





ruby elixir
Erlang已经存在了30多年,并且在多核CPU出现之前就已经很好地构建了。 但是,这是一种今天再没有相关性的语言! 该语言的基础体系结构非常适合于每台计算机和移动设备上的现代CPU。
我正在撰写本文的计算机具有2.2 GHz英特尔酷睿i7 CPU,但更重要的是它具有八个内核。 简而言之,它可以一次执行八个任务。
利用这些核心的能力在许多语言中都存在,但是常常感到不合时宜或充满陷阱和挑战。 如果您曾经担心过互斥 , 共享的可变状态和代码是线程安全的 ,那么您至少要注意几个陷阱。
在Erlang中,因此利用Erlang VM(BEAM)的Elixir,使编写和推理并发代码变得毫不费力。 Ruby有一些很棒的库可以帮助编写并发代码,而Elixir是内置的并且是一流的公民。
这并不是说编写高度并发或分布式的系统很容易。 离得很远! 但是有了Elixir,语言就在您身边。
进程,PID和邮箱
在开始研究如何在Elixir中编写并发代码之前,先了解一下我们将要使用的术语以及Elixir使用的并发模型是一个好主意。
演员模型
Elixir(和Erlang)中的并发基于Actor模型 。 Actor是单线程进程,可以在它们之间发送和接收消息。 Erlang VM管理它们的创建,执行和通信。 它们的记忆是完全隔离的,这使得不必担心“共享状态”是没有问题的。
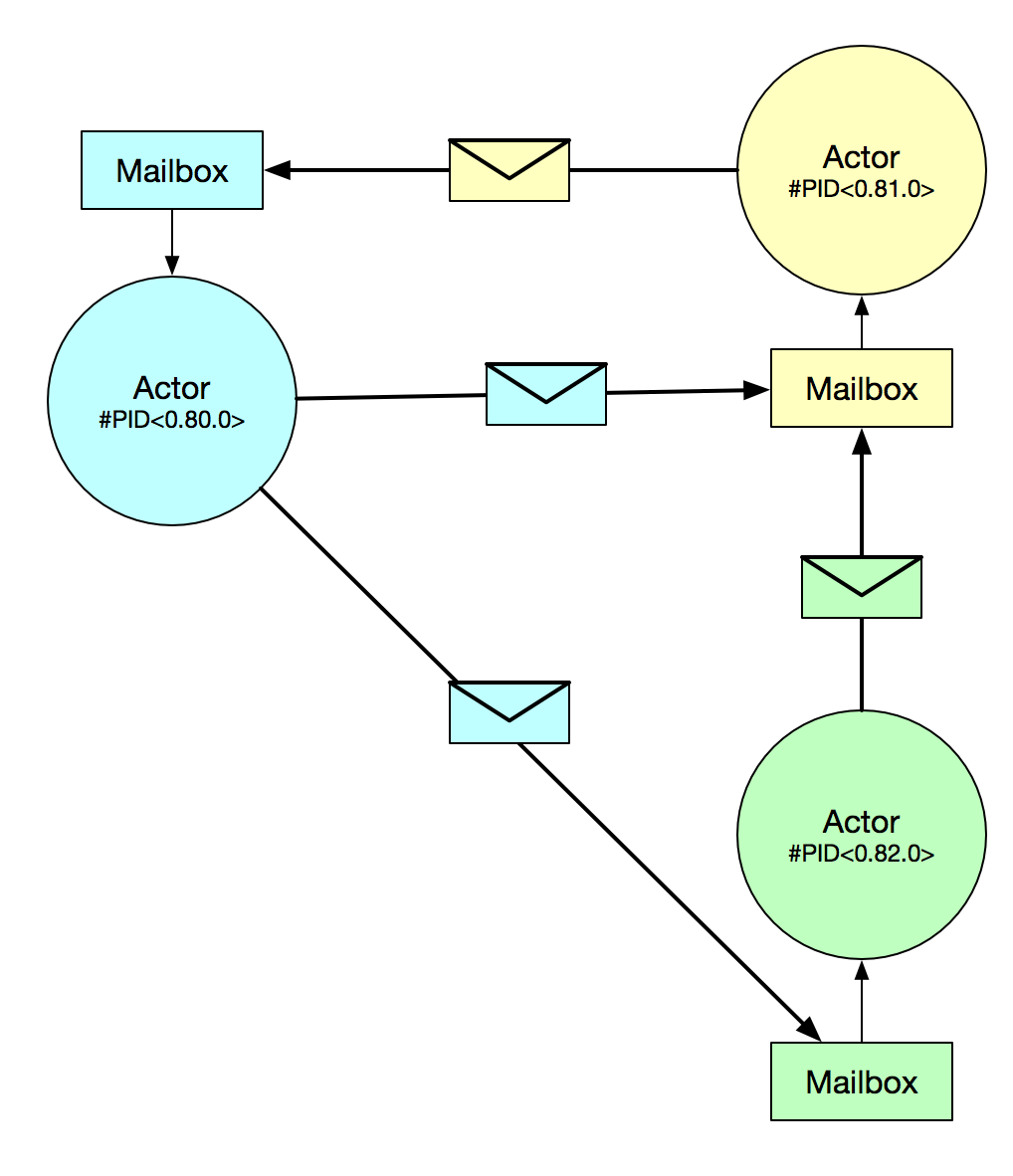
- 流程 :类似于OS级别的线程,但轻巧得多。 这本质上是Elixir中并发的单位。 进程由BEAM(Erlang运行时)管理,BEAM负责将工作分散到CPU的所有核心上,甚至跨网络上的其他BEAM节点进行。 一个系统可以一次拥有数百万个这样的进程,您不必担心会充分利用它们。
- 进程ID(PID) :这是对特定进程的引用。 就像Internet上的IP地址一样,PID是您告诉Elixir要将消息发送到哪个进程的方式。
- 邮箱 :为了使进程之间可以相互通信,将来回发送消息。 当消息发送到流程时,它到达该流程的邮箱。 接收坐在其邮箱中的邮件取决于该过程。
因此,将所有内容放在一起,Elixir中的一个过程就是演员。 它可以通过向特定的PID发送消息来与其他参与者进行通信。 收件人可以通过检查其邮箱中是否有新邮件来接收邮件。
编写并发代码
在本节中,我们将研究Elixir中如何实际使用并发的Actor模型。
建立流程
使用spawn或spawn_link函数创建一个新进程。 该函数接受匿名函数,该匿名函数将在单独的过程中调用。 作为响应,我们将获得一个进程标识符,通常称为PID。 如果我们想与此进程进行通信或向内核询问有关该进程的信息,则这一点很重要。
pid = spawn(fn -> :timer.sleep 15000 end)
#PID<0.89.0> Elixir中的所有内容都在一个流程中运行。 您可以通过调用self()函数找出当前进程的PID。 因此,即使在iex shell中,通过调用self()您也可以看到该iex会话的PID,例如#PID<0.80.0> 。
我们可以使用此PID向Elixir询问有关该过程的信息。 这是通过使用Process.info(pid)函数完成的。
Process.info(pid)
[current_function: {:timer, :sleep, 1}, initial_call: {:erlang, :apply, 2},
status: :waiting, message_queue_len: 0, messages: [], links: [],
dictionary: [], trap_exit: false, error_handler: :error_handler,
priority: :normal, group_leader: #PID<0.50.0>, total_heap_size: 233,
heap_size: 233, stack_size: 2, reductions: 43,
garbage_collection: [max_heap_size: %{error_logger: true, kill: true, size: 0},
min_bin_vheap_size: 46422, min_heap_size: 233, fullsweep_after: 65535,
minor_gcs: 0], suspending: []] 您可以在这里找到有趣的东西! 例如,在iex如果您要求提供有关自身Process.info(self()) ,则将看到您键入的命令的历史记录:
iex(1)> 5 + 5
iex(2)> IO.puts "Hello!"
iex(3)> pid = spawn(fn -> :timer.sleep 15000 end)
iex(4)> Process.info(self())[:dictionary][:iex_history]
%IEx.History.State{queue: {[
{3, 'pid = spawn(fn -> :timer.sleep 15000 end)\n', #PID<0.84.0>},
{2, 'IO.puts "Hello!"\n', :ok}],
[{1, '5 + 5\n', 10}]},
size: 3, start: 1}传送讯息
可以使用send功能将消息发送到进程。 您可以向其提供您希望向其发送消息的进程的PID以及正在发送的数据。 邮件被发送到接收进程的邮箱。
虽然发送只是成功的一半。 如果收件人不准备接收该消息,它将充耳不闻。 进程可以使用receive构造来接收消息,该模式在接收到的消息上匹配。
在下面的示例中,我们产生了一个等待接收消息的新进程。 一旦它在其邮箱中收到一条消息,我们就将其简单地输出到屏幕上。
pid = spawn(fn ->
IO.puts "Waiting for messages"
receive do
msg -> IO.puts "Received #{inspect msg}"
end
end)
send(pid, "Hello Process!")使我们的过程保持活力
当进程不再有任何代码可执行时,该进程将退出。 在上面的示例中,该过程将一直保持活动状态,直到收到第一条消息,然后退出。 因此,问题就来了:我们如何获得一个长期运行的过程?
我们可以利用loop递归调用自身的loop函数来做到这一点。 此循环将仅接收一条消息,然后调用自身以等待下一条消息。
defmodule MyLogger do
def start do
IO.puts "#{__MODULE__} at your service"
loop()
end
def loop do
receive do
msg -> IO.puts msg
end
loop()
end
end
# This time we will spawn a new processes based on the MyLogger module's method `start`.
pid = spawn(MyLogger, :start, [])
send(pid, "First message")
send(pid, "Another message")维持状态
我们当前的过程不会跟踪任何状态。 它仅执行其代码,而不保留任何额外的状态或信息。
如果我们希望记录器跟踪某些统计信息,例如记录的消息数,该怎么办? 注意调用spawn(MyLogger, :start, []) ; 最后一个参数是一个空列表,实际上是可以传递给进程的args列表。 这充当“初始状态”或传递给入口点函数的内容。 我们的状态将只是一个跟踪我们已记录的消息数的数字。
现在,当调用init函数时,将传递数字0 。 在我们工作时,要跟踪此数字,始终将更新的状态传递到流程的下一个循环。
我们要做的另一件事是添加了记录器可以执行的其他操作。 现在,它可以记录消息并打印出统计信息。 为此,我们将以tuple发送消息,其中第一个值是表示我们希望流程执行的命令的atom 。 receive结构中的模式匹配使我们可以将一条消息的意图与另一条消息的意图区分开。
defmodule MyLogger do
def start_link do
# __MODULE__ refers to the current module
spawn(__MODULE__, :init, [0])
end
def init(count) do
# Here we could initialize other values if we wanted to
loop(count)
end
def loop(count) do
new_count = receive do
{:log, msg} ->
IO.puts msg
count + 1
{:stats} ->
IO.puts "I've logged #{count} messages"
count
end
loop(new_count)
end
end
pid = MyLogger.start_link
send(pid, {:log, "First message"})
send(pid, {:log, "Another message"})
send(pid, {:stats})重构为客户端和服务器
我们可以对模块进行一些重构,使其更加用户友好。 代替直接使用send函数,我们可以将详细信息隐藏在客户端模块的后面。 它的工作是将消息发送到运行服务器模块的进程,并有选择地等待同步调用的响应。
defmodule MyLogger.Client do
def start_link do
spawn(MyLogger.Server, :init, [0])
end
def log(pid, msg) do
send(pid, {:log, msg})
end
def print_stats(pid) do
send(pid, {:print_stats})
end
def return_stats(pid) do
send(pid, {:return_stats, self()})
receive do
{:stats, count} -> count
end
end
end 我们的服务器模块非常简单。 它由一个init函数组成,在这种情况下,除了启动loop函数循环外,它不会执行任何其他操作。 loop功能负责从邮箱接收消息,执行请求的任务,然后再次以更新后的状态循环。
defmodule MyLogger.Server do
def init(count \\ 0) do
loop(count)
end
def loop(count) do
new_count = receive do
{:log, msg} ->
IO.puts msg
count + 1
{:print_stats} ->
IO.puts "I've logged #{count} messages"
count
{:return_stats, caller} ->
send(caller, {:stats, count})
count
end
loop(new_count)
end
end 如果要使用下面的代码,则实际上不需要知道如何实现服务器。 我们直接与客户端进行交互,然后客户端将消息发送到服务器。 我为模块起了别名,以避免多次键入MyLogger.Client 。
alias MyLogger.Client, as: Logger
pid = Logger.start_link
Logger.log(pid, "First message")
Logger.log(pid, "Another message")
Logger.print_stats(pid)
stats = Logger.return_stats(pid)重构服务器
请注意,服务器接收到的所有消息都进行了模式匹配,以确定如何处理它们? 通过创建一系列在接收到的数据上进行模式匹配的“处理程序”函数,我们可以比拥有一个大型函数更好。
这不仅清理了我们的代码,还使测试变得更加容易。 我们可以简单地使用正确的参数调用单独的handle_receive函数,以测试它们是否正常工作。
defmodule MyLogger.Server do
def init(count \\ 0) do
loop(count)
end
def loop(count) do
new_count = receive do
message -> handle_receive(message, count)
end
loop(new_count)
end
def handle_receive({:log, msg}, count) do
IO.puts msg
count + 1
end
def handle_receive({:print_stats}, count) do
IO.puts "I've logged #{count} messages"
count
end
def handle_receive({:return_stats, caller}, count) do
send(caller, {:stats, count})
count
end
def handle_receive(other, count) do
IO.puts "Unhandled message of #{inspect other} received by logger"
count
end
end平行地图
对于最后一个示例,让我们看一下执行并行映射。
我们要做的是将URL列表映射到其返回的HTTP状态代码。 如果我们在没有任何并发的情况下执行此操作,那么我们的速度将是检查每个URL的速度之和。 如果我们有五个,每个都花了OE秒的时间,则大约需要五秒钟才能完成所有URL的检查。 但是,如果我们可以并行检查它们,那么时间将约为一秒钟,这是最慢的URL的时间,因为它们是同时发生的。
我们的测试实现如下所示:
defmodule StatusesTest do
use ExUnit.Case
test "parallel status map" do
urls = [
url1 = "http://www.fakeresponse.com/api/?sleep=2",
url2 = "http://www.fakeresponse.com/api/?sleep=1",
url3 = "http://www.fakeresponse.com/api/?status=500",
url4 = "https://www.leighhalliday.com",
url5 = "https://www.reddit.com"
]
assert Statuses.map(urls) == [
{url1, 200},
{url2, 200},
{url3, 500},
{url4, 200},
{url5, 200}
]
end
end现在开始执行实际代码。 我添加了注释,以使每个步骤都清晰明了。
defmodule Statuses do
def map(urls) do
# Put self into variable to send to spawned process
caller = self()
urls
# Map the URLs to a spawns process. Remember a `pid` is returned.
|> Enum.map(&(spawn(fn -> process(&1, caller) end)))
# Map the returned pids
|> Enum.map(fn pid ->
# Receive the response from this pid
receive do
{^pid, url, status} -> {url, status}
end
end)
end
def process(url, caller) do
status =
case HTTPoison.get(url) do
{:ok, %HTTPoison.Response{status_code: status_code}} ->
status_code
{:error, %HTTPoison.Error{reason: reason}} ->
{:error, reason}
end
# Send message back to caller with result
send(caller, {self(), url, status})
end
end当我们运行代码时,花了2.2秒。 这是有道理的,因为其中一个URL是伪造的URL服务,我们告诉我们将响应延迟两秒钟……因此,它花费了最慢的URL的时间。
然后去哪儿?
在本文中,我们介绍了生成新流程,发送该流程消息,通过递归循环维护流程状态以及从其他流程接收消息的基础知识。 这是一个好的开始,但还有更多!
Elixir带有一些非常酷的模块,可以帮助我们删除一些我们今天所做的样板。 Agent是用于维护流程状态的模块。 Task是用于同时运行代码并有选择地接收其响应的模块。 GenServer处理状态任务和并发任务。 我计划在本系列的第二篇文章中介绍这些主题。
最后是链接,监视和响应过程中可能发生的错误的整个主题。 Elixir为此配备了一个Supervisor模块,并且是构建可靠的容错系统的一部分。
翻译自: https://www.javacodegeeks.com/2017/02/concurrency-in-elixir.html
ruby elixir















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









