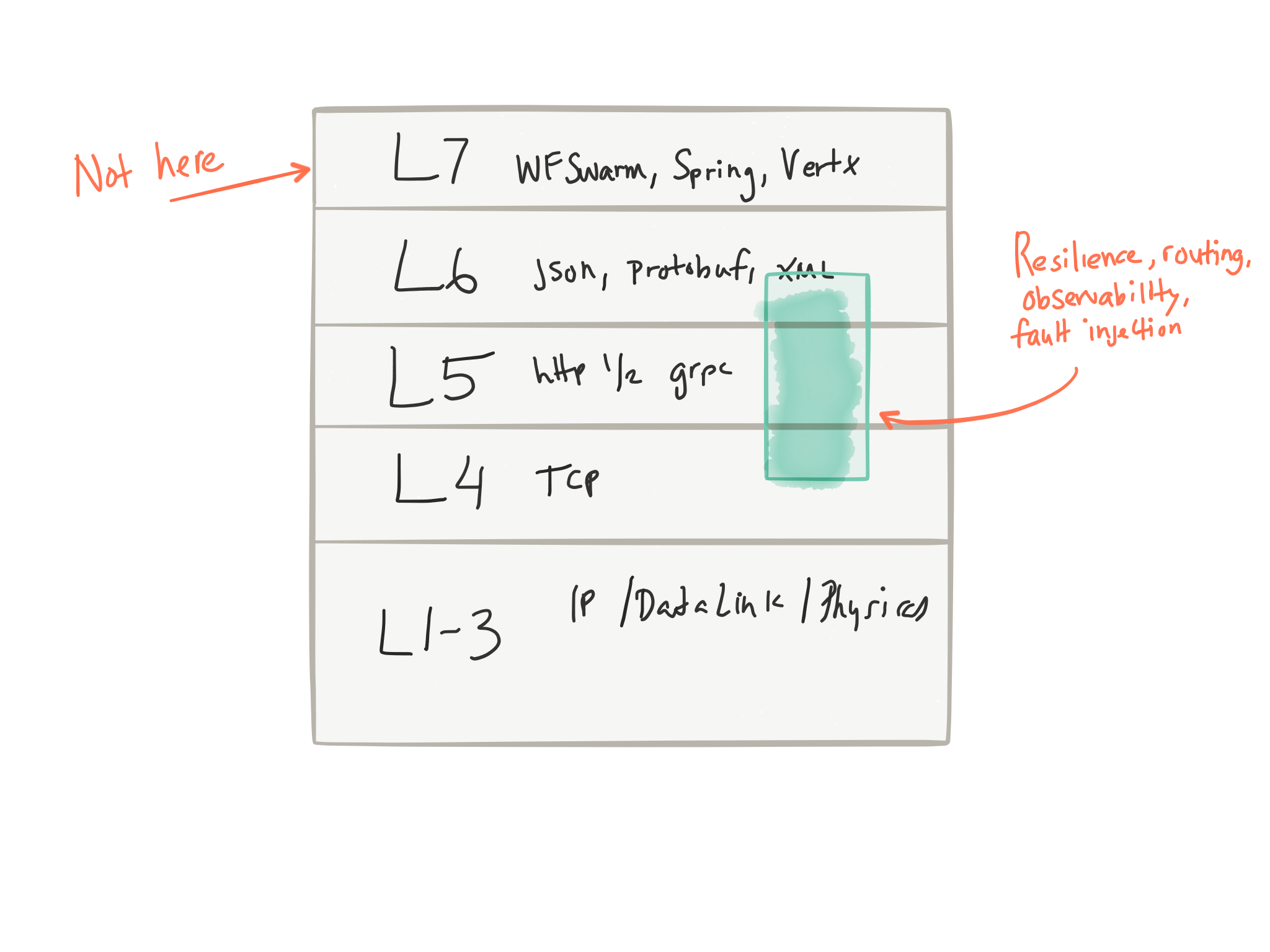
那么,为什么我们要将这些应用程序复杂化呢? 我们一直在尝试通过创建库来解决应用程序中的这些问题(创建一个用于断路的库,一个用于发现服务的库,一个用于跟踪的库,一个用于统计收集的库,甚至用于执行复杂路由的库,等)并将它们塞入我们的应用程序空间(如依赖项,可传递依赖项,库调用等)。 如果您的服务开发人员忘记添加此实现的一部分(例如跟踪),会发生什么? 因此,每个开发人员都有责任正确实施这些功能,引入正确的库,在其代码中组合它们,等等。
更不用说一些尝试通过Java空间中的注释的神奇配置来缓解这种情况的框架。 这样的方法会错过信任,可观察性,可调试性等目标。
正如我在“微服务2.0博客”中提到的那样,我偏爱能够以更优雅的方法做到这一点的实现。
那那把我们留在哪里呢?
恕我直言,这是服务代理/边车模式可以提供帮助的地方。 如果我们可以解决这些约束:
- 如果有的话,减少对普通库的任何应用程序级意识
- 在一个地方实现所有这些功能,而不是一味依赖
- 使可观察性成为一流的设计目标
- 对我们的服务(包括旧版服务)透明
- 对开销/资源的影响非常低
- 适用于任何/所有语言/框架
- 将这些注意事项推到较低的堆栈级别(请参见上文)
……然后,我认为我们将为这些问题找到更优雅的解决方案。 问你自己:
接下来的几年中,我是否会使用5年前构建的技术来实现我的服务体系结构?
微服务先锋公司最近正在渗透一些有趣的技术,以实现服务代理边车模式:
在下一篇博客文章中,我们将详细介绍每个实现,更具体地说是如何在Kubernetes上使用它们。
对于这个博客,我已经筋疲力尽了,如果您一直关注我直到现在,非常感谢。 跟随我@christianposta,获取有关此主题的后续博客。
翻译自: https://www.javacodegeeks.com/2017/04/hardest-part-microservices-calling-services.html
微服务调用微服务















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









