









视频源自
作为一个设计学出身企图踏足人工智能领域的小白,听说这门课很OK于是来听课了。希望给非科班出身的同学们一些帮助。
版权声明:本文中所有出现的图片均为视频截图,课件内容版权所有人应为斯坦福学校或课程授课人。本博客中的图片应仅用于学习,请勿用于商业用途,请勿侵犯创作者知识产权。
以下是Lecture2 image classification的笔记
Nearest neighbor classifier
在本次课程中将会使用python3和numpy, 课程附上了简单的入门教学,地址如下:
http://cs231n.github.io/python-numpy-tutorial/
曼哈顿距离-Manhuttan distance L1
 (30条消息) 机器学习中的数学——距离定义(二):曼哈顿距离(Manhattan Distance)_von Neumann的博客-CSDN博客_机器学习曼哈顿距离
(30条消息) 机器学习中的数学——距离定义(二):曼哈顿距离(Manhattan Distance)_von Neumann的博客-CSDN博客_机器学习曼哈顿距离![]() https://blog.csdn.net/hy592070616/article/details/121569933?spm=1001.2014.3001.5501这篇文章介绍的非常详细,除了曼哈顿距离还有常用的欧几里得和余弦距离。
https://blog.csdn.net/hy592070616/article/details/121569933?spm=1001.2014.3001.5501这篇文章介绍的非常详细,除了曼哈顿距离还有常用的欧几里得和余弦距离。
总体来说就是两个图像每个块的值相减,再加在一起,456就是两个图像的差了。
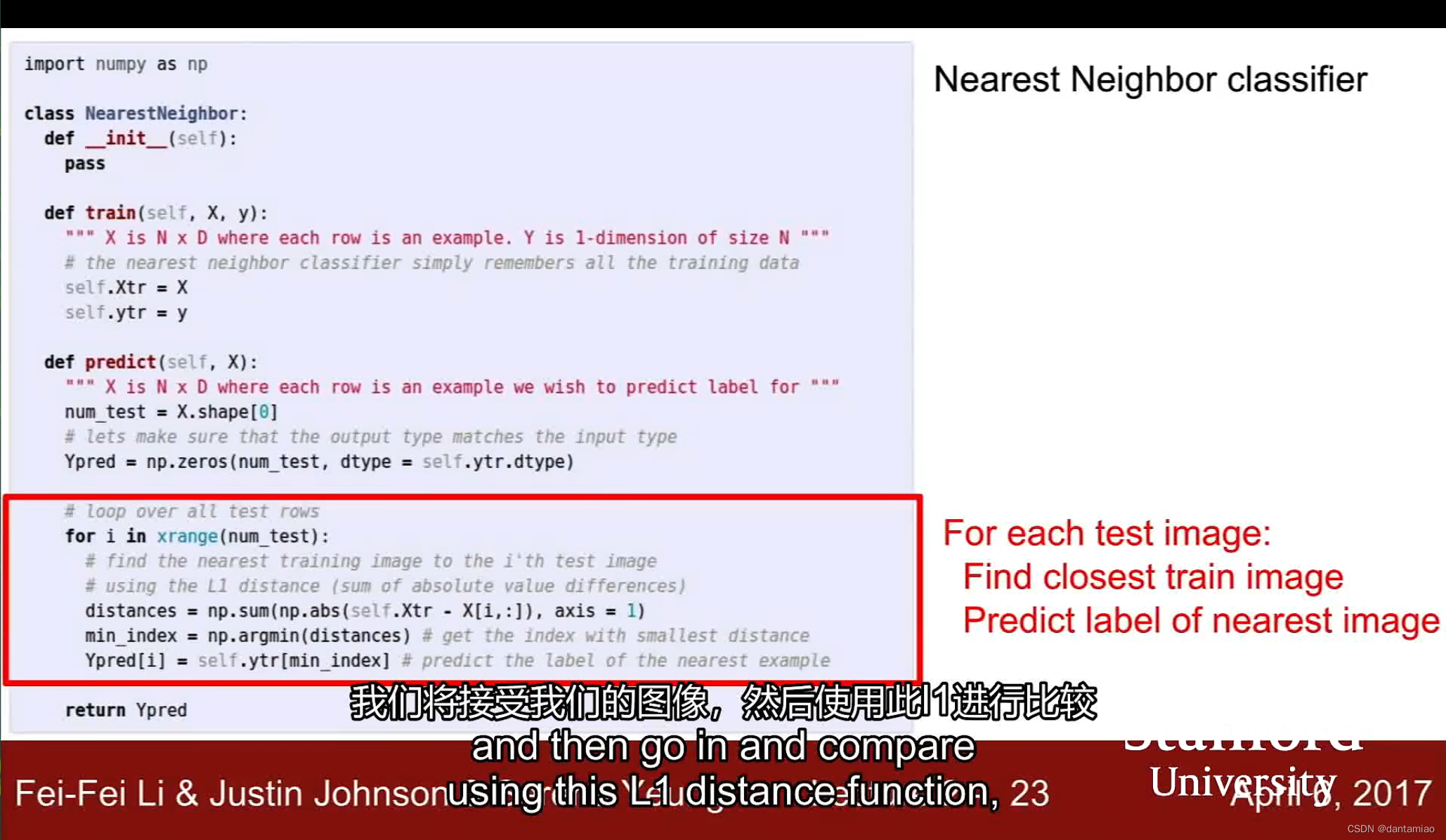

nearest neighbor clssifier的问题就在于,测试所用计算时间太长。而卷积神经网络训练时间长,但是测试非常快。
K-Nearest neighbors

K越大边界越平滑,大部分情况我们使用大于1的K值。白色区域中没有预测值。
可以看出来K越大,虽然他们可能忽略一些点的识别(某些点不在区域内),但是K越大,在空白区域的预测能力就越好。
欧几里得距离-Euclidean distance L2

图片相似性计算中用欧几里得的也比较多。那如何选择不同的方法?
视频原话:
If your input features, if the individual entries in your vector have some important meaning for you ask, then maybe somehow L1 might be a more natural fit. But if it's just a generic vector in some space and you don't know which of the different elements, you don't know what they actually mean, then maybe L2 is slightly more natural.
如果您的输入特征,如果您的向量中的各个条目对您有重要意义,那么也许 L1 可能更自然。 但是如果它只是某个空间中的一个通用向量并且你不知道哪些不同的元素,你不知道它们的实际含义,那么 L2 可能会稍微自然一些。

由于L1更加受到坐标的影响,所以能看到左边的图更多的横平竖直,右侧的则不在乎这一点。(个人理解如有错误请指正。)
老师做了一个测试demo可以用来玩: http://vision.stanford.edu/teaching/cs231n-demos/knn/
L1一定比L2好么?
老师举了一个例子:
老师认为,这常常取决于你的数据本身和你要分析的内容。如果你要对员工进行分类,不同的向量有不同的含义,他们被用薪水,能力等不同类的内容进行打分。由于向量方向是有意义的,在此类情况中L1可能更有意义(因为L1坐标系的建立是根据数据建立的)。最好的解决方案就是,都试,看哪个好。
Hyperparameters
就是我们设定好的value,距离,K值。这不是从数据里学到的,是我们认为设定的内容。
所以,这会变成非常 problem-dependent的问题。
通常情况在只在validation上边调试你的参数,test一般在实验的最后进行,而且只测试一次。
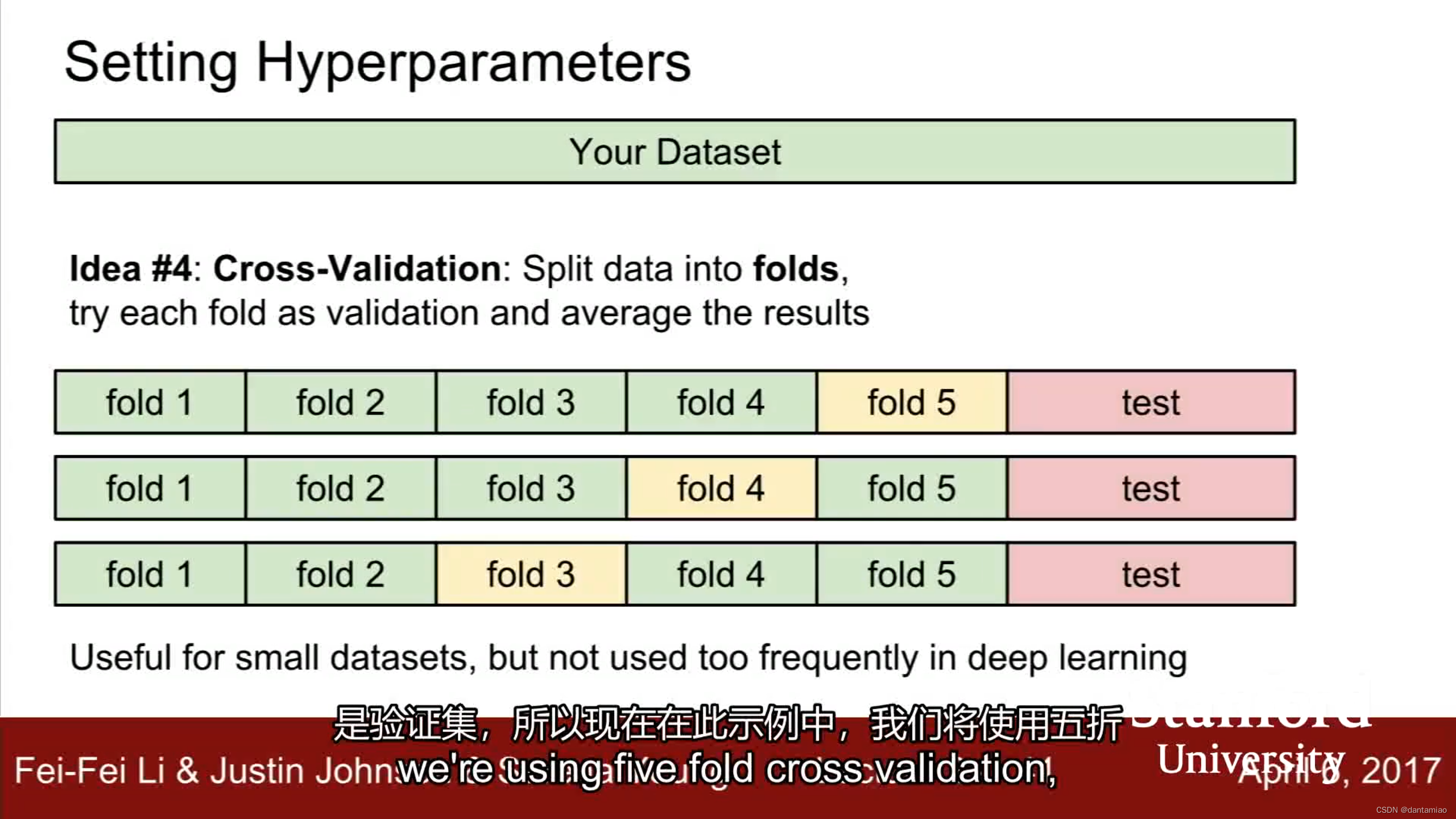
可以将数据集分成几个不同的组,设定不同的验证数据集,组合进行训练,寻找hyperparameters.
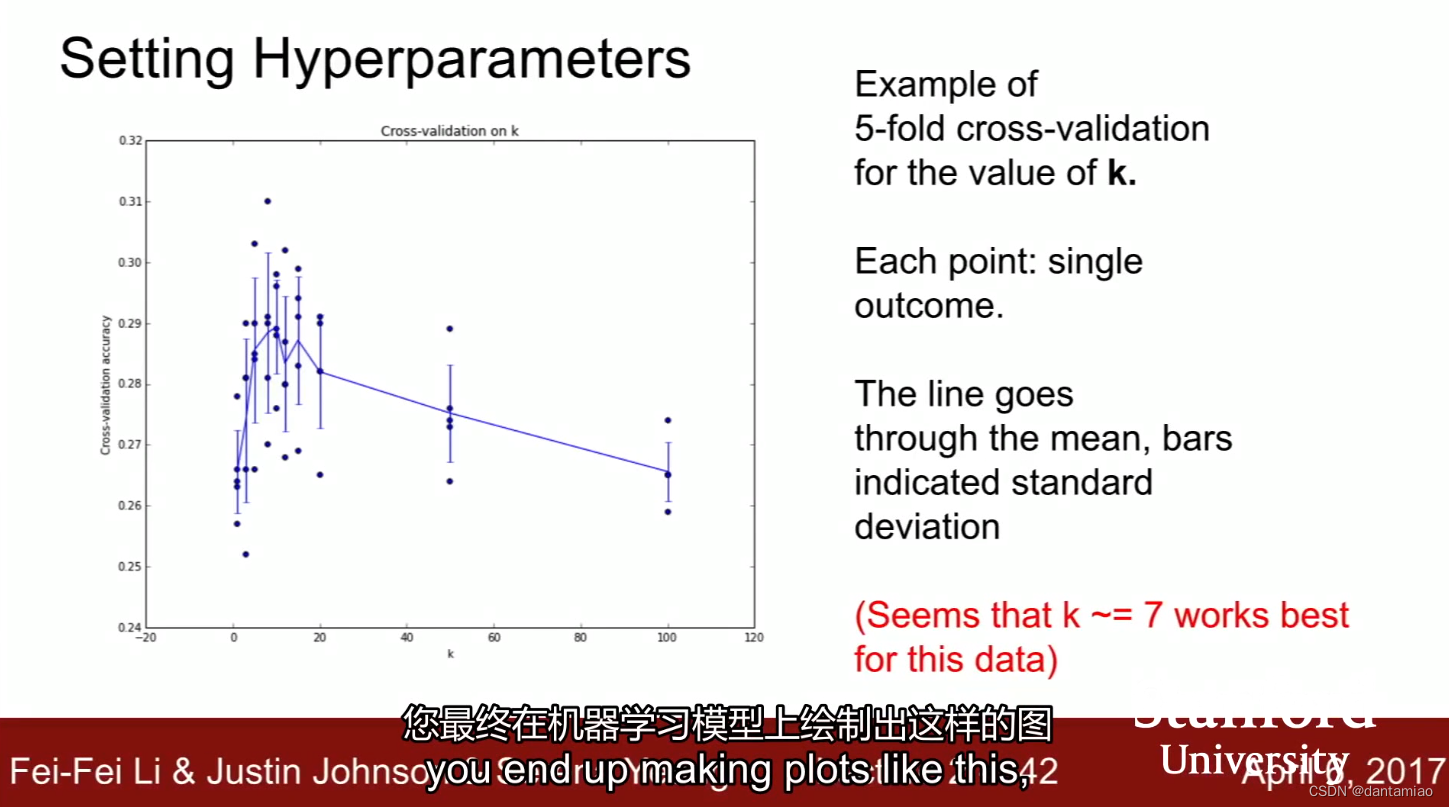
这是经过了5次交叉验证的最后图像,可以看出来K=7左右的数据是最好的。


Linear Classification
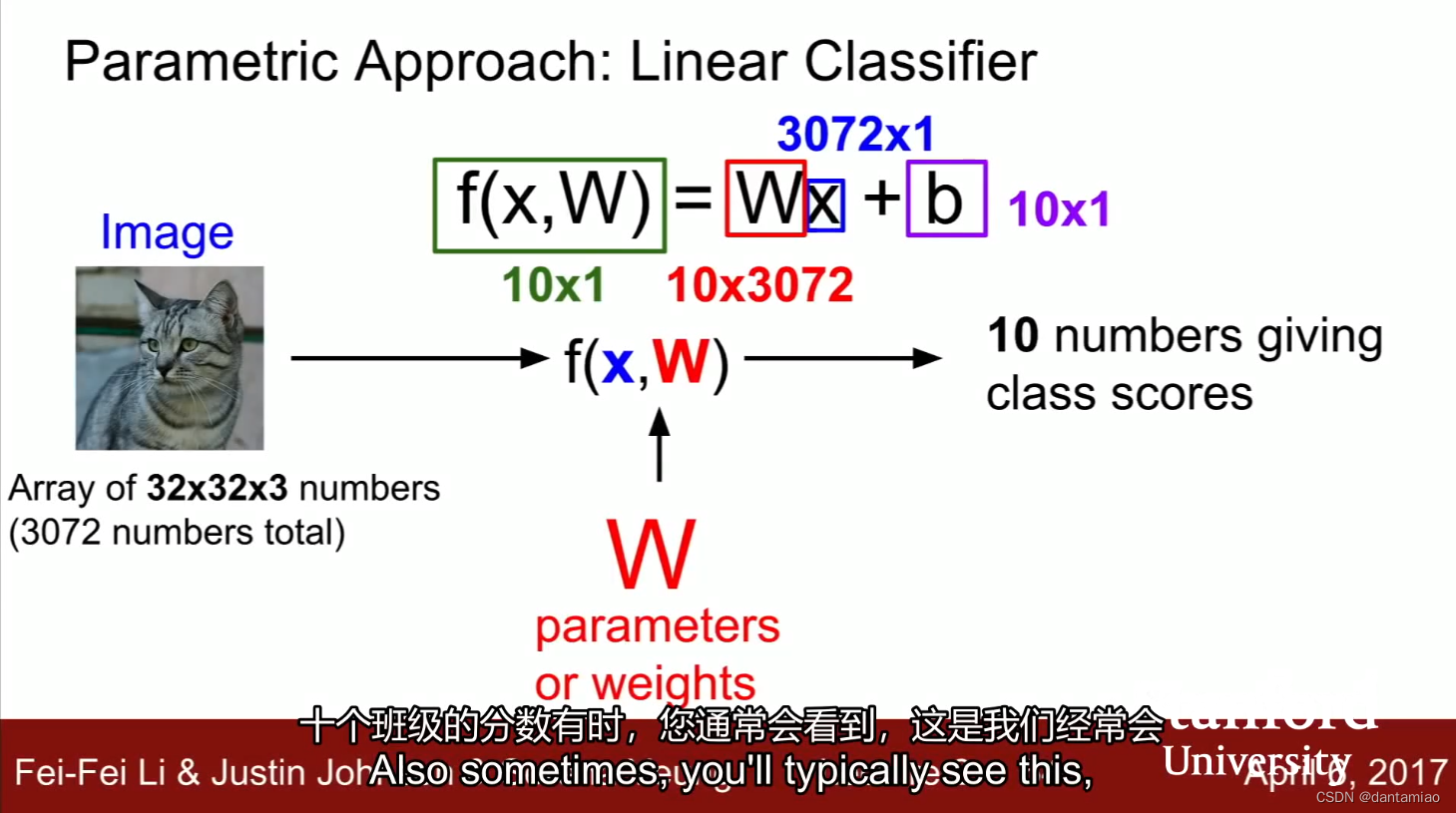
如果数据集中某些类别的图像更多,则b可以被用来调节这个差异。




马的情况可能类似第三种,每一个模型孤立,难以连接。线性不太适用于这种,但是线性是很简单和易于使用的模型。
















 4579
4579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









