





cap与cap2有何区别
今天,我喜欢写有关分布式计算机系统中的一个重要定理。 我敢肯定,您会注意到本文的主题是关于CAP定理(也称为Brewer定理)的。 埃里克·布鲁尔(Eric Brewer)是2000年提出CAP定理的人。
CAP是三个单词的首字母缩写:
一致性:所有节点必须读取最新更改的数据,换句话说,我们分布式系统中的每个节点都应读取相同的数据。 如果在一个节点中发生了写操作,则从另一个节点读取相同的数据必须返回最新的写操作(当系统收到更新的内容时,则不得返回任何较旧的数据项)
可用性:不得有任何请求被任何节点阻止,所有请求都必须具有有关请求状态的响应。
分区容限:系统将继续其便利的任务,即使丢失了任何消息或系统中存在一些故障部件。
CAP定理是关于不可能在系统中同时拥有所有这些属性的。 distributed每个分布式系统最多可以具有这三个属性中的两个。 大多数参考文献将CAP介绍为一个三角形,分布式系统可以仅将其两个角度作为一个三角形。
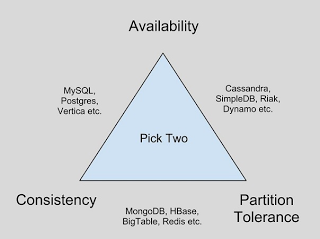
CAP三角形
一致性+可用性的示例是:
- 单节点数据库
- 集群数据库
- LDAP
- xFS文件系统
一致性+分区容限的示例是:
- 分布式数据库
- 分布式锁定
- 多数锁定
可用性+分区容限的示例如下:
- 结尾
- Web缓存
- 域名解析
您可以在以下位置阅读CAP定理的形式证明: 布鲁尔猜想和一致,可用,可容忍分区的Web的可行性 。 这不是很难,阅读本文可以为您清除所有内容。
但是在这篇文章中,我用一些理由证明了这个概念。
假设:在一个简单的分布式系统中,我们有两个节点: NODE A和NODEB。客户端在NODE A上写入“ DataItem1”,同时客户端请求在NODE B上读取“ DataItem1”。
假设我们拥有CA环境,那么所有节点中的所有数据都是一致的,并且所有节点都可以执行每个查询。如果节点之间的所有消息均失败,则对节点B的查询将无法获得数据项的最新值。 如您所见,在某些情况下,我们无法使用带有“ P”的“ CA”环境。
假设我们拥有CP环境,那么所有节点中的所有数据都是一致的,并且具有分区容限属性。 现在,如果在NODE上写入“ DataItem1”之前,两个节点之间的连接断开,向节点B的请求无法执行我们的查询,因此Web错过了可用性。 节点B希望将其数据与NODE A同步,但是连接断开,因此响应不可用。
假设我们有PA环境。 因此,来自节点的每个请求都会有一个响应,分区容限允许我们的系统在发生任何消息和系统故障时继续其任务。 如果客户端在节点A上写入“ DataItem1”,并且同时其他客户端向节点B发送对“ DataItem1”的请求,并且两个节点之间的连接断开,则客户端将读取“ DataItem1”的旧版本。
注意:节点之间的通信和同步可能会延迟,这是PA系统完全无法保持一致性的最重要原因。 在这些环境中,节点之间具有部分一致性。
翻译自: https://www.javacodegeeks.com/2013/09/cap-is-not-just-for-your-head.html
cap与cap2有何区别















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









