





机器学习实用指南
由Jean-Francois Puget(@JFPuget)合着
机器学习代表了分析领域的新领域,是多少公司可以利用数据机会的答案。 机器学习于1959年由Arthur Samuel首次定义为“使计算机无需明确编程即可学习的能力的研究领域”。 换句话说,这是分析的自动化,因此可以大规模应用。 今天,什么是高度手动的(想像一位分析师整理数千行电子表格),明天将通过技术变成自动(一个简单的按钮)。 如果机器学习是在1959年首次定义的,那么为什么现在才是抓住机遇的时机? 这是经济学。
一个相对的图形来解释:
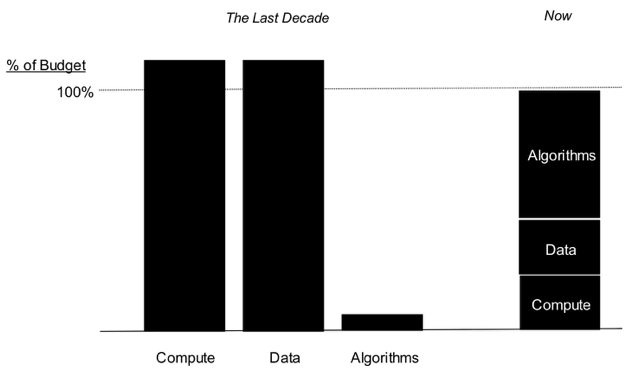
自定义机器学习之时到过去十年,机器学习的应用一直受到计算和数据获取/准备成本的限制。 实际上,计算和数据消耗了分析的全部预算,这为真正的价值驱动因素留下了零投资:驱动可行见解的算法。 在过去的几年中,随着计算和数据成本的直线下降,现在任何人都可以使用机器学习来进行快速应用和开发。
***
众所周知,企业必须不断适应不断变化的条件:竞争对手推出新产品,改变消费者习惯,改变经济和政治环境等。这不是新事物,但是商业条件变化的速度正在加快。 不断加快的变更步伐给企业开发的技术解决方案带来了新的负担。
多年来,应用程序开发人员从具有数年周转时间的V形项目转变为敏捷开发方法论(周转时间为数月,数周和数天)。 这使企业能够更快地调整其应用程序和服务。 例如:
a)零售商的销售预测系统:预测必须考虑当今的市场趋势,而不仅仅是上个月的趋势。 并且,对于实时个性化,它必须考虑最近1个小时前发生的情况。
b)针对股票经纪人的产品推荐系统:他们必须利用当前的兴趣,趋势和动向,而不仅仅是最近几个月。
c)个性化的医疗保健系统:必须针对个人及其独特情况量身定制服务。 通过物联网(IoT)连接的医疗保健设备可用于收集有关人机行为和互动的数据。
这些场景以及其他类似场景为机器学习创造了独特的机会。 确实,机器学习旨在解决这些问题的流动性。
首先,它将应用程序开发从编程转移到培训:应用程序开发人员使用新数据训练同一应用程序,而不是编写新代码。 这是应用程序开发中的一个根本转变,因为新的,更新的应用程序可以每周(即使不是每天)自动获取。 这种转变是IT认知时代的核心。
其次,机器学习可以自动生成可操作的见解,以了解数据所在的位置(即业务价值最大的位置)。 可以构建从每次用户交互或从IoT设备收集的新数据中学习的机器学习系统。 然后,这些系统产生的输出将最新可用数据考虑在内。 即使使用敏捷方法,传统IT开发也无法做到这一点。
***
尽管大多数公司都达到了了解机器学习的目的,但很少有公司将其付诸实践。 他们要么因为担心数据资产而放慢了速度,要么尝试了一次,然后缩减了工作量,声称结果并不有趣。 这些是常见的关注和考虑因素,但是应该将它们视为可以通过正确方法轻松克服的项目。
首先,让我们获取数据。 一个普遍的陷阱是相信数据是成功的机器学习项目所需要的。 数据是必不可少的,但是机器学习需要的不仅仅是数据。 从大量数据开始但缺乏明确的业务目标或成果的机器学习项目很可能会失败。 从很少或没有数据开始,但业务目标明确且可衡量的项目更有可能成功。 业务目标应指示相关数据的收集,并指导机器学习模型的开发。 这种方法提供了一种评估机器学习模型有效性的机制。
机器学习项目中的第二个陷阱是将其视为一次性事件。 从定义上讲,机器学习是一个连续的过程,因此必须在考虑项目运行的情况下进行。
机器学习项目通常按以下方式运行:
1)他们从数据和新的业务目标入手。
2)数据是准备好的,因为收集数据时并未考虑到新的业务目标。
3)一旦准备好,就在数据上运行机器学习算法以生成模型。
4)然后对新的,不可预见的数据进行评估,以查看模型是否从数据中捕获了一些有意义的信息。 如果是这样,则将其部署在生产环境中,在该环境中对新数据进行预测。
尽管这种典型方法很有价值,但由于模型仅学习一次这一事实而受到限制。 尽管您可能已经开发了一个很好的模型,但是不断变化的业务条件可能使其不相关。 例如,假设使用机器学习来检测信用卡交易中的异常情况。 该模型是使用多年的过去交易创建的,异常是欺诈交易。 拥有一支优秀的数据科学团队和正确的算法,就有可能获得一个相当准确的模型。 然后,可以将该模型部署在支付系统中,在该系统中,当检测到异常时会对其进行标记。 然后,异常交易将被拒绝。 短期内这是有效的,但是聪明的罪犯很快就会意识到发现了他们的骗局。 他们将进行适应,他们将找到使用被盗信用卡信息的新方法。 该模型将不会检测这些新方法,因为它们没有出现在用于产生这些新数据的数据中。 结果,模型有效性将下降。
避免这种性能下降的方法是通过将模型预测与实际情况进行比较来监视模型预测的有效性。 例如,经过一段时间的延迟,银行将知道哪些交易是欺诈性的。 然后可以将实际的欺诈交易与机器学习模型检测到的异常进行比较。 从这一比较中,可以计算出预测的准确性。 然后,您可以随着时间的推移监视这种准确性,并注意是否有墨滴。 当发生下降时,就该用更多最新数据刷新机器学习模型了。 这就是我们所谓的反馈循环。 看这里:
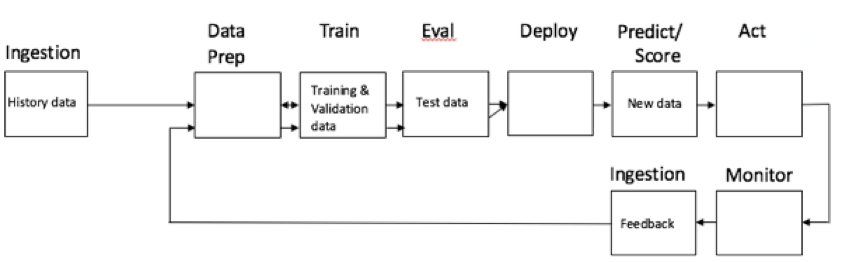
通过反馈回路,系统可以通过监视预测的有效性并在需要时进行再培训来不断学习。 监视和使用结果反馈是机器学习的核心。 这与人类执行新任务的方式没有什么不同。 我们从错误中学习,调整并采取行动。 机器学习也不例外。
***
坚信机器学习应该是其分析旅程的核心组成部分的公司需要一种经过测试且可重复的模型:一种方法。 我们与无数客户合作的经验促使我们设计了一种称为DataFirst的方法。 这是机器学习成功的分步方法。
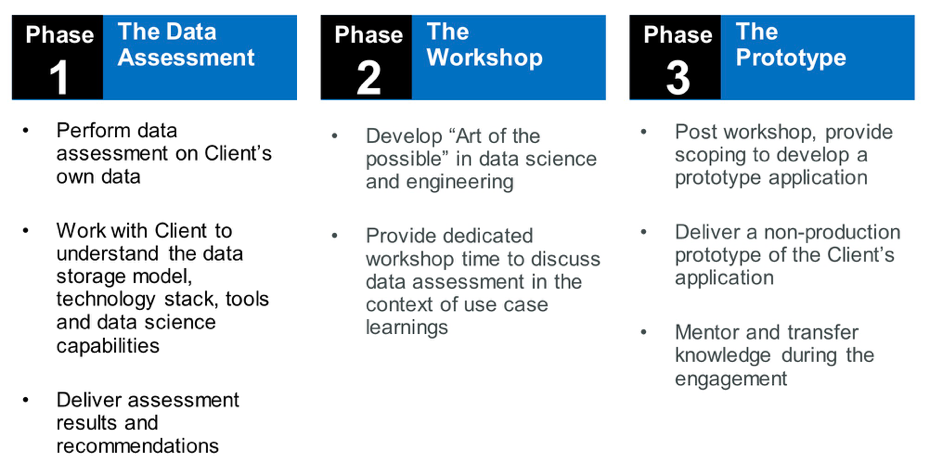
阶段1:数据评估
目的是了解您的数据资产并验证满足机器学习业务目标所需的所有数据是否可用。 如果没有,您可以在那时采取行动,引入新的数据源(内部或外部),以符合既定目标。
阶段2:研讨会
研讨会目标的目的是确保在机器学习项目的定义和范围上保持一致。 我们通常涵盖以下主题:
–设置机器学习可以做什么和不能做什么的级别
–同意使用哪些数据。
–同意要使用的指标进行结果评估
–探索机器学习工作流程(尤其是部署和反馈循环)如何与其他IT系统和应用程序集成。
阶段3:原型
该原型旨在通过实际数据显示机器学习的价值。 它还将用于评估运行和操作生产就绪的机器学习系统所需的性能和资源。 完成后,原型通常是确保开发生产就绪系统的决定的关键。
***
数据时代的领导者将利用他们的资产,在动态数据集的驱动下发展卓越的机器学习和洞察力。 差异化方法需要有条理的过程,并需要通过反馈回路来专注于差异化。 在现代商业环境中,数据不再是竞争优势的一个方面。 这是竞争优势的基础。
机器学习实用指南















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









