





线性模型 广义线性模型
之前,我曾写过一个线性模型 , 该模型是用来预测有多少人会在聚会上对RSVP“是”的,并且没有发现我的任何自变量与RSVP之间有太大的相关性。
幸运的是,一个月前,我在一次聚会上碰到了安东尼奥,他提议看看我到目前为止所做的一切,并给我一些进步的技巧。
他指出的第一件事是,我所有的功能都与日期/时间有关,我应该尝试生成一些其他功能。 他建议我从以下内容开始:
- 有关组织者的信息(量化组织者的知名度,为他们工作的人数)
- 有关会场的信息(有多少人适合在那里,离市中心有多远)
- 活动前X天内活动的推文数量
我在Kaggle 论坛上读了很多关于要素工程如何成为构建统计模型的最重要部分的内容,但是直到Antonios指出这一点之后,它才按其含义。
我决定要做的第一件事是为伦敦所有NoSQL聚会提供数据,而不仅仅是Neo4j,以便为自己提供更多数据。
团体会员
这样做之后,从视觉检查看来,成员最多的聚会小组(即伦敦数据科学,伦敦大数据)似乎获得了最多的支持。
我认为查看组成员身份和RSVP之间的相关性会很有趣,因此这是我添加的第一个新功能。
我通过Neo4j查询和R代码的组合生成了此功能,该结果导致此数据帧为CSV文件 。
我们可以快速预览它,以查看当时的一些事件和组成员身份:
> df = read.csv("/tmp/membersWithGroupCounts.csv")
> df$eventTime = as.POSIXct(df$eventTime)
> df %>% sample_n(10) %>% select(event.name, g.name, eventTime, groupMembers, rsvps)
event.name g.name eventTime groupMembers rsvps
23 Scoring Models, Apache Drill for querying structured & unstructured data Data Science London 2014-09-18 18:30:00 3466 159
421 London Office Hours London MongoDB User Group 2012-08-22 17:00:00 468 6
304 MongoDB University Study Group London Meet up London MongoDB User Group 2014-07-16 17:00:00 1256 23
43 December Meetup London ElasticSearch User Group 2014-12-10 18:30:00 721 126
222 Intro to Graphs Neo4j - London User Group 2014-09-03 18:30:00 1453 39
207 Intro to Machine Learning with Scikit-Learn Women in Data 2014-11-11 18:15:00 574 41
168 NoSQL panel and LevelDB + Node.js London NoSQL 2014-04-15 18:30:00 183 51
443 London Office Hours London MongoDB User Group 2012-11-29 17:00:00 590 3
79 Apache Cassandra 1.2 with Jonathan Ellis Cassandra London 2013-03-06 19:00:00 399 95
362 Span conference Span: scalable and distributed computing 2014-10-28 09:00:00 67 13我发现困难的一件事是找到特定于事件的功能–我不确定这有多重要。 我可以更轻松地为场地或团队生成功能。
首先,通过绘制两个变量,看看它们之间是否确实存在任何相关性:
ggplot(aes(x = groupMembers, y = rsvps), data = df) +
geom_point() 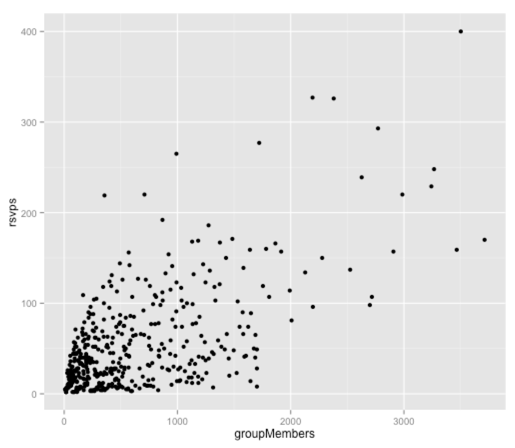
看起来这两个变量之间存在正相关,但让我们创建一个单变量线性模型以查看解释了多少变化:
> fit = lm(rsvps ~ groupMembers, data = df)
> fit$coef
(Intercept) groupMembers
20.03579637 0.05382738因此,我们的线性模型方程为:
rsvps = 20.03579637 + 0.05382738(groupMembers)
让我们看看预测的RSVP和实际RSVP的相关程度如何:
> df$predictedRSVPs = predict(fit, df)
> with(df, cor(rsvps, predictedRSVPs))
[1] 0.6263096还不错! 尽管这些变量并不完美,但它们之间具有很强的相关性。
数小时
在我的第一个模型中,我将时间视为分类变量,但是Antonios指出,如果变量都是连续的,通常更容易理解变量之间的关系,因此我将事件时间转换为:
df$hoursIntoDay = as.numeric(df$eventTime - trunc(df$eventTime, "day"), units="hours")让我们看一下如何针对RSVP计数进行绘制:
ggplot(aes(x = hoursIntoDay, y = rsvps), data = df) +
geom_point() 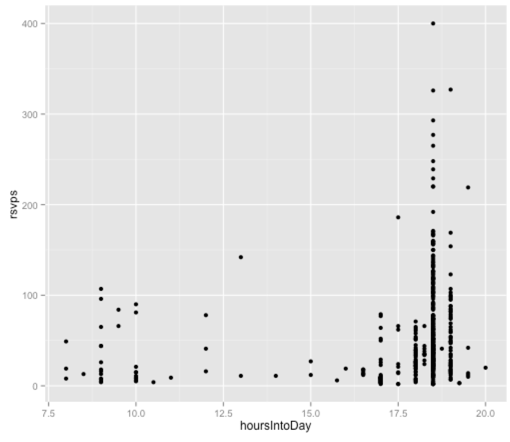
在这里看到趋势要困难一些,因为事件发生的时间是非常离散的,并且大多数时间是从6.30或7.00开始的。 不过,让我们仅使用此变量构建线性模型:
> fit = lm(rsvps ~ hoursIntoDay, data = df)
> fit$coef
(Intercept) hoursIntoDay
-18.79895 4.12984
>
> df$predictedRSVPs = predict(fit, df)
> with(df, cor(rsvps, predictedRSVPs))
[1] 0.181472距伦敦市中心的距离
接下来,我根据事件所在的地点尝试了一项功能。 假设是,如果场地更靠近伦敦市中心,那么人们将更有可能参加。
为了计算该距离,我使用了geosphere软件包中的distHaversine函数, 如先前的博客文章中所示 。
让我们看一下该变量的图形:
ggplot(aes(x = distanceFromCentre, y = rsvps), data = df) +
geom_point() 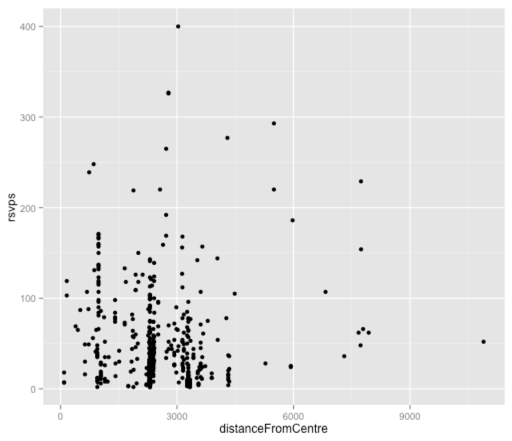
从该图很难说出很多,主要是因为大多数点聚集在代表Shoreditch场地的2500米标记附近。 让我们将其插入线性模型,看看我们得出了什么:
> fit = lm(rsvps ~ distanceFromCentre, data = df)
> fit$coef
(Intercept) distanceFromCentre
57.243646619 -0.001310492
>
> df$predictedRSVPs = predict(fit, df)
> with(df, cor(rsvps, predictedRSVPs))
[1] 0.02999708有趣的是,这里几乎没有任何关联,这令我感到惊讶。 我尝试将此变量与其他变量组合成一个多变量模型,但是它仍然没有太大的影响,因此我认为我们现在将其停放。
这和我目前所做的一样多,尽管花了很多时间,但我仍然没有真正解释RSVP速率的变化!
我设法找到了一些可以提出新功能的方法,但可以尝试一下:
- 阅读其他人在做什么,例如,在了解了此棒球线性模型后,我对滞后变量有一些想法(例如,有多少人参加了您以前的聚会)
- 与其他人讨论您的模型-他们经常会有您不会想到的太多想法。
- 查看您已经拥有的数据,然后尝试将其合并,并查看导致的结果
我开始探索的下一个途径是主题建模,因为我有一个假设,即人们根据会谈的内容对事件进行回复,但是我不确定这样做的最佳方法。
我目前的想法是通过遵循《 面向黑客的机器学习》 第6章中的示例来提取一些主题/术语。
翻译自: https://www.javacodegeeks.com/2014/12/r-featuring-engineering-for-a-linear-model.html
线性模型 广义线性模型















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









