





mapr-fs 架构
我们要监视的许多系统都是事件流。 示例包括来自Web或移动应用程序,传感器或医疗设备的事件数据。

实时分析示例包括:
- 网站监控,网络监控
- 欺诈识别
- 网页点击
- 广告
- 物联网:传感器
批处理可以很好地了解过去发生的事情,但是缺乏回答“现在正在发生什么?”这一问题的能力。
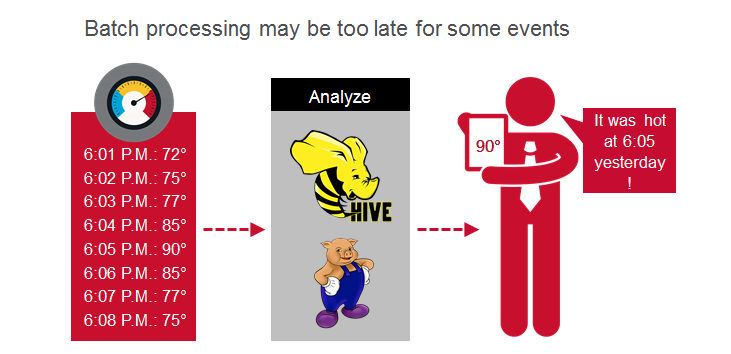
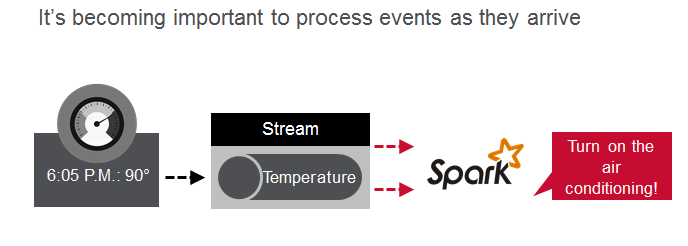
为了实时了解洞察事件,处理事件变得越来越重要,但是要做到这一点,必须有大规模的高性能。 在此博客文章中,我将向您展示如何为快速的,事件驱动的应用程序集成Apache Spark Streaming,MapR-DB和MapR Streams。
示例用例
让我们来看一个示例,该示例生成大量数据并需要实时预防性警报。 还记得BP在墨西哥湾沿岸发生的事情吗?

我们将在此处查看的示例用例是一个监视油井的应用程序。 石油钻井平台中的传感器生成流数据,该数据由Spark处理并存储在HBase中,以供各种分析和报告工具使用。 我们希望将每个事件存储在流中的HBase中。我们还希望过滤并存储警报。 每日Spark处理将存储汇总的摘要统计信息。
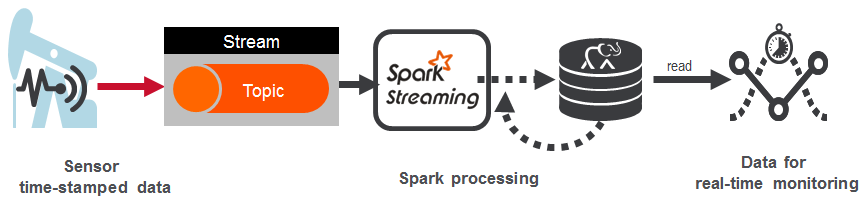
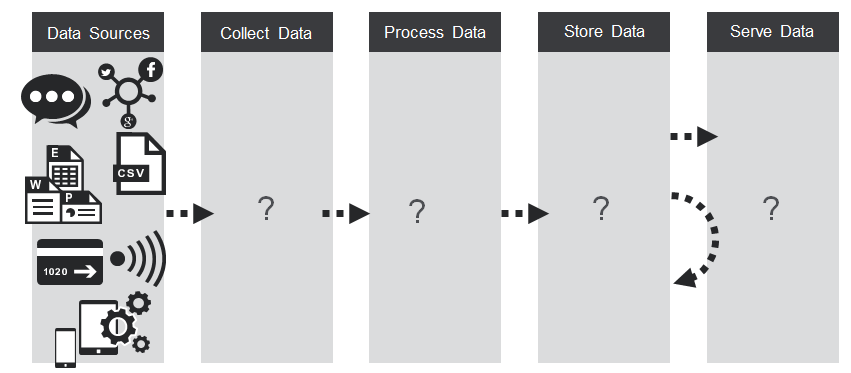
以及我们如何以大规模的高性能做到这一点?
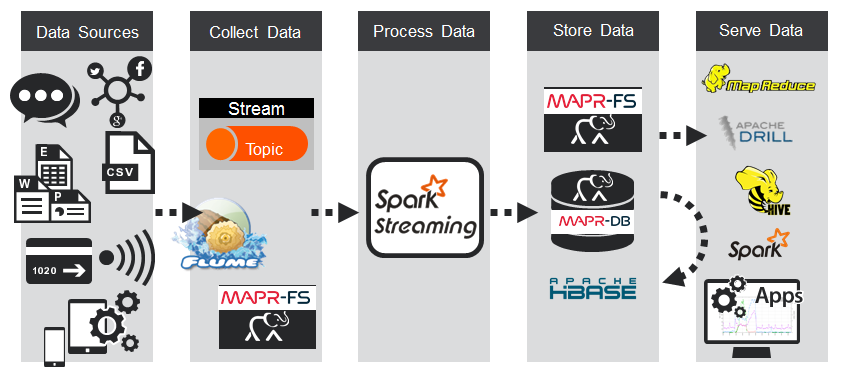
我们需要收集数据,处理数据,存储数据,最后将数据提供给分析,机器学习和仪表板。
流式数据提取
Spark Streaming支持数据源,例如HDFS目录,TCP套接字,Kafka,Flume,Twitter等。在我们的示例中,我们将使用MapR Streams,这是一种新的分布式消息传递系统,用于大规模流式传输事件数据。 MapR Streams使生产者和消费者可以通过Apache Kafka 0.9 API实时交换事件。 MapR Streams通过Kafka直接方法与Spark Streaming集成。
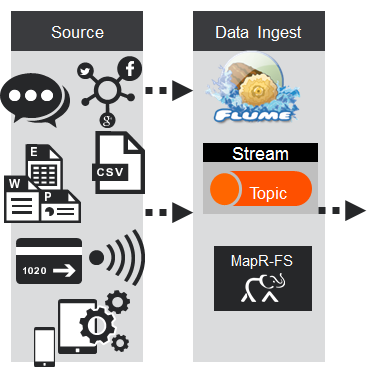
MapR流(或Kafka)主题是消息的逻辑集合。 主题将事件组织成类别。 主题将生产者和消费者分离开来,生产者是数据的来源,消费者是处理,分析和共享数据的应用程序。
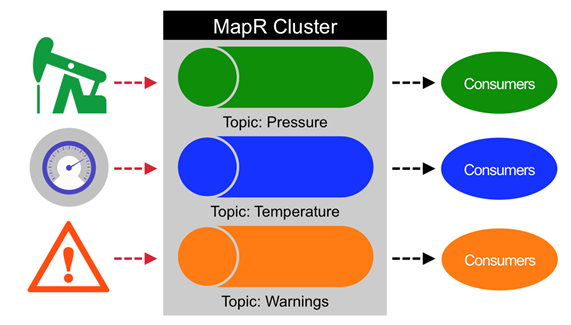
对主题进行了分区以提高吞吐量和可伸缩性。 分区通过将主题的负载分散在多个服务器上,使主题可伸缩。 生产者在分区之间实现负载均衡,并且可以将使用者分组,以从一个主题中的多个分区并行读取数据,从而提高性能。 分区并行消息传递是实现大规模高性能的关键。
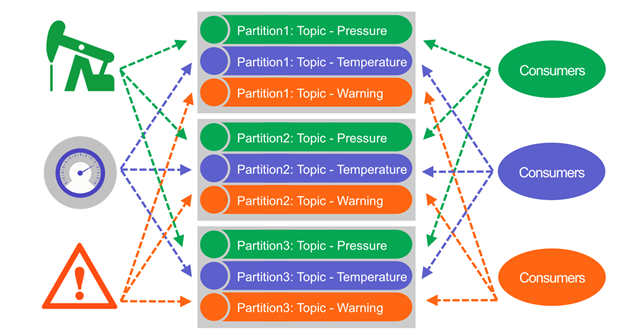
大规模高性能的另一个关键是最大程度地减少磁盘读取和写入所花费的时间。 与旧的消息传递系统相比,Kafka和MapR Streams消除了在每个消息,每个侦听器的基础上跟踪消息确认的需求。 消息在产生时按顺序持久保存,并在消耗时按顺序读取。 这些设计决定意味着很少要进行非顺序读取或写入,并且可以以很高的速度处理消息。 MapR Streams性能随着在群集中添加服务器而线性扩展,每台服务器每秒处理超过一百万条消息。
使用Spark Streaming进行实时数据处理
Spark Streaming将Spark的API引入流处理,使您可以使用相同的API进行流处理和批处理。 数据流可以使用Spark的核心API,DataFrames,GraphX或机器学习API进行处理,并且可以持久存储到文件系统,HDFS,MapR-FS,MapR-DB,HBase或任何提供Hadoop OutputFormat或Spark的数据源中连接器。
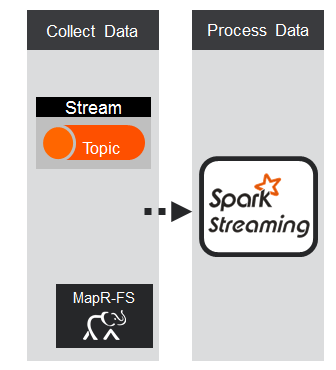
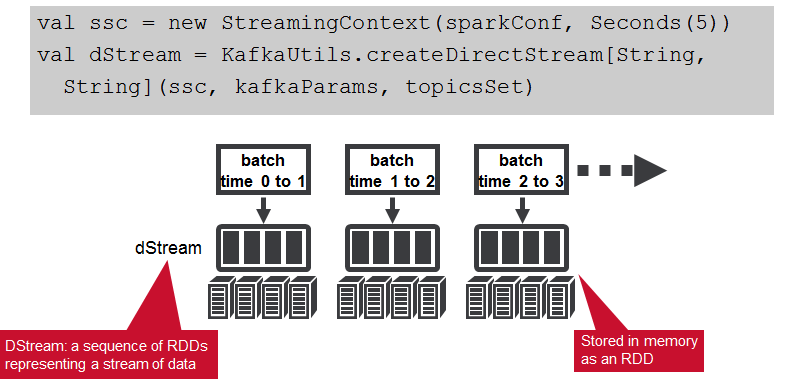
Spark Streaming将数据流分成X秒的批处理,称为Dstream,在内部是一系列RDD,每个批处理间隔一个。 每个RDD包含在批处理间隔内收到的记录。
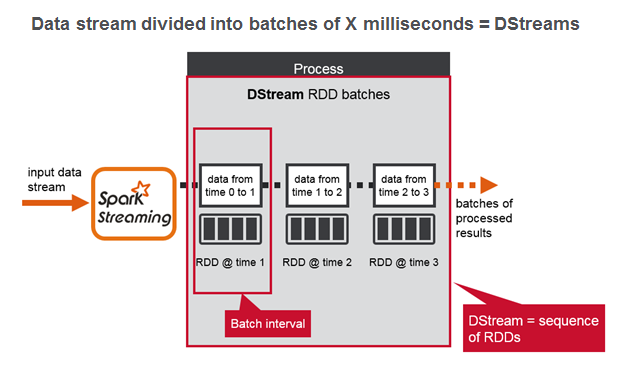
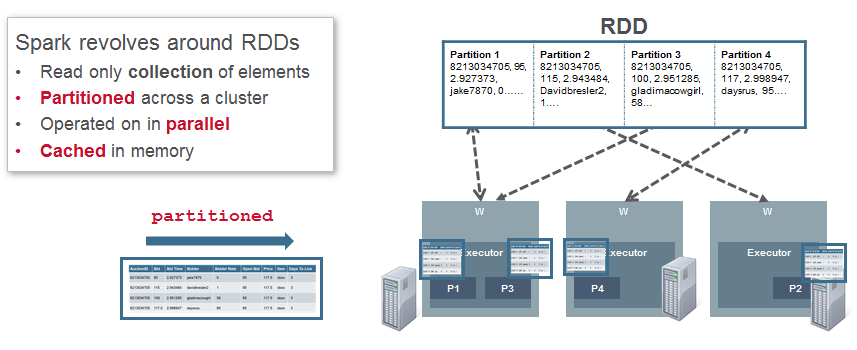
弹性分布式数据集或RDD是Spark中的主要抽象。 RDD是元素的分布式集合,就像Java集合一样,只是它分布在集群中的多个节点上。 对RDD中包含的数据进行分区,并对缓存在内存中的数据并行执行操作。 Spark将RDD缓存在内存中,而MapReduce涉及更多的磁盘读写操作。 同样,大规模实现高性能的关键是分区和最小化磁盘I / O。
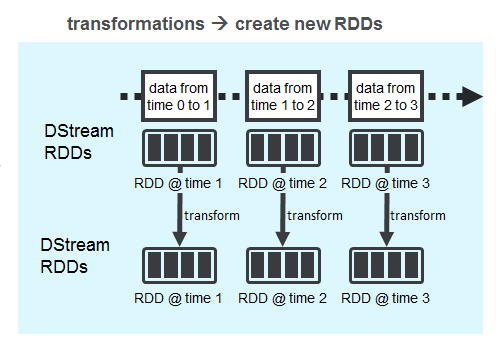
DStream上有两种类型的操作:转换和输出操作。
您的Spark应用程序使用Spark转换(例如map,reduce和join)处理DStream RDD,这些转换会创建新的RDD。 在DStream上执行的任何操作都会转换为对基础RDD的操作,进而将转换应用于RDD的元素。
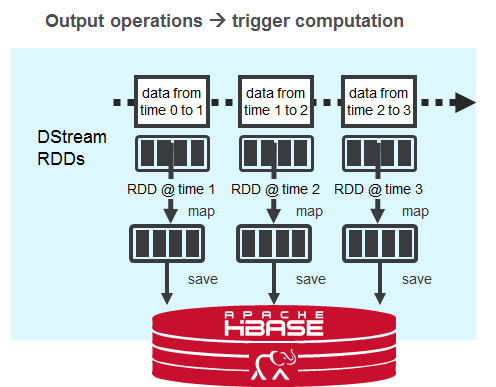
输出操作将数据写入外部系统,分批产生输出。
输出操作的示例是saveAsHadoopFiles(保存到与Hadoop兼容的文件系统中)和saveAsHadoopDataset(保存到任何Hadoop支持的存储系统中)。
使用HBase存储流数据
为了存储大量流数据,我们需要一个支持快速写入和扩展的数据存储。
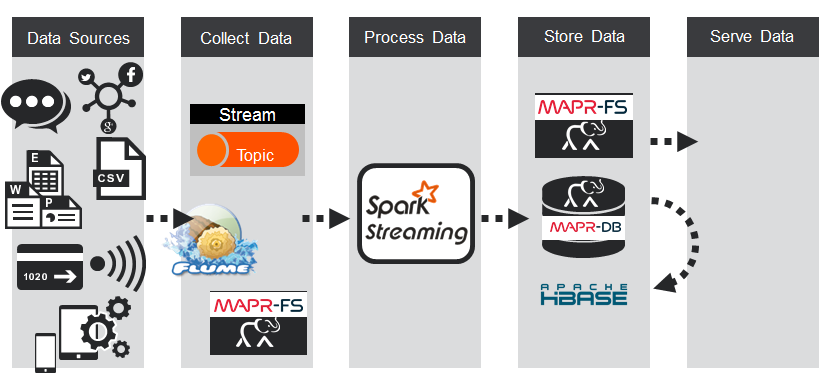
使用MapR-DB(HBase API),可以通过键范围在群集中自动对表进行分区,并且每个服务器都是表子集的源。 按键范围对数据进行分组可提供真正快速的按行键读写。
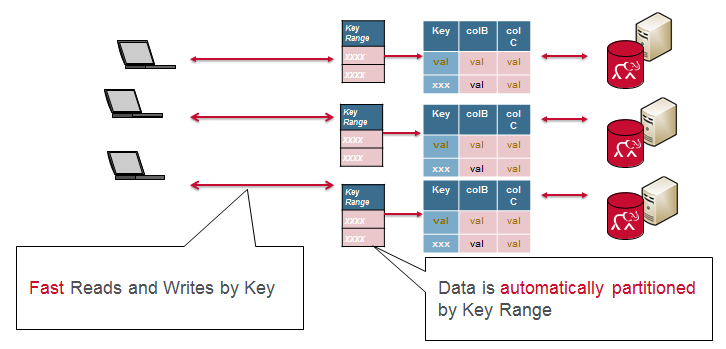
同样,对于MapR-DB,表的每个分区子集或区域都具有读写缓存。 写操作在缓存中排序,并附加到WAL; 对磁盘的写入和读取始终是顺序的; 内存中有最近读取或写入的数据以及缓存的列族; 所有这些都提供了真正的快速读写。
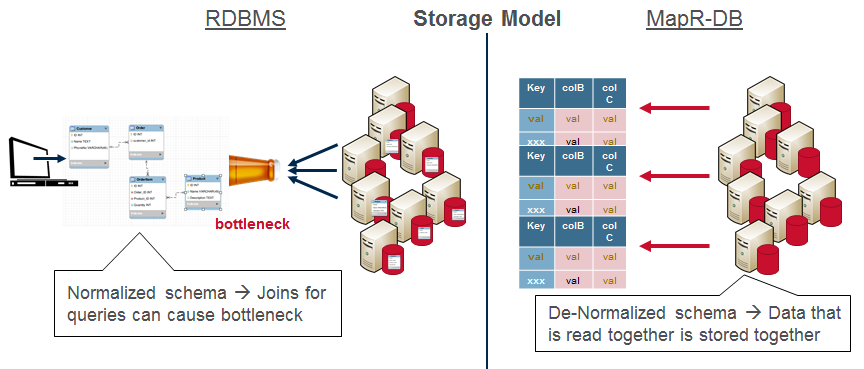
使用关系数据库和规范化的架构,查询联接会导致包含大量数据的瓶颈。 由于一起读取的数据存储在一起,因此MapR-DB和非规范化架构得以扩展。
那么,我们如何大规模地收集,处理和存储高性能的实时事件? 关键是分区,缓存和最大程度地减少磁盘读写时间:
- 使用MapR流进行消息传递
- 使用Spark Streaming进行处理
- 使用MapR-DB进行存储
服务数据
最终应用程序(如仪表板,商业智能工具和其他应用程序)使用已处理的事件数据。 处理输出也可以存储在MapR-DB中的另一个列族或表中,以备后用。
示例用例代码
现在,我们将逐步处理用于发送消息的MapR Streams生产者以及用于处理事件并将数据存储在MapR-DB中的Spark Streaming的代码。
MapR Streams生产者代码
生产者发送消息的步骤是:
- 设置生产者属性
- 第一步是设置KafkaProducer配置属性,稍后将使用该属性实例化KafkaProducer,以将消息发布到主题。
- 创建一个KafkaProducer
- 您可以通过提供第一步中设置的一组键值对配置属性来实例化KafkaProducer。 请注意,KafkaProducer <K,V>是Java通用类。 您需要将类型参数指定为生产者将发送的消息的键值类型。
- 生成ProducerRecord消息
- ProducerRecord是要发送给Kafka的键/值对。 它由记录要发送到的主题名称,可选的分区号,可选的键和消息值组成。 ProducerRecord还是Java通用类,其类型参数应与之前设置的序列化属性匹配。 在此示例中,我们以主题名称和消息文本作为值实例化ProducerRecord,这将创建一个没有键的记录。
- 发送信息
- 在传递给ProducerRecord的KafkaProducer上调用send方法,它将异步地将记录发送到指定的主题。 此方法返回Java Future对象,该对象最终将包含响应信息。 异步send()方法将记录添加到要发送的待处理记录的缓冲区中,并立即返回。 这允许并行发送记录,而无需等待响应,并且可以批量记录以提高效率。
- 最后,在生产者上调用close方法以释放资源。 该方法将阻塞,直到所有请求都完成。
代码如下所示:

Spark流代码
这些是Spark Streaming代码的基本步骤:
- 初始化Spark StreamingContext对象。 使用此上下文,创建一个DStream。
- 我们使用KafkaUtils createDirectStream方法从Kafka或MapR Streams主题创建输入流。 这将创建一个DStream来表示传入数据流,其中每个记录都是一行文本。
- 我们使用KafkaUtils createDirectStream方法从Kafka或MapR Streams主题创建输入流。 这将创建一个DStream来表示传入数据流,其中每个记录都是一行文本。
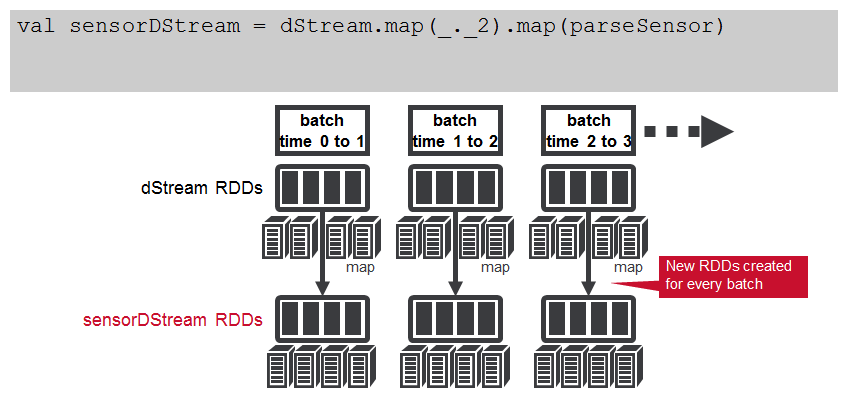
- 应用转换(创建新的DStreams)
- 我们使用dStream上的map操作将消息值解析为Sensor对象。 映射操作对dStream中的RDD应用Sensor.parseSensor函数,从而生成Sensor对象的RDD。对DStream应用的任何操作都将转换为对基础RDD的操作。 映射操作应用于dStream中的每个RDD,以生成sensorDStream RDD。
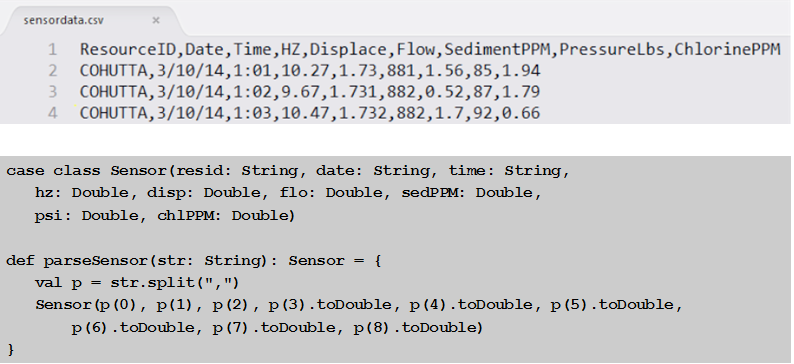
油泵传感器数据以逗号分隔值的字符串形式输入。 我们使用Scala案例类定义与传感器数据相对应的Sensor模式,并使用parseSensor函数将逗号分隔的值解析为传感器案例类。
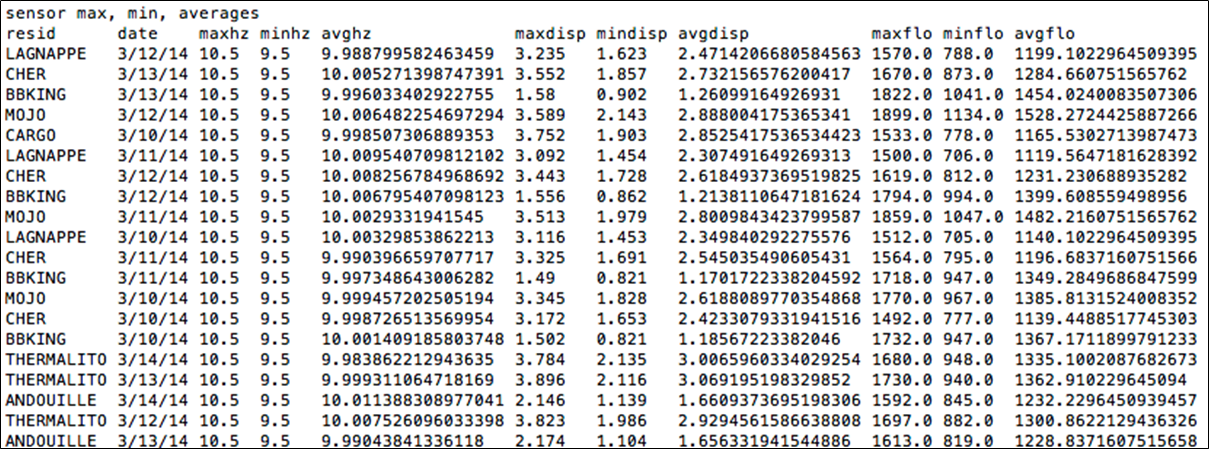
接下来,我们使用DStream foreachRDD方法将处理应用于此DStream中的每个RDD。 我们将DataFrame注册为一个表,这使我们可以在后续SQL语句中使用它。 我们使用SQL查询查找传感器属性的最大值,最小值和平均值。
这是查询的示例输出,其中显示了传感器的最大,最小和平均输出。
- 我们使用dStream上的map操作将消息值解析为Sensor对象。 映射操作对dStream中的RDD应用Sensor.parseSensor函数,从而生成Sensor对象的RDD。对DStream应用的任何操作都将转换为对基础RDD的操作。 映射操作应用于dStream中的每个RDD,以生成sensorDStream RDD。
- 和/或应用输出操作
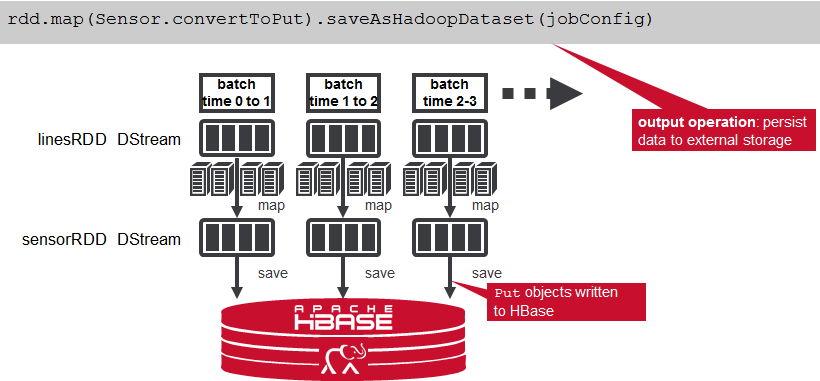
- 将sensorRDD对象过滤为低psi,将传感器和警报数据转换为Put对象,然后使用saveAsHadoopDataset方法写入HBase。 这会将RDD使用该存储系统的Hadoop配置对象输出到任何受Hadoop支持的存储系统。
- 将sensorRDD对象过滤为低psi,将传感器和警报数据转换为Put对象,然后使用saveAsHadoopDataset方法写入HBase。 这会将RDD使用该存储系统的Hadoop配置对象输出到任何受Hadoop支持的存储系统。
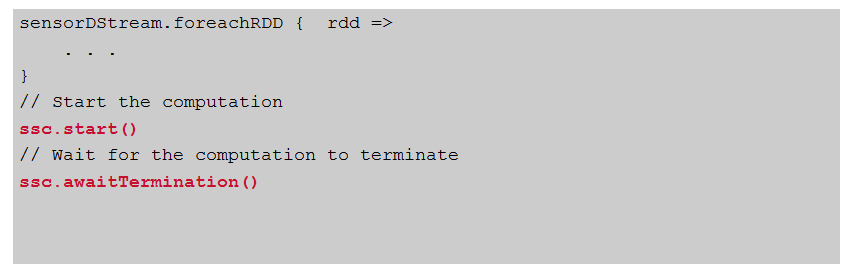
- 开始接收数据并进行处理。 等待处理停止。
- 要开始接收数据,我们必须在StreamingContext上显式调用start(),然后调用awaitTermination以等待流计算完成。
- 要开始接收数据,我们必须在StreamingContext上显式调用start(),然后调用awaitTermination以等待流计算完成。

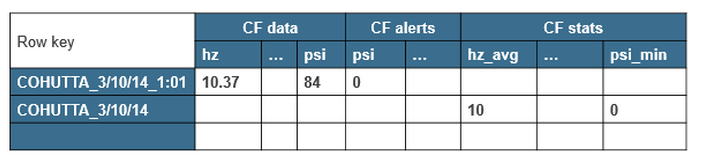
HBase表架构
流数据的HBase表架构如下:
- 泵名称日期和时间戳的复合行键
具有与输入数据字段相对应的列的列族数据与与任何警报值过滤器相对应的列的列族警报请注意,可以将数据和警报列族设置为在一定时间后过期。
每日统计信息摘要汇总的架构如下:
- 泵名称和日期的复合行键
- 列族统计
- 最小值,最大值,平均值列。
我们刚才讨论的用例架构的所有组件都可以与MapR融合数据平台一起在同一集群上运行。 将MapR流与所有其他组件放在同一群集上有几个优点。 例如,仅维护一个集群就意味着更少的基础架构来进行配置,管理和监视。 同样,将生产者和消费者放在同一个集群上意味着与在集群之间以及在应用程序之间复制和移动数据有关的延迟更少。
软件
本教程将在MapR v5.1沙盒上运行,该沙盒包括MapR流,Spark和HBase(MapR-DB)。
您可以从此处下载代码,数据和说明以运行此示例:
摘要
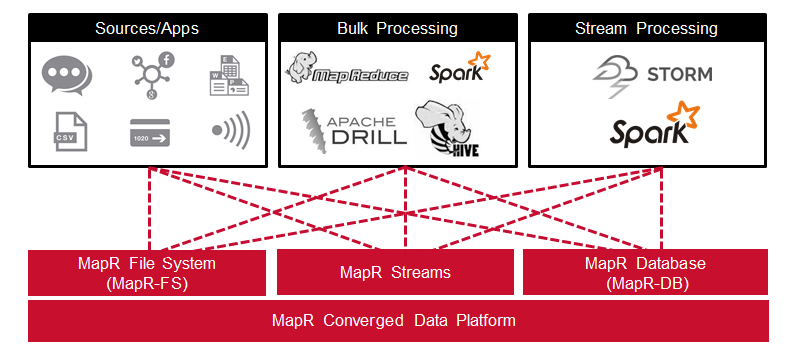
在此博客文章中,您了解了MapR融合数据平台如何将Hadoop和Spark与实时数据库功能,全局事件流和可伸缩企业存储集成在一起。
参考和更多信息:
- 在learning.mapr.com上免费获得有关MapR Streams,Spark和HBase的在线培训
- MapR Streams博客入门
- Apache Spark入门:从创建到生产电子书
- Apache Spark流编程指南
mapr-fs 架构















 3086
3086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









