







情况说明
相同的数据集用yolov3tiny跑了一遍,结果还好,想换成yolov3看看效果会不会有提升。(均匀GPU加速)
Using cuda _CudaDeviceProperties(name='GeForce RTX 2060', major=7, minor=5, total_memory=6144MB, multi_processor_count=30)
yolov3tiny的各参数如下
train.py
epochs=10,
batch_size=16,
accumulate=1,
yolov3-tiny.cfg
batch=1
subdivisions=1
width=416
height=416其他所有参数都是原来的模型里的参数。
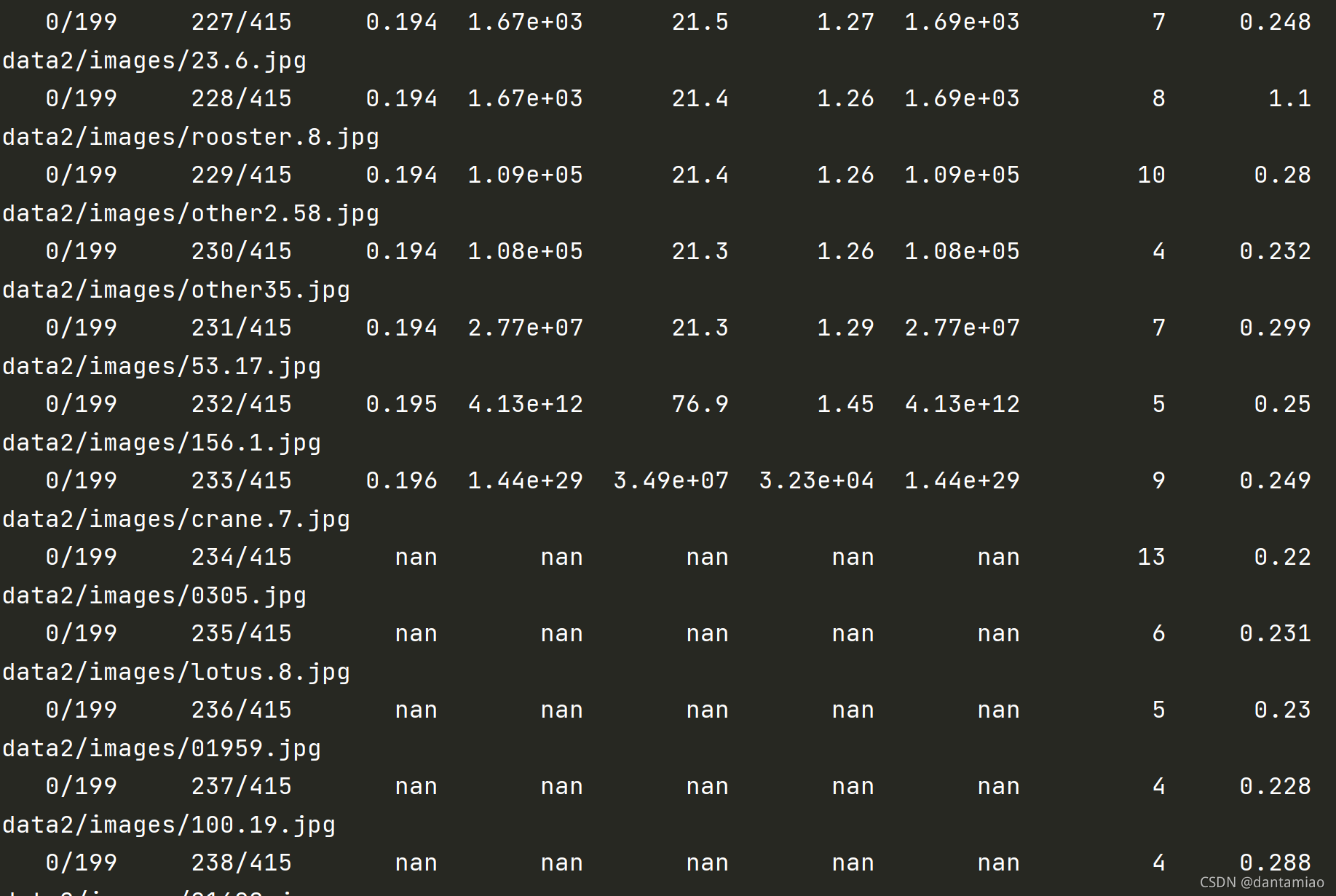
用同样的参数跑YOLOv3模型(GPU暂时还扛得住,在这个batch下)

然后就nan了,第227次,开始爆炸,然后nan
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









