





kafka的分区和主题
当您选择具有持久性的消息系统时, 流数据可以用作长期的可审核历史记录,但是就大规模存储数年数据的成本而言,这种方法是否可行? 答案是“是”,特别是因为在MapR Streams中处理主题分区的方式。 运作方式如下。
与Kafka API兼容的诸如Apache Kafka和MapR Streams之类的消息传递技术正在破坏大数据架构,以使基于流的设计所涉及的范围远远超出了实时或接近实时的项目。 因为它们即使具有持久性也可以大规模提供低延迟性能,所以这些现代消息传递系统可以使数据生产者与消费者或消费者组分离。 这种解耦为拥有以各种方式使用数据的消费者打开了一扇门,包括作为可重播日志。
消息已准备就绪,可以立即使用或稍后使用,从而重播事件日志。 消费者不必在消息到达时就运行; 他们可以稍后上线,从而轻松添加新消费者。 Kafka和MapR Streams均支持此行为,但是存在重要的技术差异,因此在使用方式上有很大差异。 这样的区别之一在于它们处理主题分区的方式,进而改变了长时间保留消息日志的可行性。
如果您不熟悉Kafka或MapR Streams,那么对主题和分区的一些了解会很有帮助。 这些消息传递系统中的数据已分配给主题-每个主题都是为方便起见而命名的消息流-消费者订阅一个或多个主题。 为了提高性能,可以通过将主题划分为子主题分区来实现负载平衡,如图1所示。更具体地说,在这种情况下,每个使用者都订阅一个或多个分区。 请注意,这种消息传递风格不同于将消息广播给所有使用者的工具,该工具以到达时使用的方式提供消息数据,也不同于非常谨慎地将每条消息发送给一个使用者的工具。
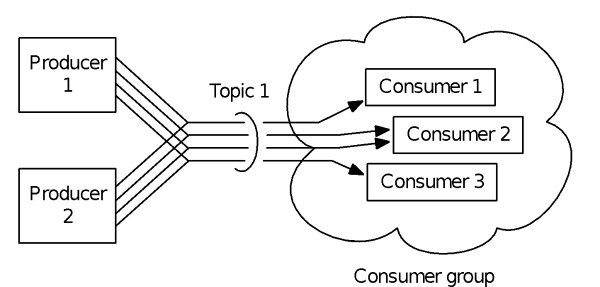
图1:Apache Kafka或MapR Streams中的每个主题都可以分为几个分区。 这有助于负载平衡。 消费者订阅一个或多个分区。 Kafka在与文件存储或数据处理不同的群集上运行,并将每个主题分区的每个副本存储在单台计算机上,因此,主题分区的大小受到限制。 相反,MapR Streams已集成到MapR融合平台中。 使用MapR,主题分区分布在整个群集中,并且与文件存储和计算共享。 另请参阅 Dunning和Friedman(O'Reilly)合着的《 Streaming Architecture》 第4章“ Apache Kafka” 和 第5章“ MapR流” 。
对于MapR Streams,还有一个称为Stream的功能可将许多主题收集在一起。 这主要是一项管理功能:流在整个文件系统名称空间中具有名称,并且在流级别应用诸如生存时间,ACE或地理分布复制之类的策略,这特别方便,因为MapR流还可以支持大量的主题(100,000个主题),远远超出了在Kafka中可行的主题。 尽管Kafka没有MapR Stream的等效功能,但是您可以在Kafka中设置每个主题的生存时间,因此,您仍然可以选择使用数据并丢弃数据或将其保存不同的时间段,例如MapR流。 但是,如果将生存时间设置为几年甚至无穷大,这是否适用于处理大量数据?
与MapR相比,Apache Kafka分配主题分区的方式有所不同。 这就是为什么这样重要:在Flink联合创始人Stephen Ewan的演讲之后的一次最近的伦敦Apache Flink聚会上的一次讨论中,有人质疑将多年的消息事件数据保存在可审核日志中的可行性。 观众似乎很确定这样长的生存期是不可行的。 从那时起,我意识到许多人不知道在主题下方有一个更好的基本体系结构可能允许存储几年的数据。 MapR Streams就是这样的架构。
MapR的另一位演讲者Ted Dunning解释说,当您检查成本和可行性时,重要的是要知道MapR Streams消息传递已集成到主群集中,而不是像Kafka那样在单独的群集上运行。 借助MapR,每个分区不限于一台计算机-MapR主题分区分布在整个群集中。 相反,Kafka在单独的群集上运行。 使用Kafka时,每个主题分区仅限于Kafka群集中的一台计算机。 之所以可以做到这一点,是因为MapR Streams不仅是Apache Kafka的端口。 相反,它是作为MapR平台的一部分而构建的完整重新实现。
MapR产品管理总监Will Ochandarena在最近的Kafka峰会的报告中描述了与主题平衡相关的一个问题。 使用Kafka时经常提到的一个痛点是“…将多个“重”分区放置在同一节点上,从而导致热点和存储不平衡。”
将继续说明这与MapR Streams的工作方式不同。 “ MapR Streams不会将分区固定到单个节点,而是将分区拆分为较小的链接对象,称为“分区”,这些对象分布在群集中的节点之间。 在将数据写入集群时,活动分区(处理新数据的分区)会根据负载进行动态平衡,从而将热点最小化。”
因此,这两个系统是否都具有持久消息(它们确实具有持久消息)以及两个系统中的生存时间是否可配置都是一个问题。 但是,使用MapR Streams消息传递,对于那些需要长期历史记录的用例,长时间保存消息数据是完全合理的。
一种基于流的体系结构的想法很新,它很容易支持可重播流中的长期持久性以及低延迟处理,因此用例才刚刚出现。
在我与他人合着的Ted Dunning一书《 Streaming Architecture》中 ,我讨论了一系列消费者类别,包括长期的可审核日志。 在第一章的结尾,我们描述了一个医疗环境中的假设示例,在该示例中,可以以多种方式使用流数据。 图2显示了三类用户(消费者)。
通过此示例的一条途径是通过消息传递技术将数据从实验室测试或诊断或治疗设备传递到实时或接近实时的处理应用程序。 这种类型的低延迟应用程序通常是最先吸引用户使用流数据的应用程序。 图2显示了A组使用者中的此示例。
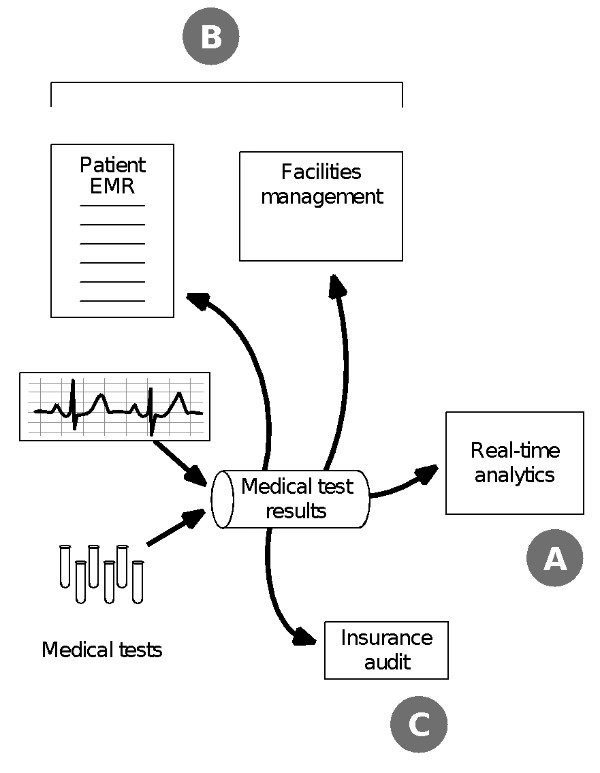
图2:使用Apache Kafka或MapR的基于流的体系结构流的消息传递样式支持不同类别的使用者 。 A类消费者可能会使用低延迟处理工具来对来自各种实验室测试的流数据进行分析。 结果可能会显示在实时仪表盘或监控显示中。 B类消费者可以提取患者的医疗状况或设备性能的当前状态视图,以便在数据库或搜索文档中使用。 最后一个组C,将使用流事件数据作为可重播的日志,作为可审核的历史记录,这是保险组所感兴趣的。 请参阅《 Streaming Architecture @Dunning and Friedman 2016 》一书的第1章 。
其他消费者或一组消费者可以将同一事件数据流用于实时应用程序以外的目的。 其中包括将状态更新拉入数据库或可搜索文档的字段(此图中的B组)。 但是,本文的主要重点是C组使用者,将消息用作可重播的日志,可充当长期可审核历史记录的功能。 在图中描述的医疗保健示例中,第三种类型的消费者功能可能是出于保险审计的目的。
您可以将这种使用模式应用于其他行业。 例如,在财务环境中,数据库可以提供个人银行帐户的状态,而可重播日志提供该帐户余额如何产生的交易历史记录。 对于来自工业设备上IoT传感器的数据流,可重播的历史记录可能用作输入数据,以训练异常检测模型,作为预测性维护计划的一部分。 关键思想是,使用正确的消息传递系统,能够存储和分析长期历史的功能变得实用。
资源和参考
- 有关Kafka峰会的报告,请参阅“ 与Kafka扩展:解决的常见挑战 ”。
- 有关使用Apache Kafka的更多信息,请参阅第4章“ 流传输体系结构”,或者通过动手示例,尝试博客“ Kafka 0.9示例程序入门 ”。
- 有关MapR Streams的更多信息,请参见Streaming Architecture的 第5章和动手教程“ MapR Streams入门 ”。
- 要获得免费的按需培训,请参阅MapR Streams上的两门课程 。
翻译自: https://www.javacodegeeks.com/2016/06/apache-kafka-mapr-streams-handle-topic-partitions.html
kafka的分区和主题















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









