







维护的系统中有一个统计功能特别慢,需要计算十几分钟,今天分析后发现有一个sql语句执行了近4秒,特意针对SQL进行了优化,记下优化记录。
主要分为两步:
1.优化sql语句
2.建索引
大的sql语句就不贴了,找出其中最慢的一段
select
a1.pid,a1.kfqnum ,a1.kfqdj,qsj,jsj,case when (jsj-qsj)/qsj > 1 then 100 ELSE (jsj-qsj)/qsj*100 end as jzssj
from
(
select aa.* from zd_kfq aa,(select * from zd_kfq where Kfqnum = 21) bb WHERE aa.Kfqdj = bb.kfqdj and aa.hg=bb.hg
) zz LEFT JOIN
(
select a.pid pid, kfqnum ,kfqdj,a.sz qsj
from evaluation_index a
where 1=1
and a.pid in(
select growth_id from evaluation_sub WHERE pid = 'ae80c82c-4172-46f4-895f-29e1e9e7fd3c'
)
and a.nian=2018-1
and a.kfqdj=1
) a1 on zz.Kfqnum = a1.kfqnum LEFT JOIN (
select a.pid pid, kfqnum ,kfqdj,a.sz jsj
from evaluation_index a
where 1=1
and a.pid in(
select growth_id from evaluation_sub WHERE pid = 'ae80c82c-4172-46f4-895f-29e1e9e7fd3c'
)
and a.nian=2018
and a.kfqdj=1
) b1 on a1.pid=b1.pid and a1.kfqnum=b1.kfqnum and a1.kfqdj = b1.kfqdj查询结果如下图,可以看到查询时间是3.5秒左右:
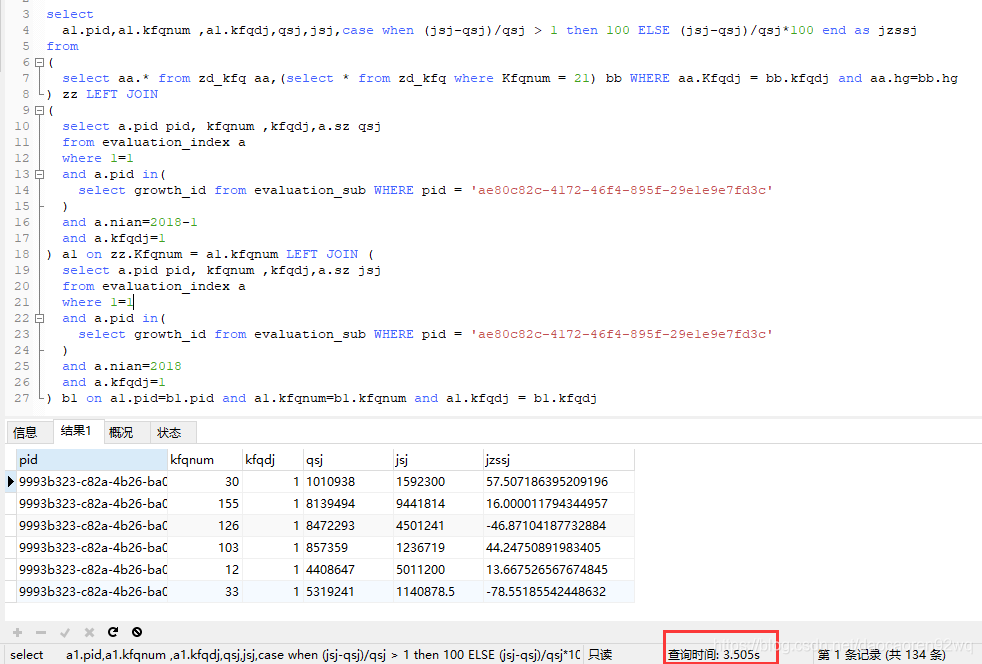
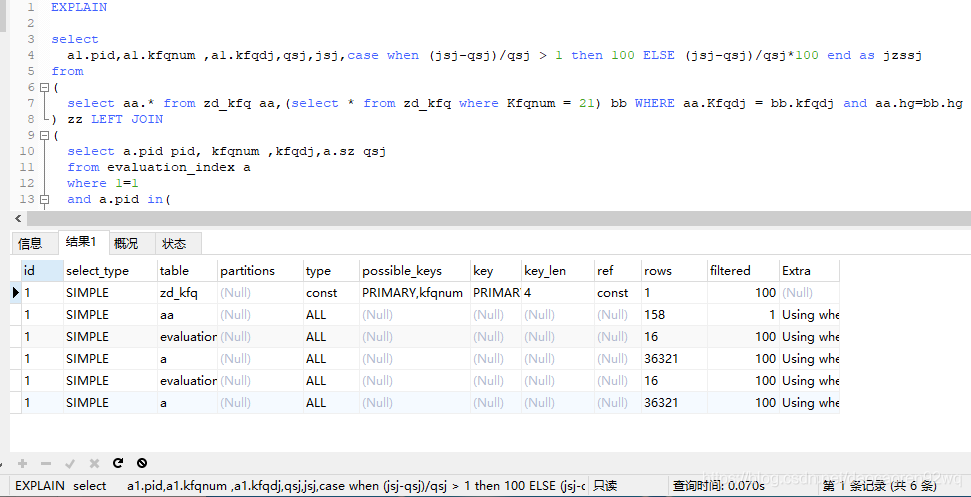
通过explain命令查看一下执行过程:
首先去掉语句嵌套,并且将left join替换为join
select this.pid,kfq.kfqnum,kfq.kfqdj,this.sz jsj,last.sz qsj ,case when (this.sz-last.sz)/last.sz > 1 then 100 ELSE (this.sz-last.sz)/last.sz*100 end as jzssj
from zd_kfq target
join zd_kfq kfq ON kfq.Kfqdj = target.kfqdj and kfq.hg=target.hg
join evaluation_index this ON kfq.kfqnum = this.kfqnum -- and kfq.kfqdj = this.kfqdj
join evaluation_sub sub ON this.pid = sub.growth_id
join evaluation_index last on last.pid = sub.growth_id and this.pid=last.pid and kfq.kfqnum=last.kfqnum -- and kfq.kfqdj = last.kfqdj
where target.kfqnum = 21
AND this.nian = 2018 AND this.kfqdj = target.kfqdj
AND last.nian = 2018-1 AND last.kfqdj = target.kfqdj
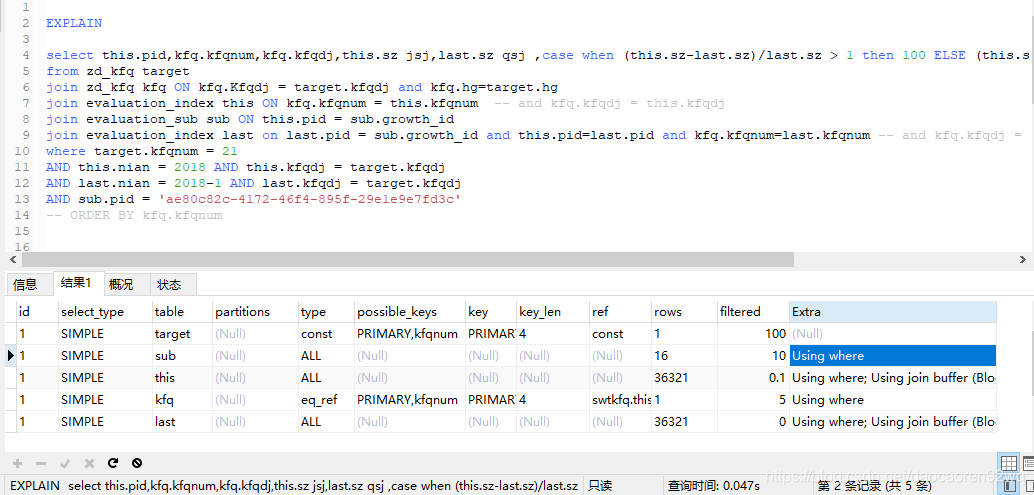
AND sub.pid = 'ae80c82c-4172-46f4-895f-29e1e9e7fd3c'执行时间缩短为0.36秒左右,快了10倍 ,结果少了几条值为null的

再通过explain命令查看一下执行过程:
针对上面表中this/last,也就是evaluation_index表创建索引,这个在查询中扫描了36321行
CREATE INDEX stat_kfq ON evaluation_index (pid,nian,kfqnum,kfqdj) USING BTREE;
执行时间缩短为0.05秒左右
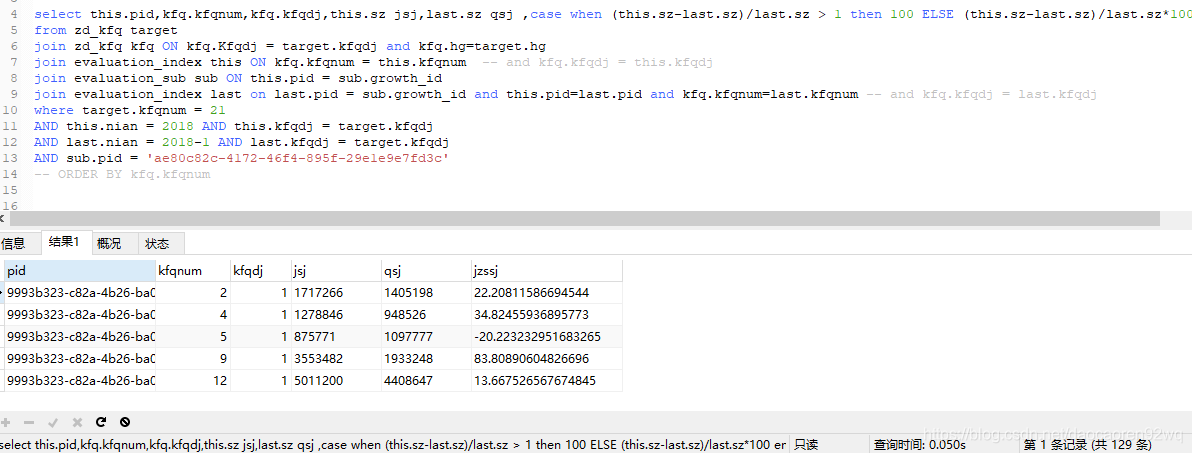
查看执行过程
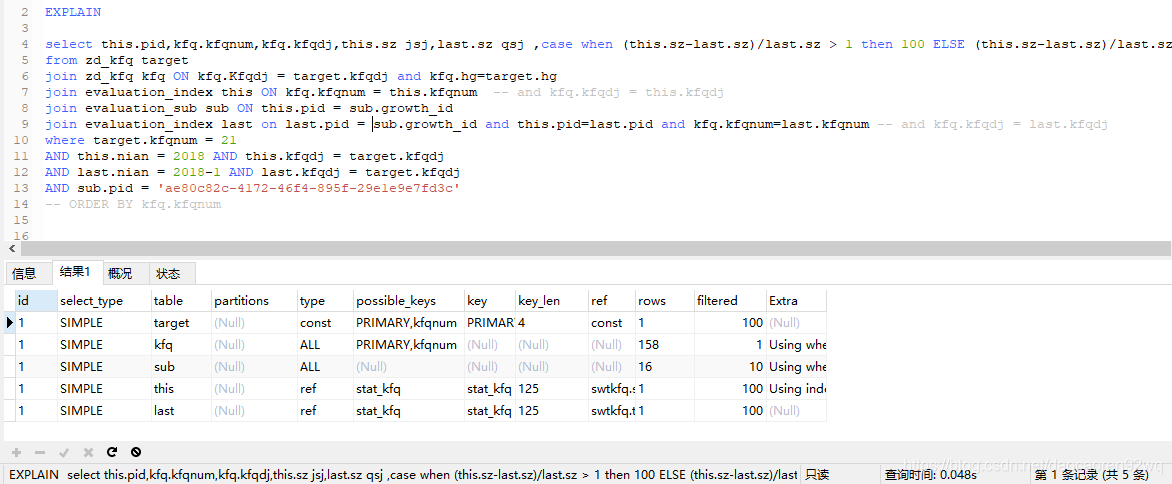
可以看到现在除了kfq和sub两个表都已经使用了索引,这两个表数据量比较少,加上索引基本没什么影响
总结
1.先优化sql语句
在保证结果正确的前提下减少使用left join和嵌套查询,能够减少sql执行步骤数量
2.创建索引
针对数据量比较大的表建立联合索引,建立索引遵循最左前缀匹配原则
(1)比如针对一个表A、B、C三个字段建立联合索引,当查询条件为A、AB、ABC、AC都可以使用到索引
(2)如果这个表字段包含除了ABC之外的其他字段D,并且D上面没有被其他索引覆盖,那么查询条件为B、或者C的时候就不会使用索引,explain语句的时候type=all
(3)如果这个表字段只有ABC三个字段,或者还包含是主键的D,则查询条件为B或者C时,也会使用到索引,explain语句的时候type=index
不同type的性能: null > system/const > eq_ref > ref > ref_or_null >index_merge > range > index > all
参考:
https://www.cnblogs.com/wangfengming/articles/8275448.html
https://www.jb51.net/article/142840.htm














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









