





 本文探讨了CPU缓存刷新的常见误解,解释了CPU高速缓存的工作原理,特别是在多处理器系统中的内存层次结构和缓存一致性。文章指出,刷新缓存并非程序员在并发编程中确保可见性的正确方法,而是需要内存屏障来确保正确排序。
本文探讨了CPU缓存刷新的常见误解,解释了CPU高速缓存的工作原理,特别是在多处理器系统中的内存层次结构和缓存一致性。文章指出,刷新缓存并非程序员在并发编程中确保可见性的正确方法,而是需要内存屏障来确保正确排序。
cpu刷新缓存是什么意思
即使来自经验丰富的技术人员,我也经常听到有关某些操作如何导致CPU缓存“刷新”的话题。 这似乎说明了关于CPU缓存如何工作以及缓存子系统如何与执行核心交互的一个非常普遍的谬论。 在本文中,我将尝试解释CPU高速缓存实现的功能,以及执行我们的指令程序的内核如何与它们交互。 作为一个具体的例子,我将介绍一种最新的Intel x86服务器CPU。 其他CPU使用类似的技术来达到相同的目的。
执行我们程序的大多数现代系统在设计上都是共享内存的多处理器系统。 共享内存系统只有一个内存资源,可以由2个或更多独立的CPU内核访问。 主存储器的延迟很高
范围从10s到100s的纳秒。 在100ns内,一个3.0GHz CPU最多可以处理1200条指令。 每个Sandy Bridge内核能够并行退出每个周期最多4条指令(IPC)。 CPU使用高速缓存子系统来隐藏此延迟,并允许它们行使其巨大的能力来处理指令。 其中一些缓存很小,非常快,并且对于每个核心来说都是本地的。 其他一些则速度较慢,更大并且在内核之间共享。 这些缓存与寄存器和主存储器一起构成了我们的非持久性存储器层次结构。 下次您要开发一种重要的算法时,请尝试考虑高速缓存未命中是丢失执行500条CPU指令的机会! 这是针对单插槽系统的,在多插槽系统上,当内存请求跨插槽互连时,您可以有效地将损失的机会加倍。
记忆层级
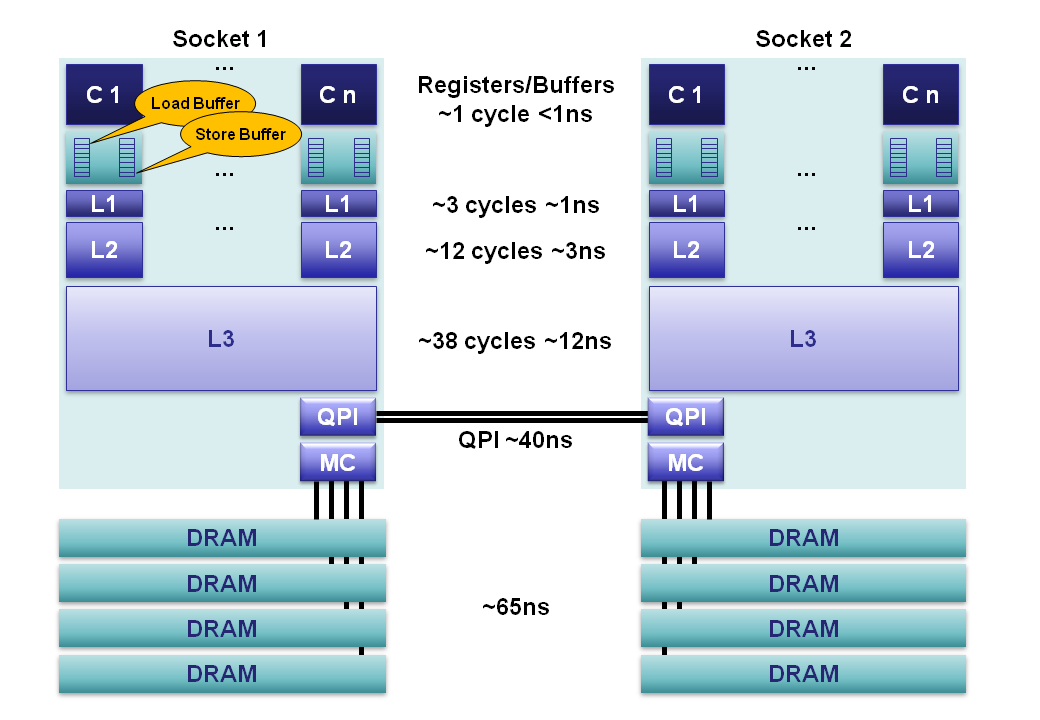
图1。
对于大约2012 Sandy Bridge E类服务器,我们的内存层次可以分解如下:
- 寄存器 :每个内核中都有单独的寄存器文件,其中包含160个整数条目和144个浮点数。 这些寄存器可在一个周期内访问,并且构成了我们执行内核可用的最快的内存。 编译器会将我们的局部变量和函数参数分配给这些寄存器。 启用超线程后 ,这些寄存器在同一位置的超线程之间共享。
- 内存排序缓冲区(MOB) :MOB由64项加载和36项存储缓冲区组成。 这些缓冲区用于在等待高速缓存子系统时跟踪运行中的操作。 存储缓冲区是一个完全关联的队列,可以搜索现有的存储操作,这些存储操作在等待L1高速缓存时已排队。 这些缓冲区使我们的快速处理器能够在高速缓存子系统之间来回传输数据时异步运行。 当处理器发出异步读写时,结果可能会乱序返回。 MOB用于消除负载和存储顺序的歧义,以符合发布的内存模型 。
- 一级缓存 :L1是一个核心本地缓存,分为单独的32K数据缓存和32K指令缓存。 访问时间为3个周期,并且可以隐藏,因为内核对L1高速缓存中已有的数据进行了指令流水线处理。
- 二级缓存 :L2缓存是一个核心本地缓存,旨在缓存L1和共享L3缓存之间的访问。 L2高速缓存的大小为256K,并充当L1和L3之间的有效存储器访问队列。 L2包含数据和指令。 L2访问延迟为12个周期。
- 3级高速缓存 :L3高速缓存在套接字内的所有内核之间共享。 L3分为2MB的段,每个段都连接到插槽上的环形总线网络。 每个内核也都连接到该环形总线。 地址被散列到段以提高吞吐量。 根据缓存大小,延迟最多可以达到38个周期。 取决于段的数量,缓存大小最多可为20MB,环上每增加一跳,将花费一个额外的周期。 L3高速缓存包含L1和L2中同一套接字上每个内核的所有数据。 这种包容性以空间为代价,允许L3缓存拦截请求,从而减轻了专用于本地内核的L1和L2缓存的负担。
- 主内存 :DRAM通道以平均〜65ns的平均延迟连接到每个插槽,以便在完全缓存未命中时进行插槽本地访问。 但是,这是非常可变的,对于后续访问同一行缓冲区中的列,此值要小得多,而在排队效果和内存刷新周期发生冲突时,则要多得多。 每个插槽上将4个内存通道聚合在一起以提高吞吐量,并通过独立内存通道上的流水线隐藏延迟。
- NUMA :在多路服务器中,我们具有不一致的内存访问 。 这是不统一的,因为所需的内存可能位于远程插槽上,该插槽在QPI总线上有一个额外的40ns跃点。 桑迪桥(Sandy Bridge)是Westmere和Nehalem上2座系统向前迈出的重要一步。 使用Sandy Bridge,QPI限制已从6.4GT / s提高到8.0GT / s,并且可以聚合两个通道,从而消除了先前系统的瓶颈。 对于Nehalem和Westmere,QPI链接只能提供大约40%的带宽,该带宽可以由内存控制器为单个插槽提供。 这种限制使访问远程存储器成为瓶颈。 此外,QPI链接现在可以转发前几代人不能提供的预取请求。
关联度
缓存实际上是基于硬件的哈希表。 哈希函数通常是一些低阶位的简单掩码,用于缓存索引。 哈希表需要一些方法来处理同一插槽的冲突。 关联性级别是可用于保存地址的哈希版本的插槽数,也称为方式或集合。 具有更多级别的关联性是在存储更多数据与功耗要求以及搜索每种方式的时间之间的权衡。 对于Sandy Bridge,L1D和L2是8路关联的,L3是12路关联的。
缓存一致性
由于某些高速缓存对于内核而言是本地的,因此我们需要一种使它们保持一致的方法,以便所有内核都可以拥有一致的内存视图。 高速缓存子系统被认为是主流系统的“真理之源”。 如果从高速缓存中获取内存,则永远不会过时。 当缓存和主内存中都存在数据时,缓存是主副本。 这种内存管理方式称为回写,其中仅当由于使用新行代替高速缓存行而将高速缓存行逐出时,才将高速缓存中的数据写回到主内存中。 x86高速缓存可处理大小为64字节的数据块,称为高速缓存行 。 其他处理器可以对高速缓存行使用不同的大小。 较大的高速缓存行大小会降低有效等待时间,但会增加带宽需求。 为了保持高速缓存的一致性,高速缓存控制器跟踪每个高速缓存行的状态为有限数量的状态之一。 英特尔采用这一协议是MESIF ,AMD采用了变型所知道的MOESI 。 根据MESIF协议,每个高速缓存行可以处于以下5种状态之一:
- 已修改 :指示高速缓存行是脏的,必须在以后将其写回到内存中。 当写回主存储器时,状态将转换为“排他”。
- 排他性 :指示高速缓存行是排他性保留的,并且与主内存匹配。 写入时,状态然后转换为“已修改”。 为了实现此状态,发送了所有权请求(RFO)消息,该消息涉及读取以及对所有其他副本的无效广播。
- 共享 :表示与主内存匹配的缓存行的干净副本。
- 无效 :表示未使用的缓存行。
- 转发 :表示共享状态的专用版本,即这是指定的缓存,应响应NUMA系统中的其他缓存。
为了从一种状态转换到另一种状态,在高速缓存之间发送了一系列消息以实现状态更改。 在Intel的Nehalem和AMD的Opteron之前,套接字之间的缓存一致性流量必须共享内存总线,这极大地限制了可扩展性。 这些天来,内存控制器流量位于单独的总线上。 英特尔QPI和AMD HyperTransport总线用于套接字之间的缓存一致性。 高速缓存控制器作为模块存在于每个L3高速缓存段中,每个L3高速缓存段都连接到插槽上的环形总线网络。 每个内核,L3缓存段,QPI控制器,内存控制器和集成的图形子系统都连接到此环形总线。 环由4个独立的通道组成,用于:每个周期的request , snoop , Confirm和32字节数据 。 L3高速缓存是包含性的,因为L1或L2高速缓存中保留的任何高速缓存行也都保留在L3中。 在侦听更改时,可以快速识别包含已修改行的核心。 L3段的高速缓存控制器跟踪哪个内核可能拥有其拥有的高速缓存行的修改版本。 如果核心想要读取一些内存,并且它没有处于共享,互斥或已修改状态; 那么它必须在环形总线上进行读取。 然后,如果不在高速缓存子系统中,则将从主内存中读取它;如果是干净的,则将从L3中读取;如果已修改,则从另一个内核中窥探它。 在任何情况下,读取都永远不会从缓存子系统返回陈旧的副本,因此保证了其一致性。
并发编程
如果我们的缓存始终保持一致,那么为什么我们在编写并发程序时担心可见性? 这是因为在我们的核心中,为了寻求更高的性能,数据修改可能对其他线程而言是乱序的。 有两个主要原因。
首先,出于性能方面的考虑,我们的编译器可以生成将变量存储在寄存器中较长时间的程序,例如,循环中重复使用的变量。 如果我们需要这些变量在内核之间可见,则不得对更新进行寄存器分配。 这是通过在C中将变量定为“易失性”来实现的。 注意,C / C ++ volatile不足以告诉编译器不要对其他指令重新排序。 为此,您需要内存围栏/屏障。
我们必须要注意的第二个主要问题是线程可以写一个变量,然后,如果它在不久之后读取它,则可以看到其存储缓冲区中的值可能早于缓存子目录中的最新值,系统。 对于遵循单一作者原则的算法而言,这绝不是问题,而对于Dekker和Peterson锁算法之类的算法而言,这决不是问题。 若要解决此问题,并确保观察到最新值,线程不得在本地存储缓冲区中加载该值。 这可以通过发出篱笆指令来实现,该篱笆指令可防止后续的负载从另一个线程超前于存储。 用Java写volatile变量,除了从不分配寄存器外,还附带完整的fence指令。 在x86上的该fence指令通过阻止发布线程直到存储缓冲区被耗尽之前的进度而对性能产生重大影响。 其他处理器上的栅栏可以具有更有效的实现方式,只需将标记放在存储缓冲区中即可进行搜索边界,例如Azul Vega就是这样做的。
如果要确保遵循单一编写器原则时跨Java线程的内存排序并避免存储隔离,可以通过使用jucAtomic(Int | Long | Reference).lazySet()方法来实现,而不是设置volatile变量。
谬论
作为并发算法的一部分,回到“刷新缓存”的谬论。 我想可以肯定地说,我们永远不会“刷新”用户空间程序中的CPU缓存。 我认为这种谬误的根源是需要刷新,标记或耗尽某些类型的并发算法的存储缓冲区,以便可以在后续加载操作中观察到最新值。 为此,我们需要一个内存排序屏障,而不是缓存刷新。 这种谬论的另一个可能来源是可能需要根据上下文切换上的地址索引策略来刷新L1缓存或TLB 。 ARMv6之前的ARM不在TLB条目上使用地址空间标记,因此要求在上下文切换器上刷新整个L1缓存。 许多处理器出于类似的原因要求刷新L1指令高速缓存,在许多情况下,这仅仅是因为不需要使指令高速缓存保持一致。 最重要的是,上下文切换是昂贵的,而且话题不多,因此,除了L2的缓存污染外,上下文切换还会导致TLB和/或L1缓存需要刷新。 英特尔x86处理器仅需要上下文切换上的TLB刷新即可。
参考: Mechanical Sympathy博客上的JCG合作伙伴 Martin Thompson提供的CPU缓存刷新谬论 。
翻译自: https://www.javacodegeeks.com/2013/02/cpu-cache-flushing-fallacy.html
cpu刷新缓存是什么意思















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









