





parquet和orc
在大数据企业生态系统中,涉及分析和数据科学时总是有新的选择。 Apache孵化了许多项目,人们总是对如何选择合适的生态系统项目感到困惑。 在数据科学管道中,即席查询是重要的方面,它使用户能够运行不同的查询,从而产生探索性统计信息,从而帮助他们理解数据。 实际上,对于许多公司和实践而言,Hive仍然是他们的工作之马。 与Hive一样古老,不同的组织可能会以不同的方式破解它,以使其易于使用。 仍然,我听到很多抱怨说查询无法完成。 花时间等待查询执行和调整查询结果会减慢数据科学发现的速度。
就个人而言,与Hive map-reduce程序相比,我喜欢使用Spark来运行即席查询,这主要是由于同时在Spark上执行其他操作的简便性。 我不必使用其他工具来回切换。 最近,我还研究了Alluxio,这是一个分布式的内存文件系统。 在本文中,我将演示使用SparkSQL,Parquet和Alluxio来加速即席查询分析的示例。 使用Spark加速查询时,数据局部性是关键。
使用MapR安装Alluxio
首先,我们从在3节点AWS实例(m4.2xlarge)上运行的现有MapR 5.1系统开始。 我们从Github下载Alluxio并使用Mapr5.1构件进行编译。
git clone git://github.com/alluxio/alluxio.git
cd alluxio
git checkout v1.2.0
mvn clean package -Dhadoop.version=2.7.0-mapr-1602 -Pspark -DskipTestsOracle Java 8用于编译Alluxio,它也是与MapR系统运行的Java相同的版本。 但是,要启动Alluxio Web UI,需要暂时切换回Java 7。 我们还对配置进行了一些更改,添加了alluxio-env.sh:
ALLUXIO_MASTER_HOSTNAME=${ALLUXIO_MASTER_HOSTNAME:-"node1 host name"}
ALLUXIO_WORKER_MEMORY_SIZE=${ALLUXIO_WORKER_MEMORY_SIZE:-"5120MB"}
ALLUXIO_RAM_FOLDER=${ALLUXIO_RAM_FOLDER:-"/mnt/ramdisk"}
ALLUXIO_UNDERFS_ADDRESS=${ALLUXIO_UNDERFS_ADDRESS:- "/mapr/clustername/tmp/underFSStorage"}
ALLUXIO_JAVA_OPTS+=" - Dalluxio.master.journal.folder=/mapr/clustername/tmp/journal"这些配置将放置在MapR文件系统上的Alluxio文件存储以及主日志中,同时还为Alluxio工作集文件设置5GB的内存。 我们甚至可以在MapR-FS中设置一个专用的卷作为Alluxio的文件系统。 我们还可以添加一个工作文件,其主机名是我们计划在其上运行Alluxio worker的3个节点的主机名。
node1
node2
node3因此,在我们的3节点MapR集群之上,我们具有Alluxio架构,其中主服务器运行在node1上,工作服务器运行在node1,node2和node3上。 您只需要运行一些命令即可使Alluxio运行。 那么您将可以在节点1:19999处访问Web UI
clush -ac /opt/mapr/alluxio/conf
cd /opt/mapr/alluxio/
bin/alluxio format
bin/alluxio-start.sh all准备数据
为了进行比较,我们还使用CDH-5.8.0构建了一个4节点的Cloudera集群(m4.2xlarge),并将Alluxio放在具有相同架构的3个数据节点上。 我们在两个集群上运行一个独立的Spark shell,在node1上运行spark-master,在node [1-3]上运行3个工作线程,每个工作线程具有10GB的内存。 我们将使用来自Kaggle的点击率预测数据作为我们将要处理的样本数据。 样本数据的大小为5.9GB,包含超过4000万行。 要启动Spark shell,我们使用:
spark-shell --master spark://node1:7077 --executor-memory 2G --packages com.databricks:spark-csv_2.1:0:1.4.0在Spark Shell中,我们从maprfs和hdfs的受尊重路径中加载csv:
val trainSchema = StructType(Array(
StructField("id", StringType, false),
StructField("click", IntegerType, true),
StructField("hour", IntegerType, true),
StructField("C1", IntegerType, true),
StructField("banner_pos", IntegerType, true),
StructField("site_id", StringType, true),
StructField("site_domain", StringType, true),
StructField("site_category", StringType, true),
StructField("app_id", StringType, true),
StructField("app_domain", StringType, true),
StructField("app_category", StringType, true),
StructField("device_id", StringType, true),
StructField("device_ip", StringType, true),
StructField("device_model", StringType, true),
StructField("device_type", IntegerType, true),
StructField("device_conn_type", IntegerType, true),
StructField("C14", IntegerType, true),
StructField("C15", IntegerType, true),
StructField("C16", IntegerType, true),
StructField("C17", IntegerType, true),
StructField("C18", IntegerType, true),
StructField("C19", IntegerType, true),
StructField("C20", IntegerType, true),
StructField("C21", IntegerType, true)
))
val train = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true")
.schema(trainSchema)
.load(trainPath)然后,我们将文件写入三次以生成所需的数据:1)以csv格式写入Alluxio,2)以Parquet格式写入Alluxio,和3)以Parquet格式写入HDFS / MapR-FS,因为HDFS / MapR-FS上已经存在CSV格式。
train.write.parquet("maprfs:///tmp/train_parquet")
train.write.parquet("alluxio://node1:19998/train_parquet")
train.write
.format("com.databricks.spark.csv")
.option("header", "true")
.save("alluxio://node:19998/train_crt")当我们查看文件大小时,我们可以看到Parquet文件的大小更有效。 5.9GB的CSV数据被压缩到小于1GB。
在热数据上运行SparkSQL
现在是时候读取数据并监视不同的性能了。 我将展示Parquet如何提高查询性能,以及何时使用Alluxio很有用。 在读取任何文件之前,我们将删除操作系统缓存,以获得更准确的测量结果。
clush -a "sudo sh -c 'free && sync && echo 3 > /proc/sys/vm/drop_caches && free'" CSV FILES | PARQUET FILES | |
Cloudera | textFile/csv reader | Parquet reader |
MapR | textFile/csv reader | Parquet reader |
我们可以通过Spark UI捕获执行时间,但是我们也可以编写一个Scala小片段来做到这一点:
val start_time=System.nanoTime()
train.count \\or some other operations
val end_time = System.nanoTime()
println("Time elapsed: " + (end_time-start_time)/1000000 + " milliseconds")首先,我们在Spark中使用textFile()将CSV数据读取到RDD中,并对CSV文件进行简单计数。 您可能会注意到的一件奇怪的事是,缓存的RDD变慢了。 我要强调一点,因为RDD在缓存到Spark中时压缩不多。 例如,在Spark中,DataFrame /数据集的压缩效率更高。 因此,由于分配的内存有限,我们实际上只能缓存15%的数据,这只是整体的一小部分。 因此,当尝试在缓存的Spark RDD上运行查询时,我们要确保为执行程序分配足够的内存。
Cloudera | MapR | |
TextFile | 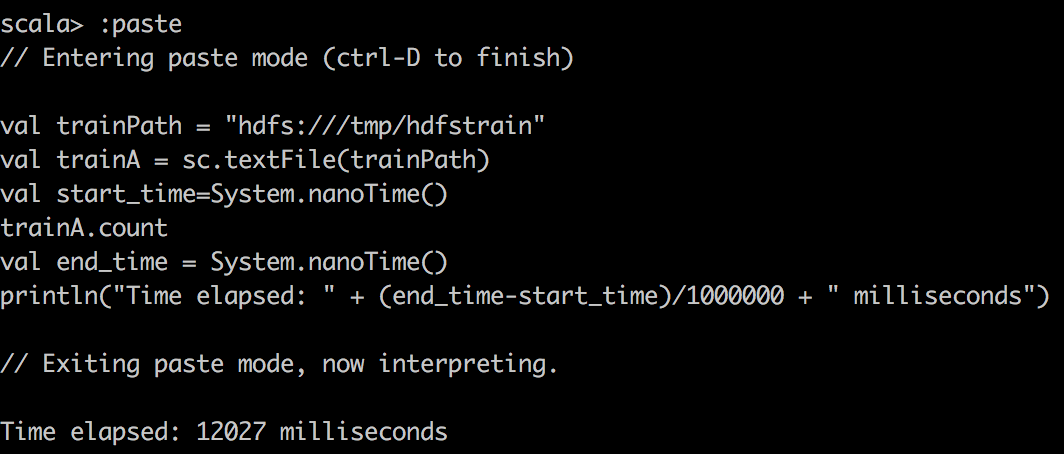 | 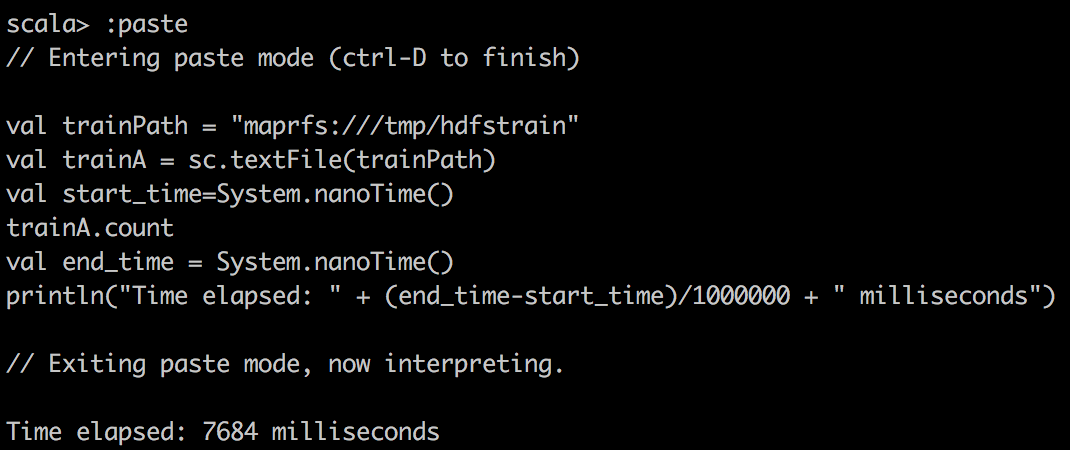 |
TextFile reading Alluxio | 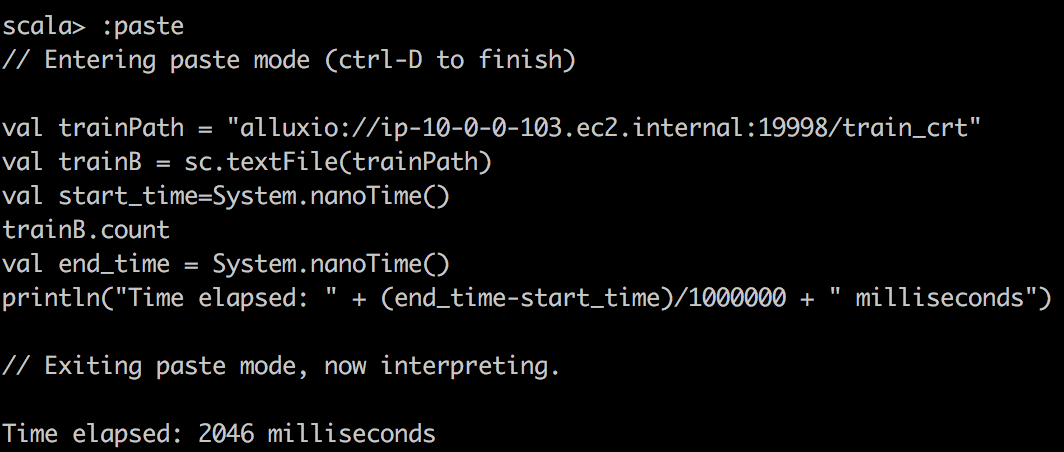 | 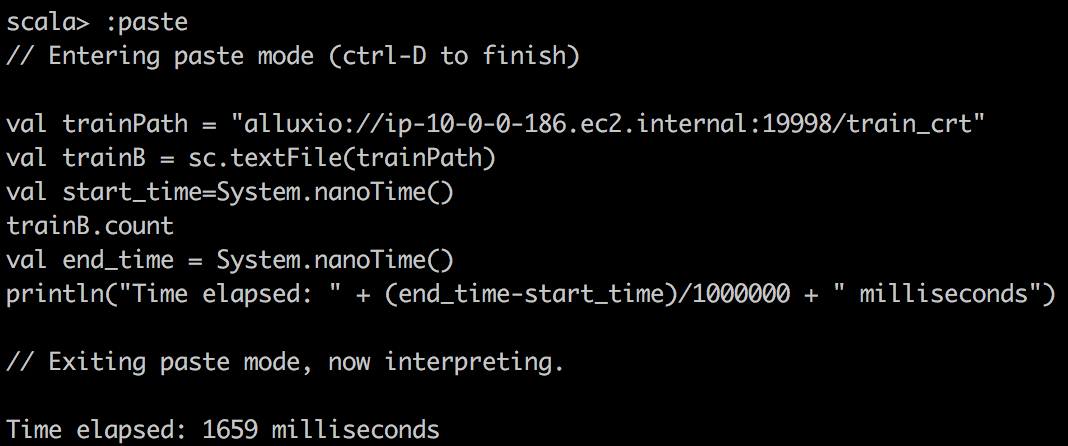 |
TextFile cached | 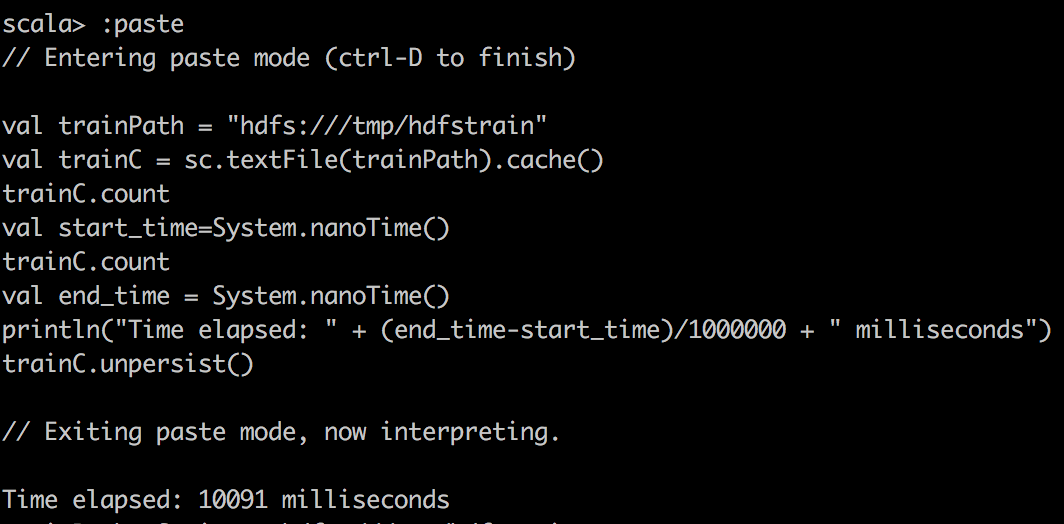 | 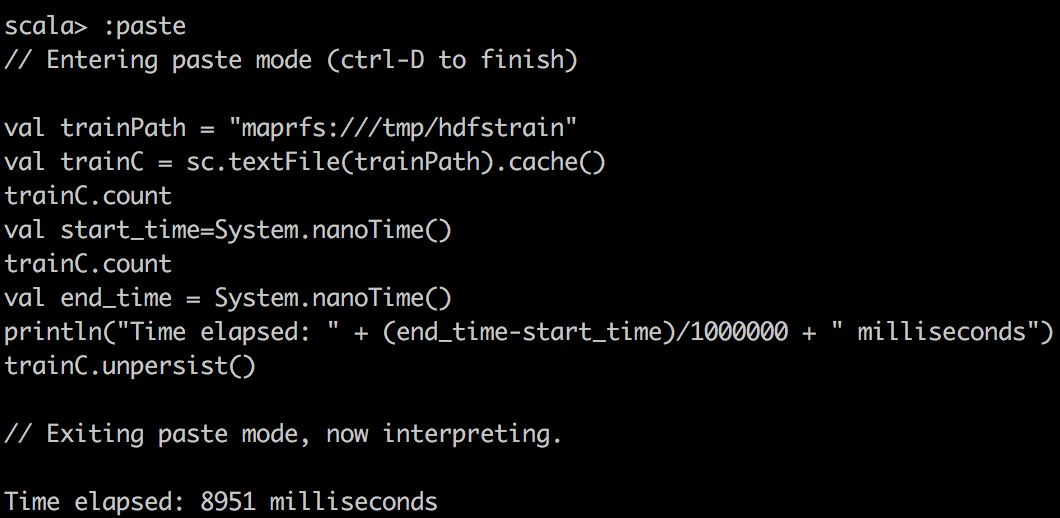 |
其次,我们使用Databricks的包将CSV读取到Spark中的DataFrame中,并对csv文件进行简单计数。 在这里,当将Spark DataFrame缓存到内存中时,我们注意到更好的压缩和更大的提升。
Cloudera | MapR | |
CSV File | 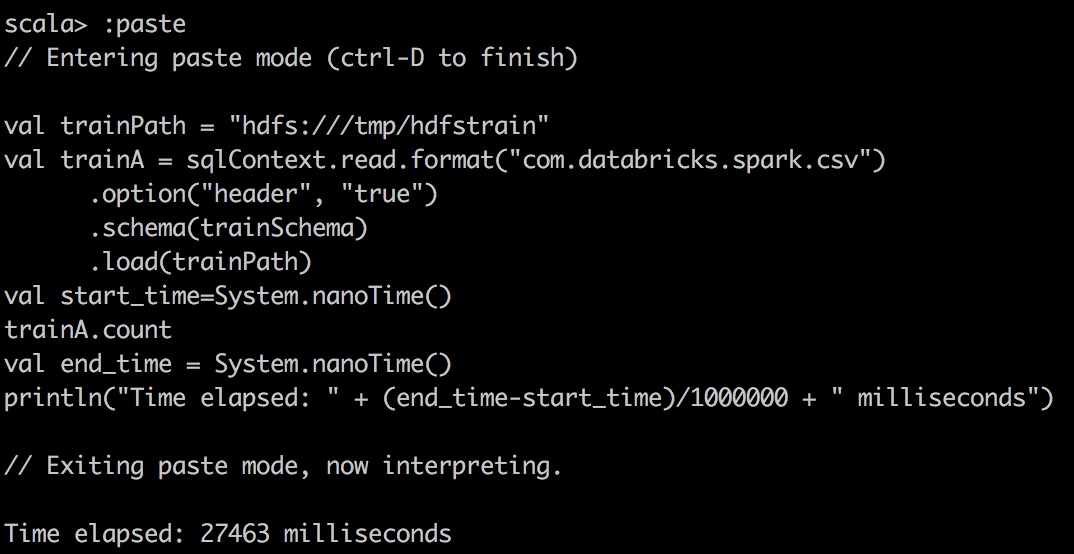 | 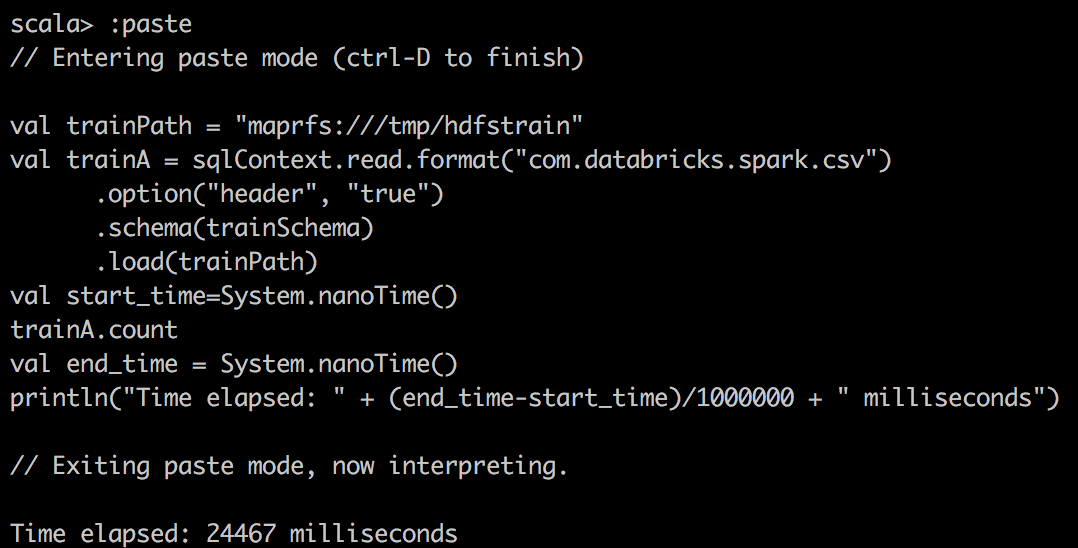 |
CSV File reading Alluxio | 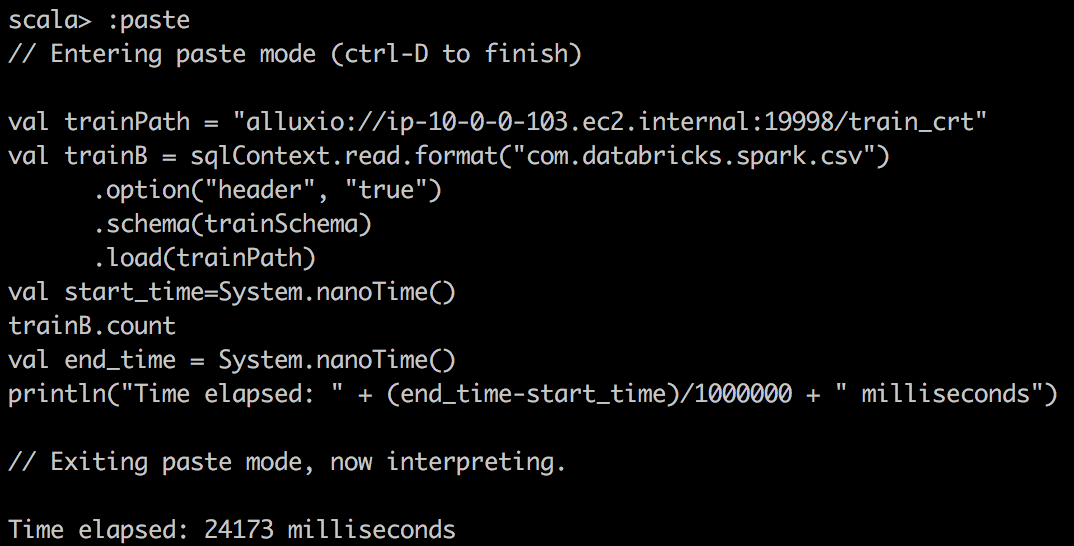 | 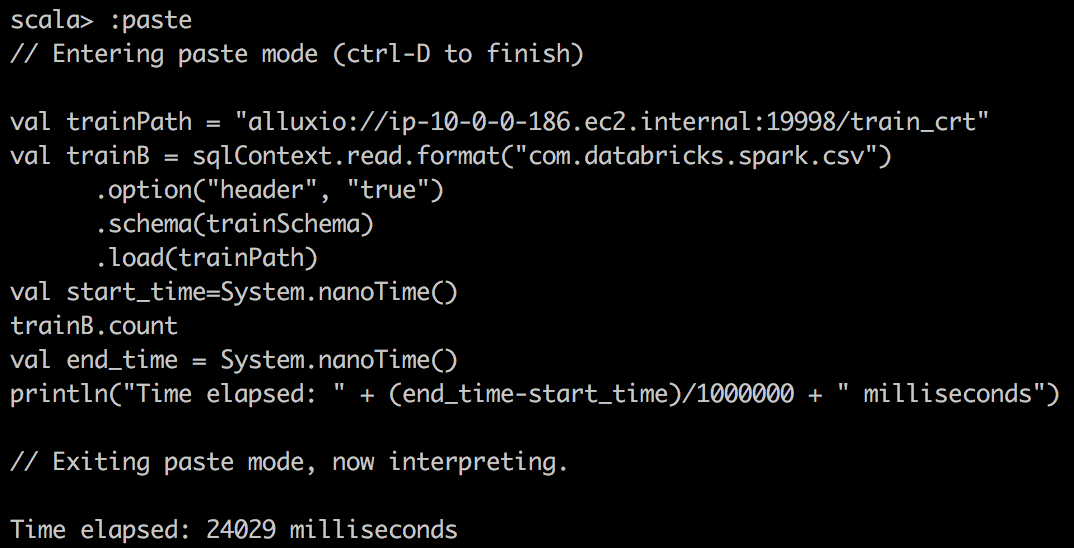 |
CSV File cached | 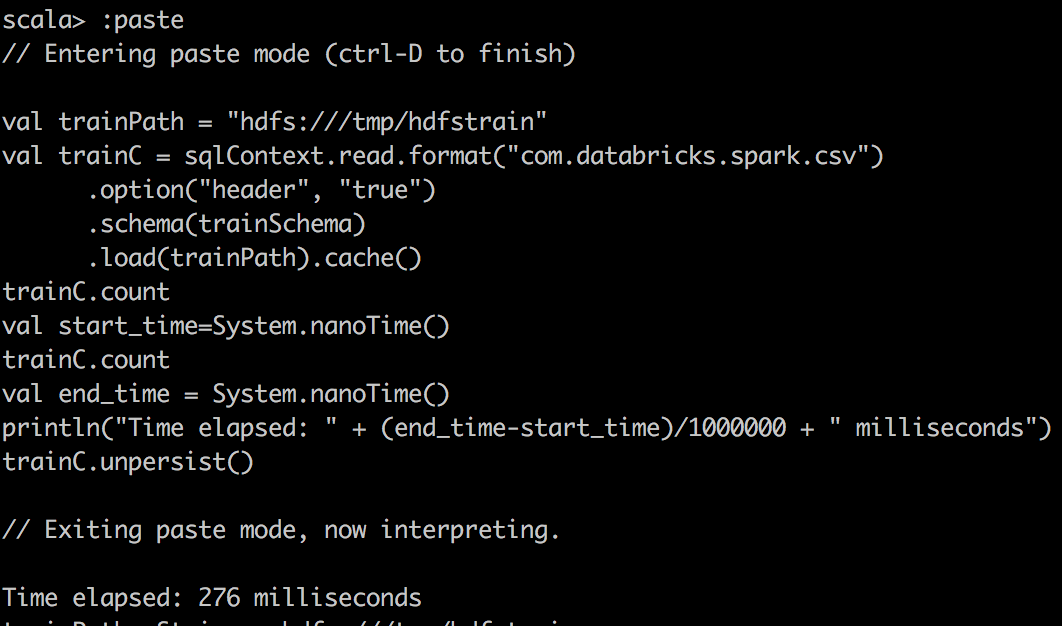 | 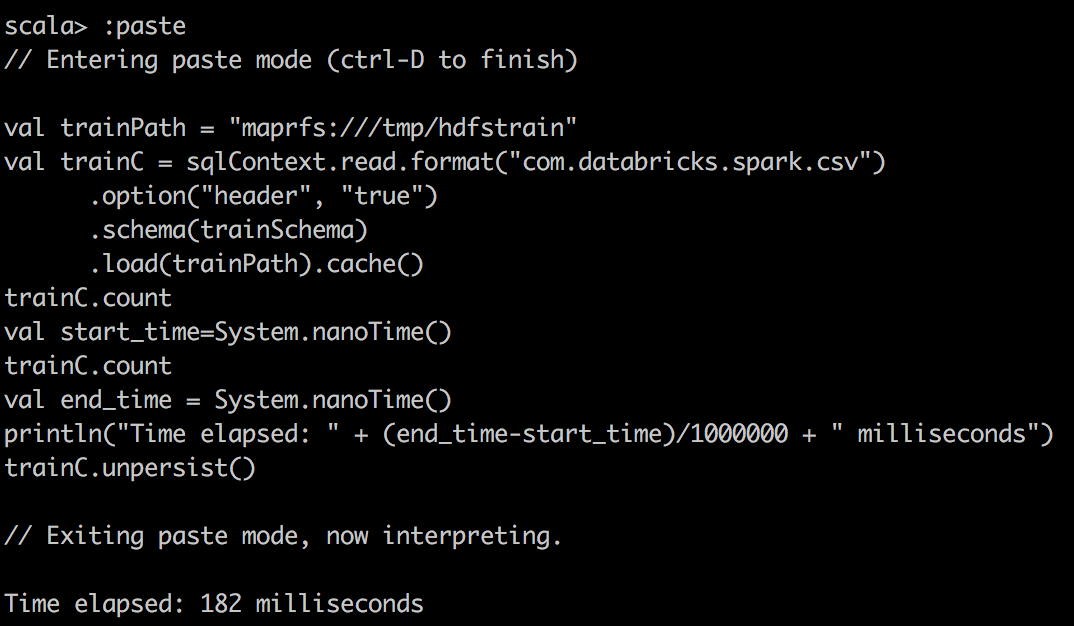 |
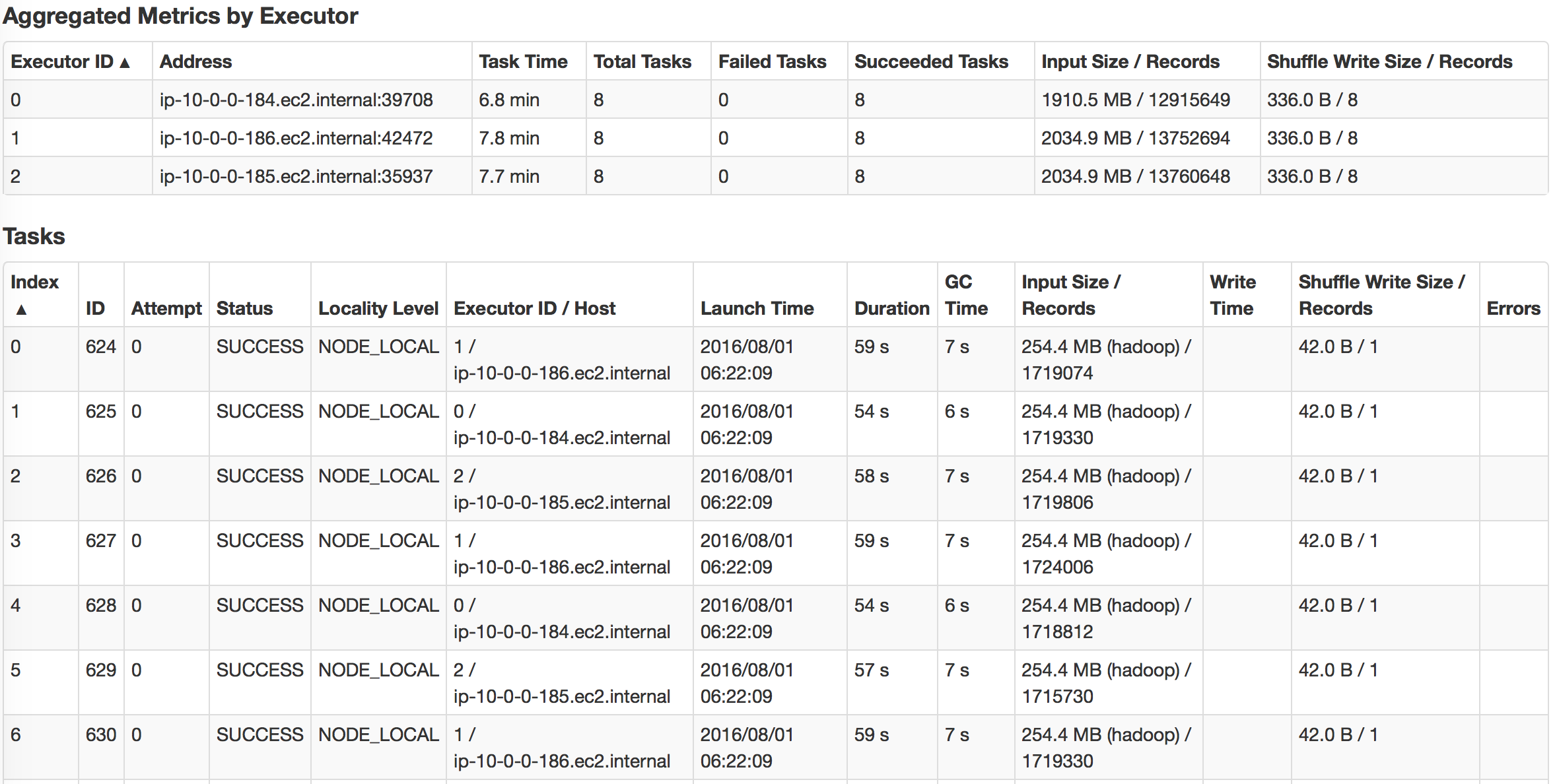
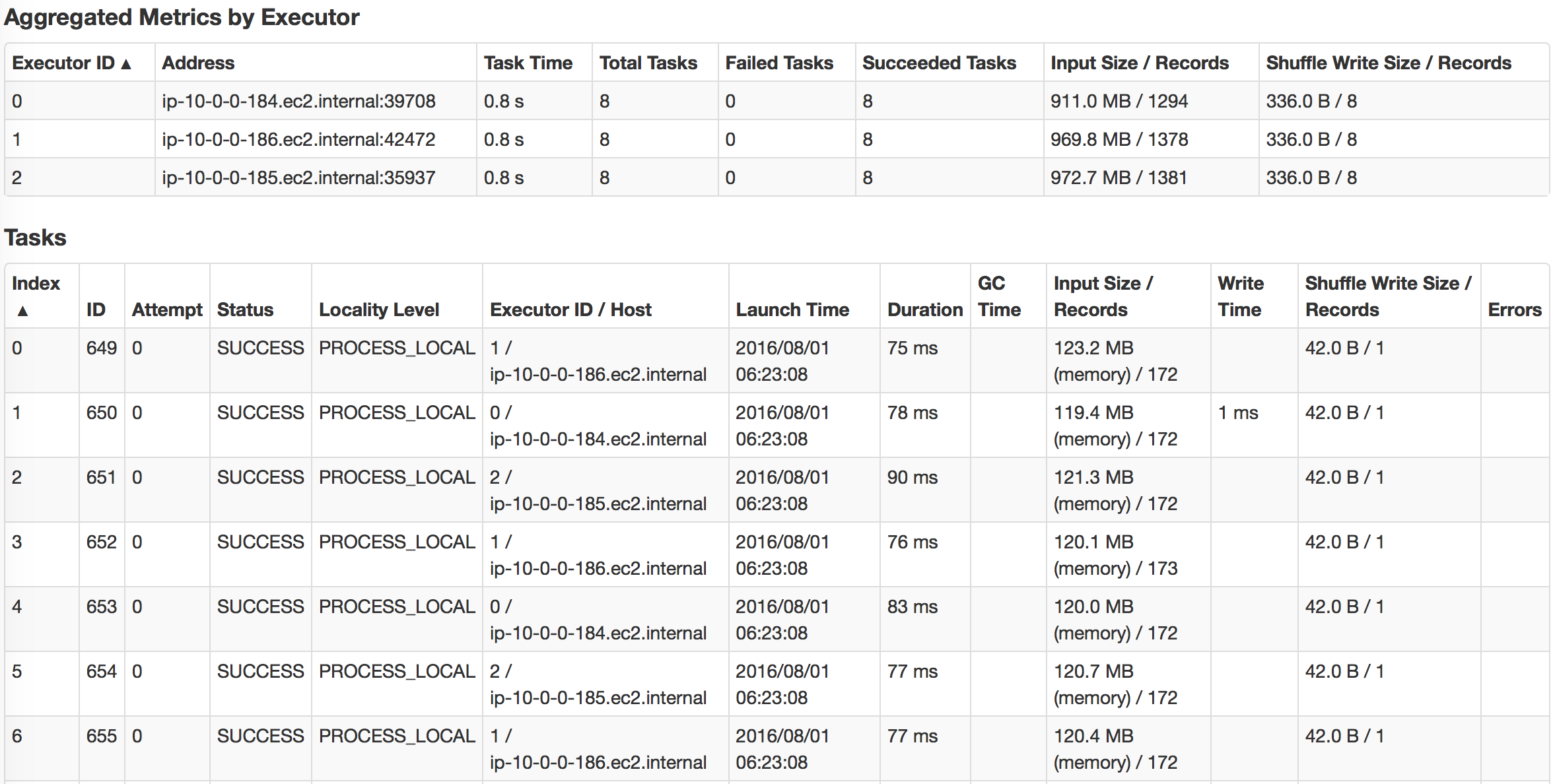
最后,我们将Parquet读入Spark的DataFrame中,并对Parquet文件进行简单计数。 我们可以看到,由于Parquet的出色设计,它对于列式查询非常有效。 另外,它与Apache Drill一起使用时效果很好。
Cloudera | MapR | |
Parquet | 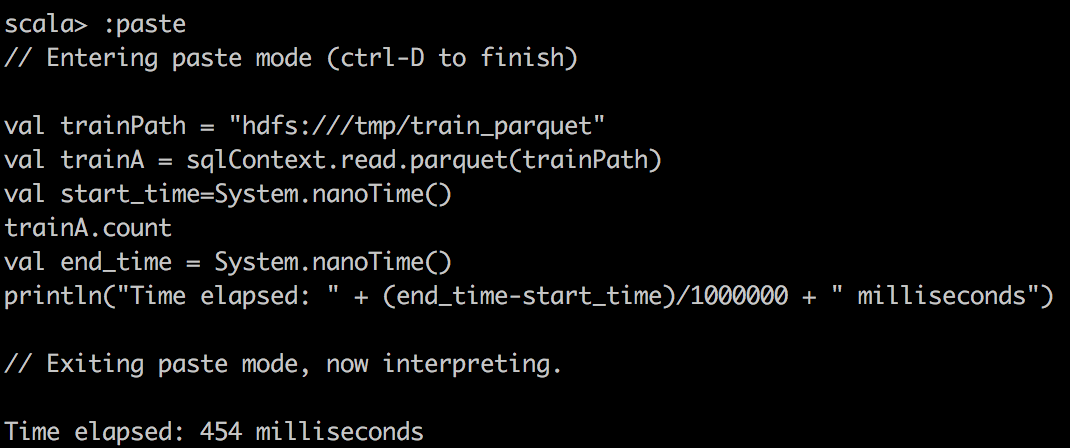 | 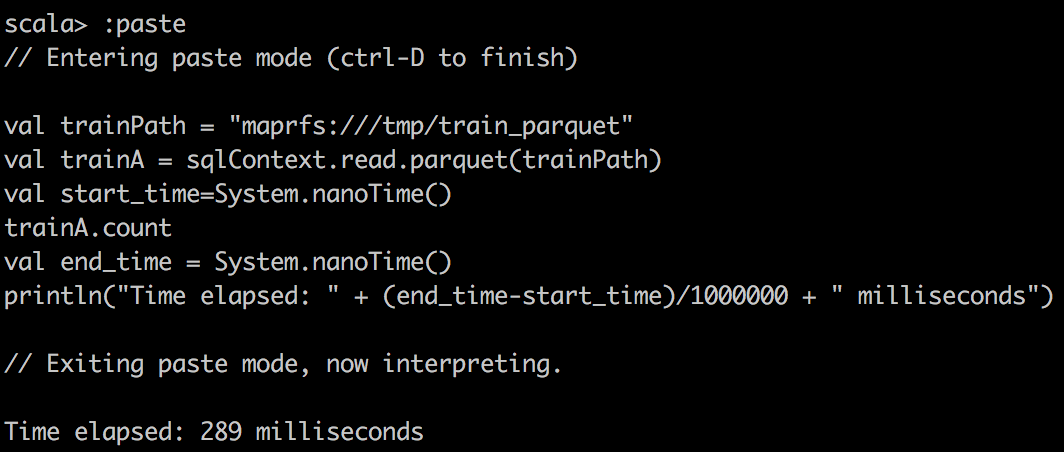 |
Parquet reading Alluxio | 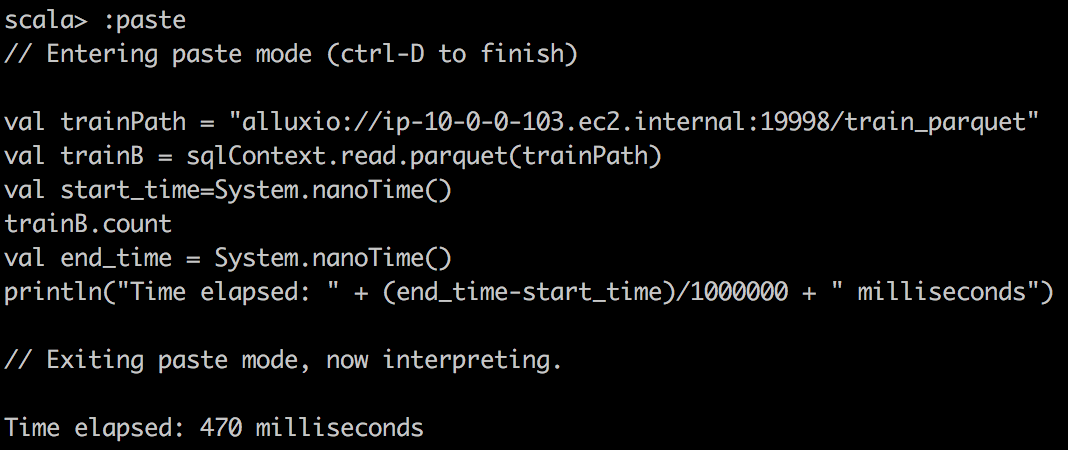 | 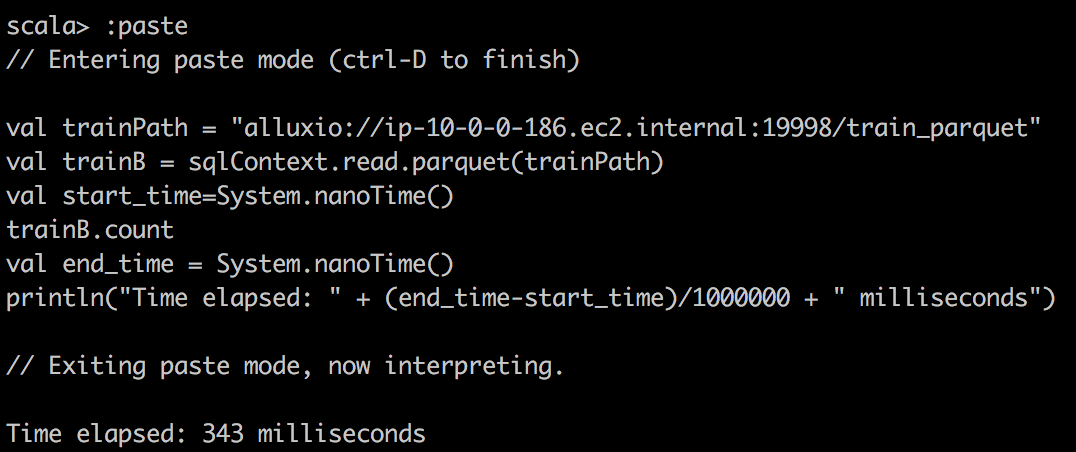 |
Parquet cached | 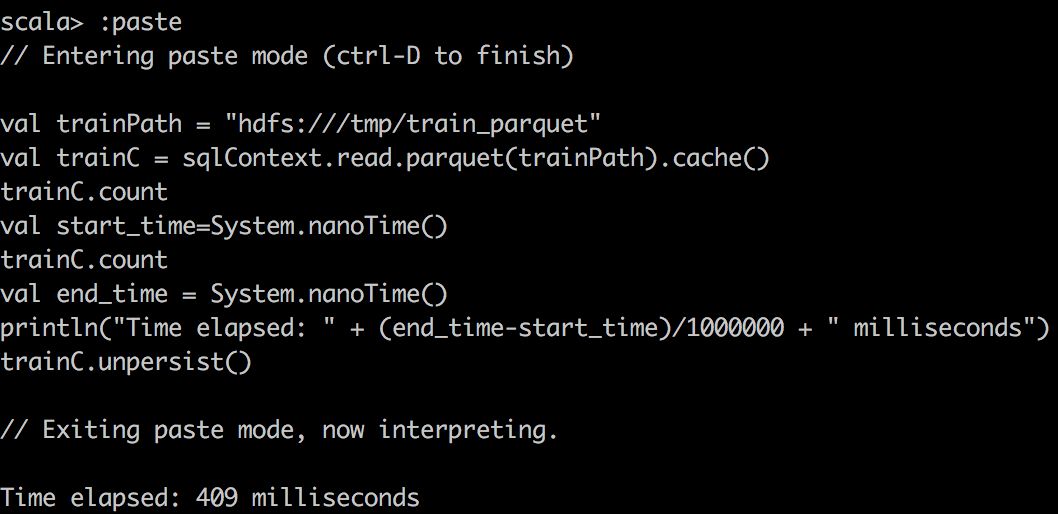 | 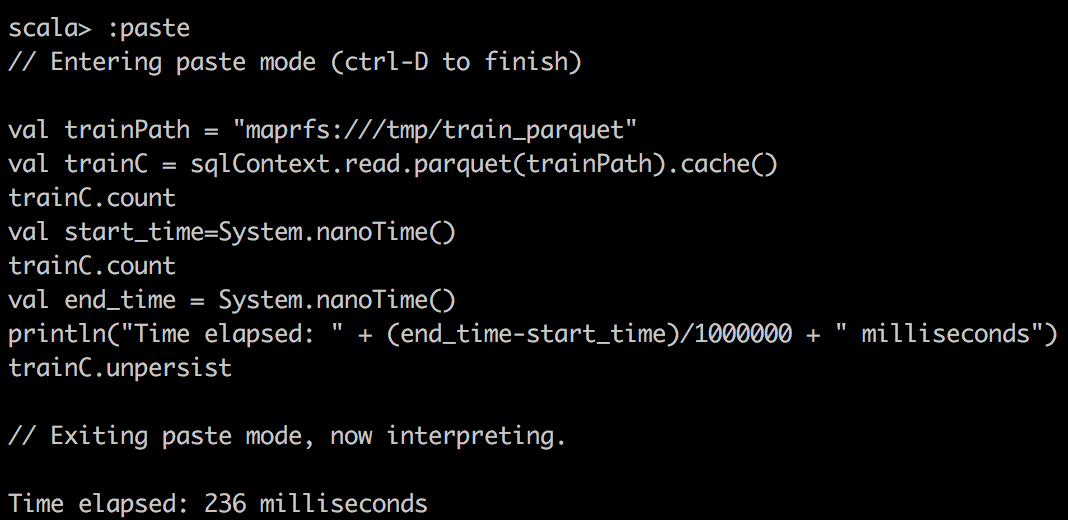 |
我们可以观察到,利用缓存的DataFrame和RDD可以大大加快查询速度。 如果我们查看任务的执行方式,我们会注意到对于缓存的任务,任务的所有位置级别都显示为“ PROCESS_LOCAL”,而对于非缓存的任务,它们的显示为“ NODE_LOCAL”。 这就是为什么我要说数据局部性是这里查询速度的关键,也是为什么如果您有许多远程数据中心,Alluxio将会成功的原因。 但是您可以通过MapR技术实现类似的想法。 只需为带有热数据的某些卷创建专用的卷镜像,然后将其放置在本地群集上。
摘要
总而言之,如果我们想加快Hadoop上的查询速度,我们应该真正使用缓存的SparkSQL,并尝试将Parquet格式用于正确的用例。 如果您有远程数据中心或异构存储层,Alluxio会很棒。 它可以提供Spark执行所需的数据局部性。 好处是可以抵御工作失败,并在多个Spark会话之间共享。 为了真正监视系统性能,我们应该监视文件系统的吞吐量统计信息。 这只是性能指标的粗略表示。 我们还观察到,下面的数据越大,使用Alluxio或将其缓存在内存中所获得的好处就越多。
另外,如果您对使用Drill查询Alluxio有兴趣,只需将已编译的alluxio jar文件alluxio-core-client-1.2.0-jar-with-dependencies.jar放在jars / classb下。 您还需要在conf / core-site.xml中添加以下行。
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem<value>
</property> 祝您查询数据愉快! 如有任何疑问,请在下面的评论部分中提问。 ![]()
翻译自: https://www.javacodegeeks.com/2016/08/speed-ad-hoc-analytics-sparksql-parquet-alluxio.html
parquet和orc















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









