







-----日常记录一个解决自己在开发中遇到的sql统计查询慢的问题
- 建立字段索引
- 对数据冗多的副表,进行关联关系片区化(先对附表进行数据筛选再关联主表)
- 优化查询条件
1、字段索引的好处就不说了,各位都应该懂,但索引也不能乱建,乱建sql执行会更慢。
2、关联关系片区化(不是专业术语,个人理解)
-
关联的附表之间存在关联关系,且与主表存在冗余数据关联时,先在副表之间进行关联,筛选。再与主表进行关联,可减少不必要的数据关联动作
-
前景:
现有三个表,积分流水表A,粉丝表B,会员表C。粉丝有积分,会员对应多渠道粉丝。现要获取会员的积分统计情况(全部),流水表:60w,粉丝100w,会员6w -
常见写法
SELECT
-- sum函数统计
SUM( lw.consumeScore ) expendScore,
SUM( lw.grantScore ) collectScore,
SUM( lw.grantScore ) - SUM( lw.consumeScore ) availableScore,
lw.created_at countDate
FROM
(
SELECT
CASE msf.score_type WHEN 1 THEN msf.score ELSE 0 END AS grantScore,
CASE msf.score_type WHEN 2 THEN msf.score ELSE 0 END AS consumeScore,
FROM_UNIXTIME( msf.created_at, '%Y-%m-%d' ) created_at
FROM
ms_score_flow msf
-- 关联粉丝,会员表
LEFT JOIN ms_fans mf ON mf.fans_uuid = msf.uuid
LEFT JOIN ms_member_info mmi ON mmi.uuid = mf.uuid
WHERE
-- 筛选掉没有会员的数据
mmi.uuid IS NOT NULL
) lw
GROUP BY lw.created_at
-
以上sql执行时间为3.640s -
优化sql :将粉丝,会员表先进行关联筛选,再与积分表进行关联
SELECT
SUM( lw.consumeScore ) expendScore,
SUM( lw.grantScore ) collectScore,
SUM( lw.grantScore ) - SUM( lw.consumeScore ) availableScore,
lw.created_at countDate
FROM
(
SELECT
CASE mf.score_type WHEN 1 THEN mf.score ELSE 0 END AS grantScore,
CASE mf.score_type WHEN 2 THEN mf.score ELSE 0 END AS consumeScore,
FROM_UNIXTIME( mf.created_at, '%Y-%m-%d' ) created_at
FROM
ms_score_flow mf
LEFT JOIN (-- 以粉丝表为主表,查询出有会员的粉丝
SELECT
mf.fans_uuid,
mmi.uuid
FROM
ms_fans mf
LEFT JOIN ms_member_info mmi ON mf.uuid = mmi.uuid
WHERE
-- 剔除没有会员的粉丝
mf.uuid IS NOT NULL
) mmi ON mmi.fans_uuid = mf.uuid
-- 剔除没有会员的积分数据
WHERE mmi.uuid IS NOT NULL
) lw
GROUP BY lw.created_at
-
以上sql执行时间为0.908s
分析一下为什么提出粉丝,会员进行筛选后,再关联主表,执行效率会快这么多
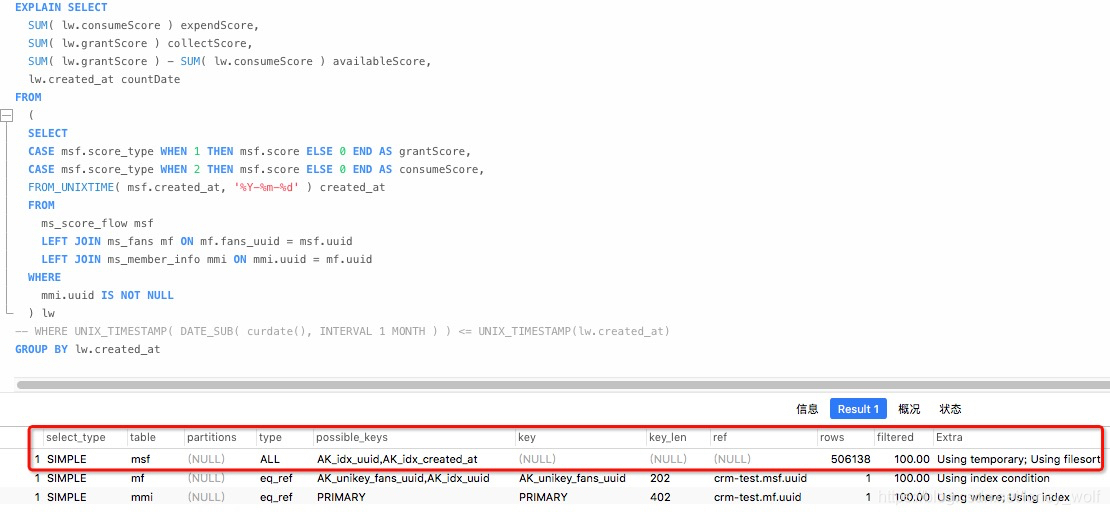
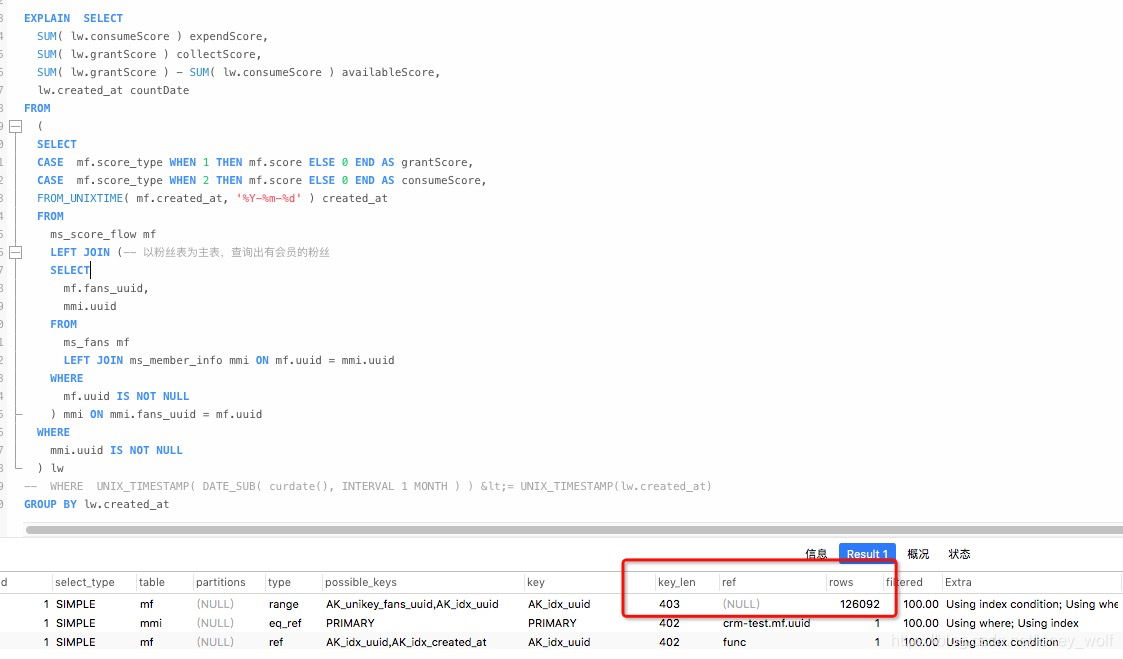
-
在没有提出粉丝,会员表的sql中扫有五十多万行,以积分表为主表对粉丝,会员进行关联 -
而提出粉丝,会员进行筛选后的sql,仅12万行,减少了几十万次不必要的关联动作。
3、where查询条件优化
- != , <>等操作符会影响mysql对索引的引用,这些就不说了
- where 业务筛选条件,在sql中的筛选位置也很影响效率
SELECT
SUM( lw.consumeScore ) expendScore,
SUM( lw.grantScore ) collectScore,
SUM( lw.grantScore ) - SUM( lw.consumeScore ) availableScore,
lw.created_at countDate
FROM
(
SELECT
CASE mf.score_type WHEN 1 THEN mf.score ELSE 0 END AS grantScore,
CASE mf.score_type WHEN 2 THEN mf.score ELSE 0 END AS consumeScore,
FROM_UNIXTIME( mf.created_at, '%Y-%m-%d' ) created_at
FROM
ms_score_flow mf
LEFT JOIN (-- 以粉丝表为主表,查询出有会员的粉丝
SELECT
mf.fans_uuid,
mmi.uuid
FROM
ms_fans mf
LEFT JOIN ms_member_info mmi ON mf.uuid = mmi.uuid
WHERE
mf.uuid IS NOT NULL
) mmi ON mmi.fans_uuid = mf.uuid
WHERE
mmi.uuid IS NOT NULL
-- ------------------------------------业务筛选条件位置1
AND UNIX_TIMESTAMP( DATE_SUB( curdate(), INTERVAL 1 MONTH ) ) <= mf.created_at
) lw
-- ---------------------------------------业务筛选条件位置2
-- WHERE UNIX_TIMESTAMP( DATE_SUB( curdate(), INTERVAL 1 MONTH ) ) <= UNIX_TIMESTAMP(lw.created_at)
GROUP BY lw.created_at
位置一sql查询时间为3s多
位置二sql查询时间为0.9s
使用EXPLAIN分析,
位置一业务筛选条件在进行筛选的时候,进行了五十多万次筛选
位置二业务筛选条件在进行筛选的时候,进行了十二万次筛选
位置二筛选时,是在mmi.uuid IS NOT NULL 筛选完毕的基础上进行筛选的,而位置一与NOT NULL 条件同时进行
以上是开发中遇到的sql执行慢的问题,以及解决思路,不足还请指出















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









