





gora 数据实体
我曾在Apache Gora的Spark后端工作,作为我的GSoC 2015项目并完成了它。 在此博客文章中,我将解释其工作原理和使用方法。 首先,我建议你看我以前的帖子关于我的编程之夏2015年接受: http://furkankamaci.com/gsoc-2015-acceptance-for-apache-gora/和Apache戈拉: HTTP://www.javacodegeeks。 com / 2015/08 / in-memory-data-model-and-persistence-for-big-data.html(如果您尚未阅读)。
Apache Gora提供了内存中的数据模型和大数据的持久性。 Gora支持持久存储到列存储,键值存储,文档存储和RDBMS,并通过广泛的Apache Hadoop MapReduce支持来分析数据。 粗略地说,Gora是一个功能强大的项目,可以像NoSQL世界的Hibernate一样工作,并且可以在其上运行Map / Reduce作业。 与Gora当前支持的Map / Reduce相比,Spark是如此强大。 有对戈拉无火花后端和我的编程之夏项目的目的是。
我将在日志分析示例中讲解Spark后端的实现。 它将使用永久保存在数据存储中的Apache服务器日志。 我建议您下载并编译Gora源代码( https://github.com/apache/gora ),并阅读Gora教程( http://gora.apache.org/current/tutorial.html )以查找并保存示例日志。 您可以在Gora上使用其内置脚本来保留示例数据。
由于我们使用的是Apache Gora,因此我们可以使用Hbase,Solr,MongoDB等(作为完整列表: http ://gora.apache.org/)作为数据存储。 Gora将独立于所使用的数据存储来运行代码。 在此示例中,我将保留一组示例性的Apache服务器日志到Hbase( 版本:1.0.1.1 )中,从那里读取它们,在其上运行Spark代码并将结果写入Solr( 版本:4.10.3 )中。 。
首先,启动数据存储以读取值。 我将启动Hbase作为持久性数据存储区:
furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/start-hbase.sh
starting master, logging to /home/furkan/apps/hbase-1.0.1.1/bin/../logs/hbase-furkan-master-kamaci.out持续性示例登录到Hbase(在执行此命令之前,您应该已提取access.log.tar.gz ):
furkan@kamaci:~/projects/gora$ ./bin/gora logmanager -parse gora-tutorial/src/main/resources/access.log运行parse命令后,运行hbase的shell命令:
furkan@kamaci:~/apps/hbase-1.0.1.1$ ./bin/hbase shell
2015-08-31 00:20:16,026 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.0.1.1, re1dbf4df30d214fca14908df71d038081577ea46, Sun May 17 12:34:26 PDT 2015并运行列表命令。 如果之前在Hbase上没有任何表,则应该在下面看到输出:
hbase(main):025:0> list
TABLE
AccessLog
1 row(s) in 0.0150 seconds
=> ["AccessLog"]检查表中是否存在任何数据:
hbase(main):026:0> scan 'AccessLog', {LIMIT=>1}
ROW COLUMN+CELL
\x00\x00\x00\x00\x00\x00\x00\x00 column=common:ip, timestamp=1440970360966, value=88.240.129.183
\x00\x00\x00\x00\x00\x00\x00\x00 column=common:timestamp, timestamp=1440970360966, value=\x00\x00\x01\x1F\xF1\xAElP
\x00\x00\x00\x00\x00\x00\x00\x00 column=common:url, timestamp=1440970360966, value=/index.php?a=1__wwv40pdxdpo&k=218978
\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpMethod, timestamp=1440970360966, value=GET
\x00\x00\x00\x00\x00\x00\x00\x00 column=http:httpStatusCode, timestamp=1440970360966, value=\x00\x00\x00\xC8
\x00\x00\x00\x00\x00\x00\x00\x00 column=http:responseSize, timestamp=1440970360966, value=\x00\x00\x00+
\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:referrer, timestamp=1440970360966, value=http://www.buldinle.com/index.php?a=1__WWV40pdxdpo&k=218978
\x00\x00\x00\x00\x00\x00\x00\x00 column=misc:userAgent, timestamp=1440970360966, value=Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
1 row(s) in 0.0810 seconds要将结果写入Solr,请创建一个名为Metrics的无模式核心。 要轻松做到这一点,您可以将collection1的默认核心重命名为solr-4.10.3 / example / example-schemaless / solr文件夹中的Metrics ,然后编辑/home/furkan/Desktop/solr-4.10.3/example/example- schemaless / solr / Metrics / core.properties为:
name=Metrics然后为Solr运行启动命令:
furkan@kamaci:~/Desktop/solr-4.10.3/example$ java -Dsolr.solr.home=example-schemaless/solr/ -jar start.jar让我们开始这个例子。 从Hbase读取数据,生成一些指标,然后通过Gora将结果写入Spark。 下面是如何进出数据存储初始化:
public int run(String[] args) throws Exception {
DataStore<Long, Pageview> inStore;
DataStore<String, MetricDatum> outStore;
Configuration hadoopConf = new Configuration();
if (args.length > 0) {
String dataStoreClass = args[0];
inStore = DataStoreFactory.getDataStore(
dataStoreClass, Long.class, Pageview.class, hadoopConf);
if (args.length > 1) {
dataStoreClass = args[1];
}
outStore = DataStoreFactory.getDataStore(
dataStoreClass, String.class, MetricDatum.class, hadoopConf);
} else {
inStore = DataStoreFactory.getDataStore(Long.class, Pageview.class, hadoopConf);
outStore = DataStoreFactory.getDataStore(String.class, MetricDatum.class, hadoopConf);
}
...
}传递输入数据存储的键和值类,并实例化GoraSparkEngine :
GoraSparkEngine<Long, Pageview> goraSparkEngine = new GoraSparkEngine<>(Long.class,
Pageview.class);构造一个JavaSparkContext。 将输入数据存储的值类注册为Kryo类:
SparkConf sparkConf = new SparkConf().setAppName(
"Gora Spark Integration Application").setMaster("local");
Class[] c = new Class[1];
c[0] = inStore.getPersistentClass();
sparkConf.registerKryoClasses(c);
JavaSparkContext sc = new JavaSparkContext(sparkConf);您可以从输入数据存储中获取JavaPairRDD:
JavaPairRDD<Long, Pageview> goraRDD = goraSparkEngine.initialize(sc, inStore);得到它后,就可以像为Spark编写代码一样对其进行处理! 例如:
long count = goraRDD.count();
System.out.println("Total Log Count: " + count);这是本示例的map和reduce阶段的函数:
/** The number of milliseconds in a day */
private static final long DAY_MILIS = 1000 * 60 * 60 * 24;
/**
* map function used in calculation
*/
private static Function<Pageview, Tuple2<Tuple2<String, Long>, Long>> mapFunc = new Function<Pageview, Tuple2<Tuple2<String, Long>, Long>>() {
@Override
public Tuple2<Tuple2<String, Long>, Long> call(Pageview pageview)
throws Exception {
String url = pageview.getUrl().toString();
Long day = getDay(pageview.getTimestamp());
Tuple2<String, Long> keyTuple = new Tuple2<>(url, day);
return new Tuple2<>(keyTuple, 1L);
}
};/**
* reduce function used in calculation
*/
private static Function2<Long, Long, Long> redFunc = new Function2<Long, Long, Long>() {
@Override
public Long call(Long aLong, Long aLong2) throws Exception {
return aLong + aLong2;
}
};/**
* metric function used after map phase
*/
private static PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum> metricFunc = new PairFunction<Tuple2<Tuple2<String, Long>, Long>, String, MetricDatum>() {
@Override
public Tuple2<String, MetricDatum> call(
Tuple2<Tuple2<String, Long>, Long> tuple2LongTuple2) throws Exception {
String dimension = tuple2LongTuple2._1()._1();
long timestamp = tuple2LongTuple2._1()._2();
MetricDatum metricDatum = new MetricDatum();
metricDatum.setMetricDimension(dimension);
metricDatum.setTimestamp(timestamp);
String key = metricDatum.getMetricDimension().toString();
key += "_" + Long.toString(timestamp);
metricDatum.setMetric(tuple2LongTuple2._2());
return new Tuple2<>(key, metricDatum);
}
};/**
* Rolls up the given timestamp to the day cardinality, so that data can be
* aggregated daily
*/
private static long getDay(long timeStamp) {
return (timeStamp / DAY_MILIS) * DAY_MILIS;
}这是在现有的JavaPairRDD上运行map和简化功能的方法 :
JavaRDD<Tuple2<Tuple2<String, Long>, Long>> mappedGoraRdd = goraRDD
.values().map(mapFunc);
JavaPairRDD<String, MetricDatum> reducedGoraRdd = JavaPairRDD
.fromJavaRDD(mappedGoraRdd).reduceByKey(redFunc).mapToPair(metricFunc);当您想将结果持久化到输出数据存储中时(在我们的示例中为Solr),应按以下步骤进行操作:
Configuration sparkHadoopConf = goraSparkEngine.generateOutputConf(outStore);
reducedGoraRdd.saveAsNewAPIHadoopDataset(sparkHadoopConf);就这样! 检查Solr以查看结果:
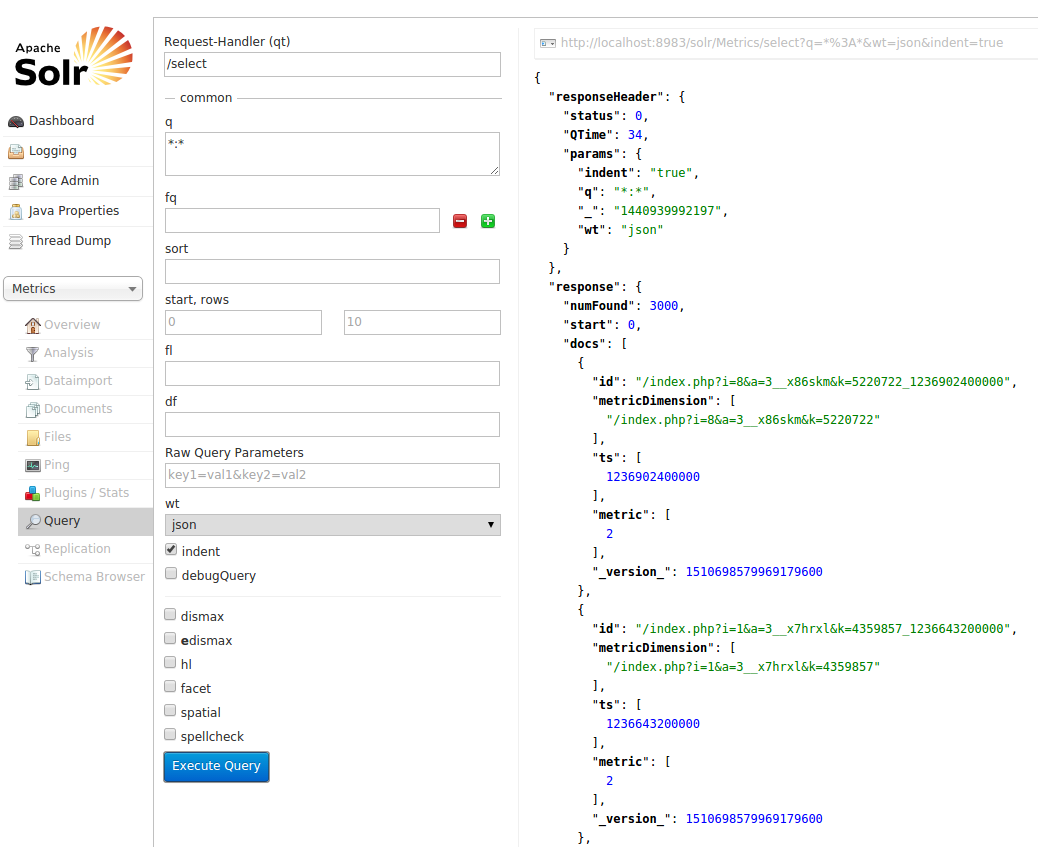
您会看到一个人可以从数据存储区(即Hbase)读取数据,在其上运行Spark代码(映射/归约),然后将结果写入相同或另一个数据存储区(即Solr)。 GoraSparkEngine为Apache Gora提供了Spark后端功能,我认为它将使Gora更加强大。
翻译自: https://www.javacodegeeks.com/2015/09/spark-backend-for-apache-gora.html
gora 数据实体















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









