





 本文探讨了数据库设计中冗余的问题,包括物理冗余、逻辑冗余和算法冗余,分析了冗余可能带来的安全性、质量和可维护性风险。作者建议通过明确领域边界、应用关注点分离等方法避免冗余,并在无法避免时采取控制措施,如非功能性要求、质量要求、安全要求和单独的上下文。最后,文章强调冗余是领域建模中需要关注的重要问题。
本文探讨了数据库设计中冗余的问题,包括物理冗余、逻辑冗余和算法冗余,分析了冗余可能带来的安全性、质量和可维护性风险。作者建议通过明确领域边界、应用关注点分离等方法避免冗余,并在无法避免时采取控制措施,如非功能性要求、质量要求、安全要求和单独的上下文。最后,文章强调冗余是领域建模中需要关注的重要问题。
数据库设计冗余
介绍
设计域可能是一个真正的挑战。 许多错误的做法很容易使您陷入错误的设计中,并且在大多数情况下,只有在业务逻辑开发的高级阶段之后才能发现这些问题。
幸运的是,有几种好的设计方法和“哲学”,例如Eric Evans的“ 域驱动设计” 。
我想在这篇文章中指出的是,并非总是可以避免冗余 ,而且并非总是如此。 在介绍了所有应真正避免冗余的情况之后,我将讨论其原因。
什么是冗余?
让我们开始分析数据库和域建模中的冗余。
关于数据库建模,我们称数据冗余为以下情况:相同的信息物理上位于不同数据库表的两列或更多列中。 在其中一个中更改它会导致其他不一致。
关于域设计 (实际上,我们不是在谈论表或对象,而是实体),它是指相同信息由不同实体拥有的情况。 此处的主要原因可能是对纯域的不了解或所涉及实体的上下文分离不明确。
域模型中的冗余将自动反映在数据库模型中,因此在实现域之前对其进行检查非常重要。
有什么风险?
在模型中具有不必要的冗余的风险是多种的,并且可能影响不同的方面:
- 安全性 :边界内不一致的数据可能会引起有关其用法的安全问题
- 质量 :您可以信任数据吗? 你能证明这个吗?
- 验证 :模型的验证在很大程度上取决于外部参与者,这也必须得到证明和验证。 与失败相关的风险是什么? 可以恢复诚信吗?
- 可维护性 :重复的数据很难维护,随着模型的发展,变更的所有影响都必须正确地分析和应用
避免某些类型的冗余
有多种原因可以使您在模型中创建不必要的冗余。 我认为将它们分为3个主要类别可能很有趣:
- 物理冗余
- 逻辑冗余
- 算法冗余
物理冗余
这种冗余是最简单的方法,只需最少的经验即可检测到。 当在域中重复相同的信息(跨越多个实体或同一实体的多个实例)时,就会发生这种情况。 这通常是由于对业务领域的了解不清而导致的。
使用良好的做法(例如,确定聚合之间的边界)将有助于轻松避免此类冗余。
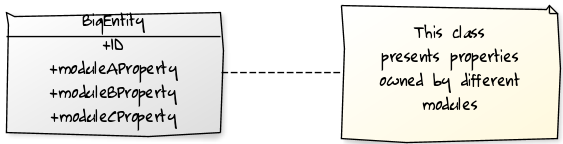
在下面的示例中,单人实体具有大量信息,该实体显然被多收了费用,结果将重复很多数据,因为这两个已婚人士的大多数财产都是相同的(marriedWith正在克隆全名,一旦civilStatus,marriageDate和childs对于两个已婚者来说都是相同的)。

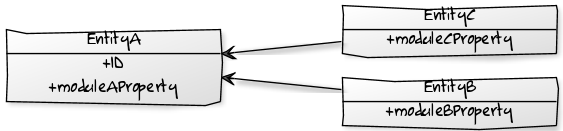
通过确定边界并应用关注点分离,我们可以得出此模型,该模型不再具有数据冗余,而是一个名为Union的新实体以及两个实体之间的清晰边界。

逻辑冗余
有时,信息很容易被数据模型本身推论出来。
在前面的示例中,Person实体的civilStatus属性是数据的逻辑重复,因为可以通过Person和Union之间的关系以及Union实体中的type属性推导出相同的信息。

在这种情况下,必须采取某种措施以避免太复杂的情况。 如果不平衡使用此方法,则可能产生模糊的数据。
算法冗余
另一种要避免的冗余类型是当模型包含两个或更多数据集时,其中至少一个是应用算法的结果,该算法使用其余的作为输入。
下图显示了这种冗余的真实简单示例,以确保它可以存在更复杂的场景。

Person实体中的新属性年龄显然是多余的,因为可以随时使用birthDate属性进行计算。
当无法避免冗余时
当您无法避免不想发生的事情时,您应该尝试控制它!
冗余也是一样。 可能发生几种情况。 在接下来的章节中,我将列出我在职业生涯中一直处理的一些最重要的问题,并描述每种原因以及将其控制在您控制之下的解决方案。 那些是:
- 非功能性要求
- 质量
- 安全
- 单独的上下文
非功能性要求
某些非功能性需求可能会在模型中带来冗余。 例如,如果我们要将模块化原理应用于我们的模型和软件体系结构,则可以在实体跨越不同模块的情况下找到我们。
在这种情况下,为了保持模块性并尊重模块的依赖性和工作流程,您需要将这个实体拆分为小模块控制的实体,以完成此工作。 这样,界限和责任将被清楚地分开。
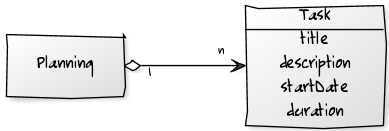
但是,现在我想向您展示一种情况,这种方法将为您带来冗余。 考虑一个简单的项目管理应用程序,您需要在其中定义计划中的任务。 第一个模型如下所示:
现在提出了一个新要求,即:必须在计划中扮演几个角色:
- 角色A负责定义计划的草稿版本,其中包含任务列表及其执行顺序
- 角色B负责定义每个任务的开始日期和持续时间
这两个角色必须在流程工作流的两个不同步骤(A和B)中工作,并且在开始步骤B之前必须对步骤A进行正式验证。
在这种情况下,应用模块化原理将以如下方式转换模型:

该模型清楚地展示了Task实体中新引入的sequence属性与TaskExecution实体中的startDate属性之间的算法冗余 ,因为可以通过任务的开始日期推导序列。 这意味着已引入工作流程中的循环依赖性,但存在许多明显的缺点。
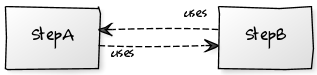
实施明确的关注点分离,检查流中的依赖关系并定义数据流模型可以帮助降低与这种冗余相关的风险。 特别是,要解决此问题,必须弄清两个模块之间的流程,并将StepA定义为主信息,并将StepB定义为信息的从属。 最终流程图如下所示:

一旦依赖关系图:
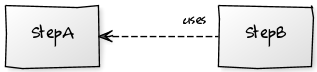
要恢复,更改StepA会影响StepB,但是更改StepB绝不会影响StepA。 换句话说,StepB模型的一致性是通过经过验证的StepA模型进行验证的。
质量要求
质量要求经常要求数据冗余。 我在考虑诸如审核,修订控制,历史记录日志之类的功能 。
此处最好的方法是创建具有明确冗余范围的域的特定部分,该特定部分可以在特定日期存储信息或记录日志。重复的实体可以简化,例如,相同实体的不同模型可以完成了历史数据的管理。 关系,约束等事物也可以在设计域的此部分中简化。 请参见以下示例。
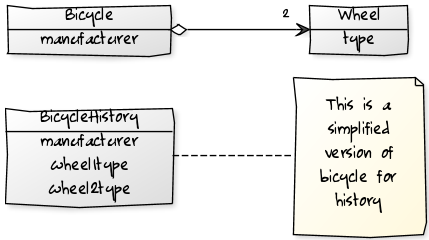
请注意,业务逻辑不打算以任何方式使用历史记录表。
安全要求
安全要求通常会在模型中带来冗余。 为了创建一个更安全,易于验证且健壮的模型,必须引入一定数量的数据,并且在大多数情况下,这对于其余模型是多余的。
对于建筑结构,应用结构冗余将提高模型的健壮性,因为任何引入的错误都可以轻松识别,并且可以减轻相关的风险。
再举一个例子,我将讨论模型的完整性验证。 让我们考虑与自动化过程关联的模型。 它由两部分组成:
- 输入数据
- 自动化过程结果
由于模型2包含通过在模型1实体上应用一系列算法生成的实体,因此它表示算法冗余 。
如何使任何变更对模型1的影响都可以在模型2中轻松识别和减轻?
这里有两种解决方案:
- 在数据库中实现修订控制系统 ,并在生成的实体之间实现可追溯性矩阵(将生成的实体的修订号映射到用作输入的实体上)
- 在模块2中实现一个冗余输入子层 ,其中包含来自模块1的所有数据,这些数据已被用作输入以在模块2中生成数据。此层可用于随时验证模块2是否仍与模块同步1。
两种解决方案都需要在模型中应用冗余,但是同样,我们这样做的原因比领域设计的任何抽象美原则更为重要。

单独的上下文
在某些情况下,必须对两个单独建模的域进行交互,但是它们已经开发并且由不同的开发团队维护,因此无法创建接口层。
在那种情况下,当另一个人需要来自域A的数据时,我们说是域B,更简单的解决方案可能是在B中创建一个重复的域,其中包含来自A的所有必要信息。
两个域之间的同步可以通过每天执行的导出-导入过程来完成。

结论
冗余只是域建模过程中可能引起的众多关注之一。 我确定我没有涵盖所有可能的情况,但是希望您能从中找到有用的内容。
翻译自: https://www.javacodegeeks.com/2014/02/redundancy-in-domain-and-database-design.html
数据库设计冗余















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









