










1.搭建(DDD+RPC)架构
DDD——微服务架构(微服务是对系统拆分的方式)
(Domain-Driven Design 领域驱动设计)
DDD与MVC同属微服务架构
是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。
DDD分层

RPC接口:对外提供接口调用整个服务
DDD分层:(箭头是剪头尾对头的引用)
- 接口层:对内提供接口【接口调用应用层,应用层调用领域层】
- 基础层:对数据仓储服务【基础层引用领域层,领域层来定义仓储服务的接口,基础层去做仓储服务的实现】
- 领域层:(核心)封装具体业务功能
- 通用层:返回对象、枚举
- 应用层:逻辑包装
MVC与DDD区别
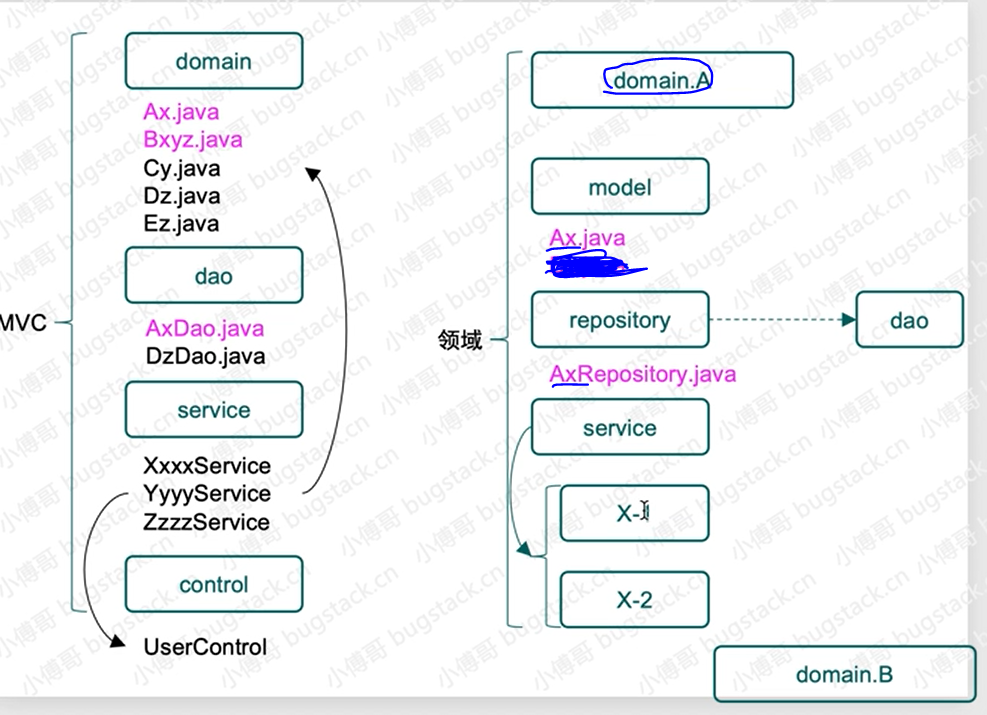
驱动设计模式:
具体来说,对于这么一个抽奖领域domain

【上图repository包】这里只定义接口,在基础层infrastructure进行实现。
model,用于提供vo、req、res 和 aggregates 聚合对象。
repository,对数据库,其实也就是对Mysql、Redis等数据的统一包装。
service,是具体的业务领域逻辑实现层,在这个包下定义了algorithm抽奖算法实现和具体的抽奖策略包装 draw 层,对外提供抽奖接口 IDrawExec#doDrawExec。
也就是说,这些model里的这些对象都是用于服务自己的领域,不会去服务其他领域。
为什么使用斐波那契散列索引(感觉有点怪多余)
为了尽量均匀散列减少碰撞
使用斐波那契散列索引,使用斐波那契计算能起到不错的散列效果。
1.抽奖策略领域模块开发
在domain抽奖领域模块实现两种抽奖策略算法,包括:单项概率抽奖和整体概率抽奖,并提供统一的调用方式。
使用单项概率。
总体概率(算法):
算法描述:分别把A、B、C对应的概率值转换成阶梯范围值,A=(0~0.2」、B=(0.2-0.5」、C=(0.5-1.0」,当使用随机数方法生成一个随机数后,与阶梯范围值进行循环比对找到对应的区域,匹配到中奖结果。
单项概率(算法):
算法描述:单项概率算法不涉及奖品概率重新计算的问题,那么也就是说我们分配好的概率结果是可以固定下来的。好,这里就有一个可以优化的算法,不需要在轮训匹配O(n)时间复杂度来处理中奖信息,而是可以根据概率值存放到HashMap或者自定义散列数组进行存放结果,这样就可以根据概率值直接定义中奖结果,时间复杂度由O(n)降低到O(1)。这样的设计在一般电商大促并发较高的情况下,达到优化接口响应时间的目的。
例:
两种抽奖算法描述,场景A20%、B30%、C50%
总体概率:如果A奖品抽空后,B和C奖品的概率按照 3:5 均分,相当于B奖品中奖概率由 0.3 升为 0.375
单项概率:如果A奖品抽空后,B和C保持目前中奖概率,用户抽奖扔有20%中为A,因A库存抽空则结果展示为未中奖。为了运营成本,通常这种情况的使用的比较多
对于极小概率比如1/1000000
那这种情况new一个长度大于1000000的数组然后散列进去那肯定不合适。请问有啥好的方法吗?
散列后的值做成一个key,写到redis里。只存有奖品的key,当没中奖的时候,查询对应的key是不存在的,而中奖的时候,查询当前的key是存在的。
2.模版模式处理抽奖流程
职责分离,标准定义。


配置类:配置抽奖策略
抽象接口方法:【抽奖执行接口】
抽奖数据支撑:支撑类继承配置类里的方法,并提供数据服务
抽象类:提供标准的执行流程***【模板】(上面几个部分这么分就是为了将抽象类瘦身,将标准流程)
实现类:针对情景的具体业务实现*(将会在这@Service("drawExec")业务逻辑的实现层)
整个实现过程流式:这样将接口间的职责进行分离,将接口间的功能职责分离;
模板模式应用
本章节最大的目标在于把抽奖流程标准化,需要考虑的一条思路线包括:
- 1根据入参策略ID获取抽奖策略配置
- 2校验和处理抽奖策略的数据初始化到内存
- 3获取那些被排除掉的抽奖列表,这些奖品可能是已经奖品库存为空,或者因为风控策略不能给这个用户薅羊毛的奖品
- 4执行抽奖算法
- 5包装中奖结果
1,2是基础配置,3,4是需要根据自身具体业务实现——所以定义抽象类等具体业务去实现
模板方法定义好标准流程后,其他开发人员格子各自开发自己的业务,不会破坏整体的开发结构。
关于模版模式的核心点在于由抽象类定义抽象方法执行策略,也就是说父类规定了好一系列的执行标准,这些标准的串联成一整套业务流程
遇到适合的场景使用这样的设计模式也是非常方便的,因为他可以控制整套逻辑的执行顺序和统一的输入、输出,而对于实现方只需要关心好自己的业务逻辑即可
3.简单工厂搭建发奖domain
本质:就是为了简化if else判断不同类型使用不同的代码处理, 使用map将不同的类型和对应的代码联系到一起。让代码变得更整洁。
工厂模式:是一种创建型设计模式,在父类中提供一个创建对象的方法,允许子类决定实例化对象的类型。
奖品服务交给工厂,工厂提供对外的发奖服务,由工厂进行统一包装【减少使用ifelse,使用map将奖品类型map过来】。
“发放奖品”工厂作用:外部提供一个奖品类型,工厂提供这个奖品类型需要提供什么样的服务去处理。
4.状态模式完成状态流转
状态模式(State Pattern):属于行为型模式,是允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
在软件开发中,经常需要根据对象的不同状态进行不同的逻辑处理,通常情况下我们会使用if-else/switch-case进行判断处理,但是大量的逻辑判断语句会使程序臃肿,不利用程序的扩展与维护。这时可以将不同状态下的逻辑处理抽象分离出来,使程序更加健壮。状态模式这批篇博客例子挺好
【这里也是用的map,将对应状态】
怎么使用的:
传一个状态实例,实现类里调用对应状态的要进行的操作。
5.策略模式选择生成ID算法
策略模式属于行为模式的一种,一个类的行为或算法可以在运行时进行更改。
使用策略模式把三种生成ID的算法进行统一包装,由调用方根据不同的场景来选择出适合的ID生成策略。
这里三种方式生成ID雪花算法、随机算法、日期算法,分别用在订单号、策略ID、活动号的生成上。【使用map】

优惠策略的选取也是使用策略模式详见 实战策略模式「模拟多种营销类型优惠券,折扣金额计算策略场景」
6.分库分表来缓解缓存压力
基于 HashMap 核心设计原理,使用哈希散列+扰动函数的方式,把数据散列到多个库表中的组件。
由于业务体量较大,数据增长较快,所以需要把用户数据拆分到不同的库表中去,减轻数据库压力。
分库分表操作主要有垂直拆分和水平拆分:
- 垂直拆分:指按照业务将表进行分类,分布到不同的数据库上,这样也就将数据的压力分担到不同的库上面。最终一个数据库由很多表的构成,每个表对应着不同的业务,也就是专库专用。
- 水平拆分:如果垂直拆分后遇到单机瓶颈,可以使用水平拆分,区别是:垂直拆分是把不同的表拆到不同的数据库中,而本章节需要实现的水平拆分,是把同一个表拆到不同的数据库中。如:user_001、user_002
这里实现的是水平拆分的路由设计。
大致思路:
分库:通过AOP方式,拦截@dbRouter注解,(将用户ID、订单ID)通过一致性Hash计算目标数据源(得到Hashcode-扰动函数增加随机性进行散列减少哈希碰撞,计算出哪个库哪个表),缓存到Threadlocal里。配置DynamicDataSource,从Threadlocal中读取目标数据源key执行切换。
分表:利用MyBatis拦截器,在@DBRouterStrategy(true)标记的类里,从Threadlocal中读取目标ID,补全SQL语句。
计算落到那个库中然后动态切换数据源;
计算落到那个表中然后mybatis拦截器,拦截到对应的sql语句然后添加上具体的表单号。

只分库不分表只加@DBRouter路由,就到对应的
既分库又分表需要再@Mapper下加@DBRouterStrategy(splitTable = true)
(1)数据库路由设计要包括哪些技术知识点
- AOP 切面拦截的使用:这是因为需要给使用数据库路由的方法做上标记,便于处理分库分表逻辑。
- 数据源的切换操作:既然有分库那么就会涉及在多个数据源间进行链接切换,以便把数据分配给不同的数据库。
- 数据库表寻址操作:一条数据分配到哪个数据库,哪张表,都需要进行索引计算。在方法调用的过程中最终通过 ThreadLocal 记录。
- 数据散列的操作:让数据均匀的分配到不同的库表中去。
(2)为什么分库分表?
分库分表基本是单表200万,才分,你们为什么分库分表?
- 我们分库分表用的非常熟。但不能为了等到系统到了200万数据,才拆。那么工作量会非常大
- 我们的做法是,因为有成熟方案,所以前期就分库分表了。但,为了解释服务器空间。所以把分库分表的库,用服务器虚拟出来机器安装。这样即不过多的占用服务器资源,也方便后续数据量真的上来了,好拆分。
- 同时,抽奖系统,是瞬时峰值较高的系统,历史数据不一定多。所以我们希望,用户可以**快速的检索到个人数据,做最优响应。**因为大家都知道,抽奖这东西,push发完,基本就1~3分钟结束,10分钟人都没了。所以我们这也是做了分库分表的理由。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









