






1.在Postgresql里面事务以begin开始,以end结束。执行begin命令,则开启一个事务,之后的操作都属于该事务的操作,直到执行end时结束。一个连接会话只能开启一个事务,重复使用begin,则会报错。

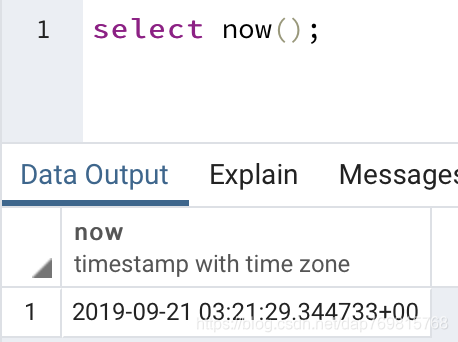

一旦开启事务后,now这个函数不管执行多少次,它返回的时间都是固定的,这是因为它返回的时间是当前事务的开启时间。另外current_time,current_timestamp也是如此,而clock_timestamp则返回的是当前的真实时间:
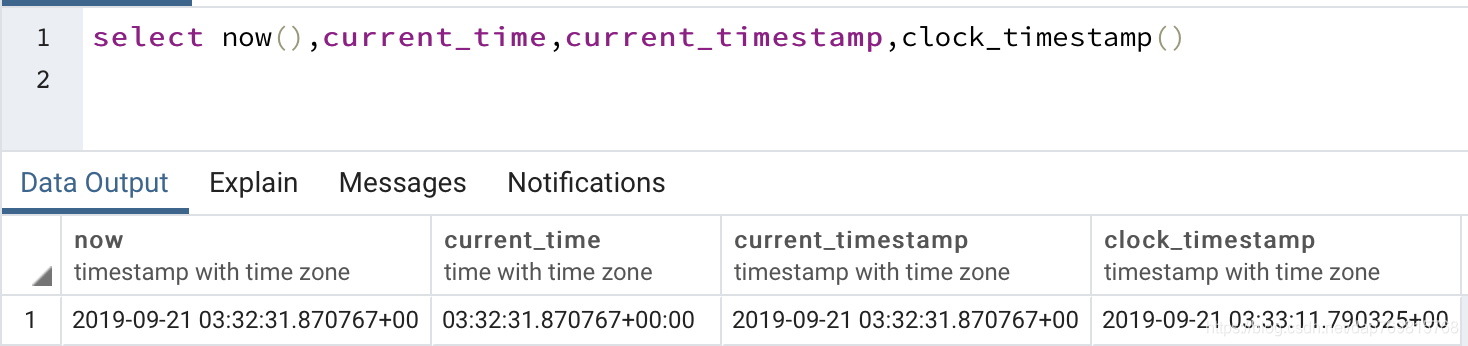
2.回滚、保存点。看下面的一连串操作,这里我没有使用pgadmin4操作,而是使用pg自带的客户端进行的操作:
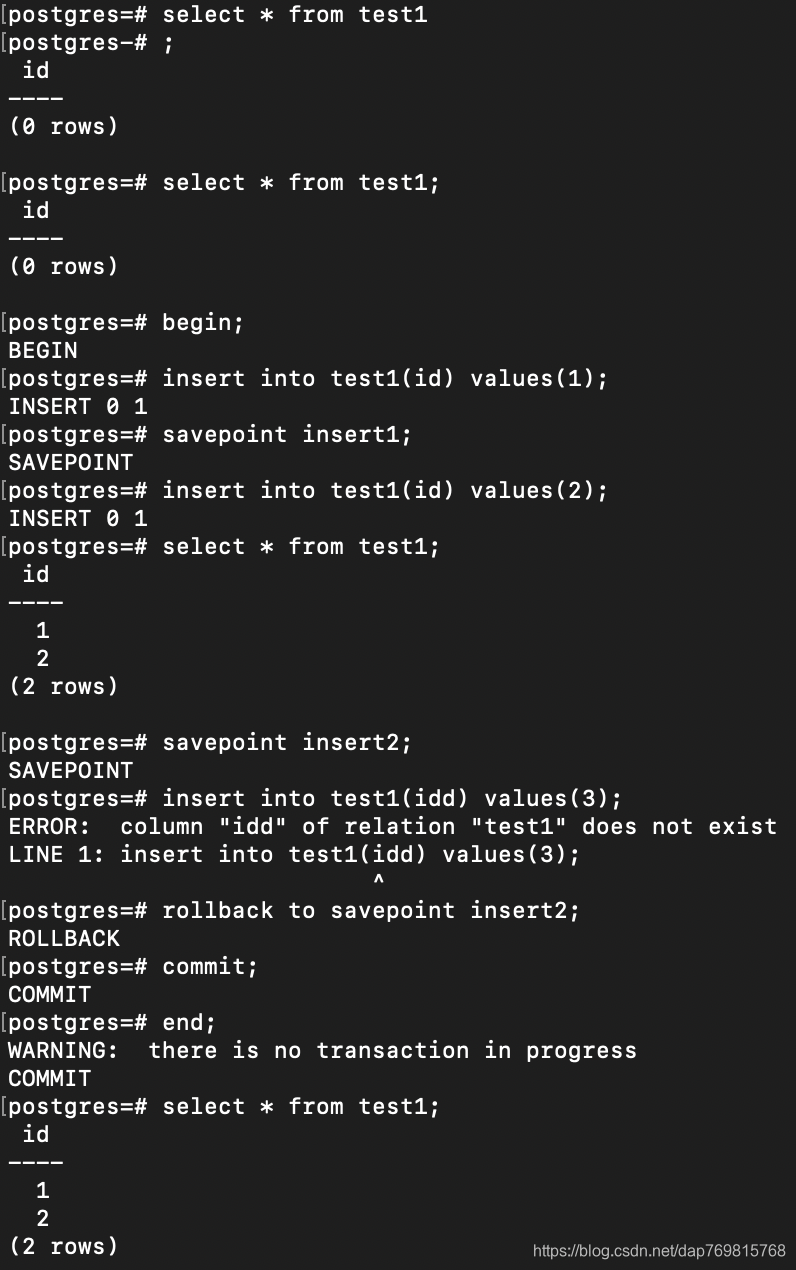
首先savepoint只能使用在事务中,上面的如果不进行rollback操作,那么使用commit命令,将是回滚操作,也就是1和2最终不会出现在数据库中。commit过后,就不需要end了,不使用commit也可以使用end结束事务。
这里推荐一个清屏命令:\! clear
3.隔离级别、不可重复读。
看下面的操作,我开两个客户端,一个进行事务操作,一个在事务操作期间插入一条数据:
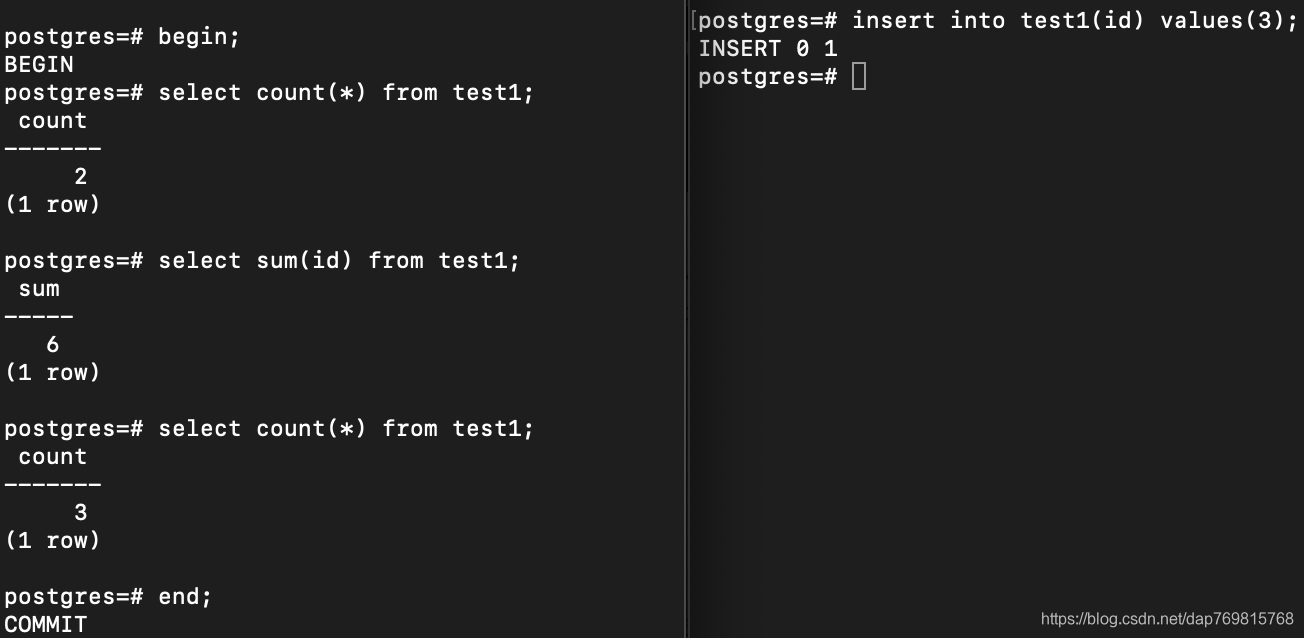
你会发现第一个的事务操作期间,两次读取的数据结果不一致,原因是另外一个线程在期间修改了数据。这就是不可重复读。
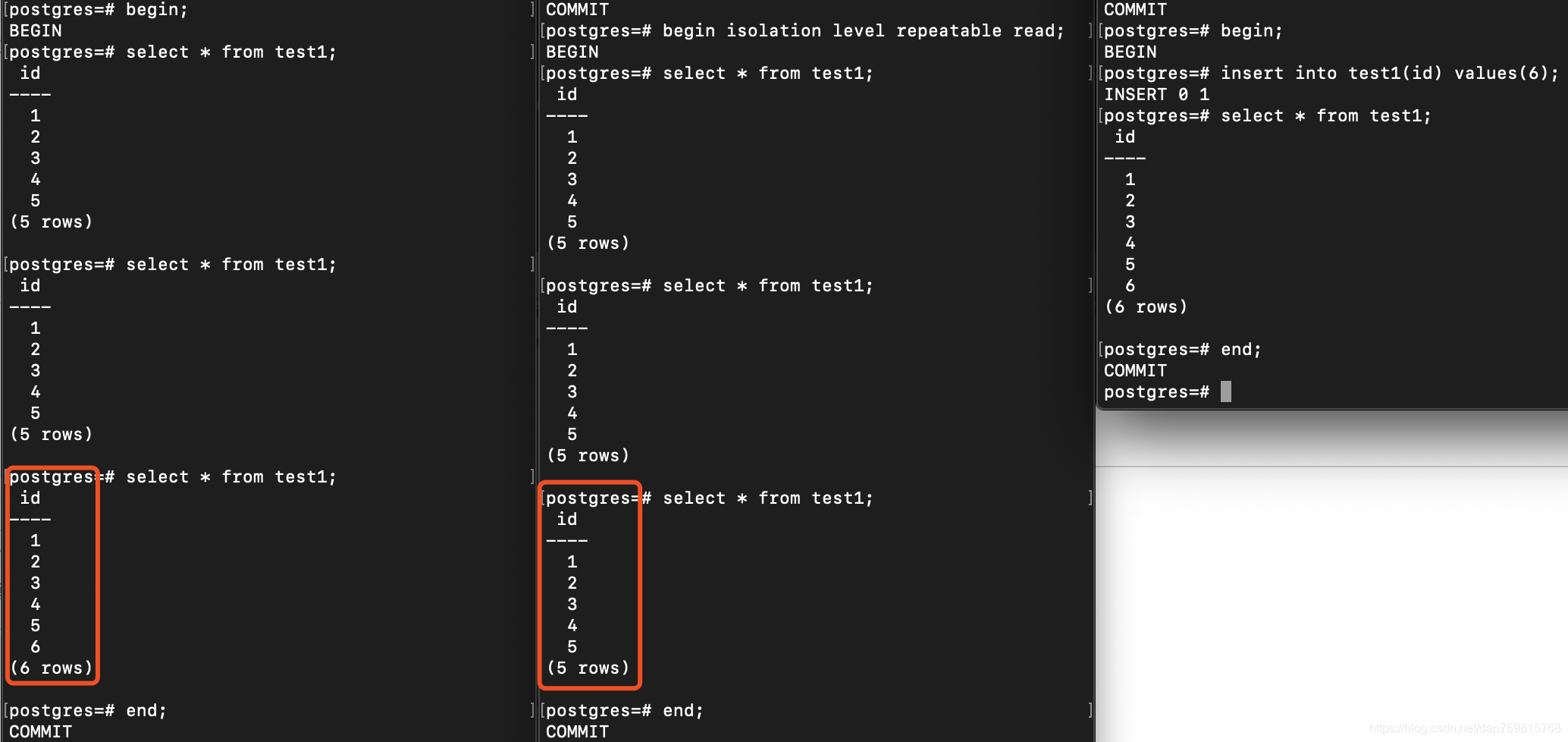
开启三个客户端,一个开启默认隔离级别的事务,一个开启可重复读级别的事务,一个开启事务进行数据插入操作。你会发现,开启了可重复读隔离级别的事务,在修改数据事务提交后,读取到的数据并未受影响,而使用默认隔离级别,则会受影响。开启可重复读隔离级别的事务,命令为:begin isolation level repeatable read;当开启了可重复读,那么数据库会在第一次查询的时候保存当前数据库的一张快照(注意,这张快照是数据库的快照,不是某个表的,所以如果其他表的数据被修改,你仍然读不到最新的数据),后面所有的查询都是是从这个快照里面读取数据,不管这期间有没有其他的线程对数据进行了修改。
看下面的情况,在第二个回话插入数据之前,第一个事务并没有做任何操作,所以就不会保存快照,那么第二个回话的数据修改操作,依然会影响第一个回话的事务:

那么如何查看事务的隔离级别呢,主要用到两个命令:
a)select name,setting from pg_settings where name='default_transaction_isolation'; --查看系统默认的隔离级别。
b)show transaction_isolation; --查看当前会话的事务隔离级别。
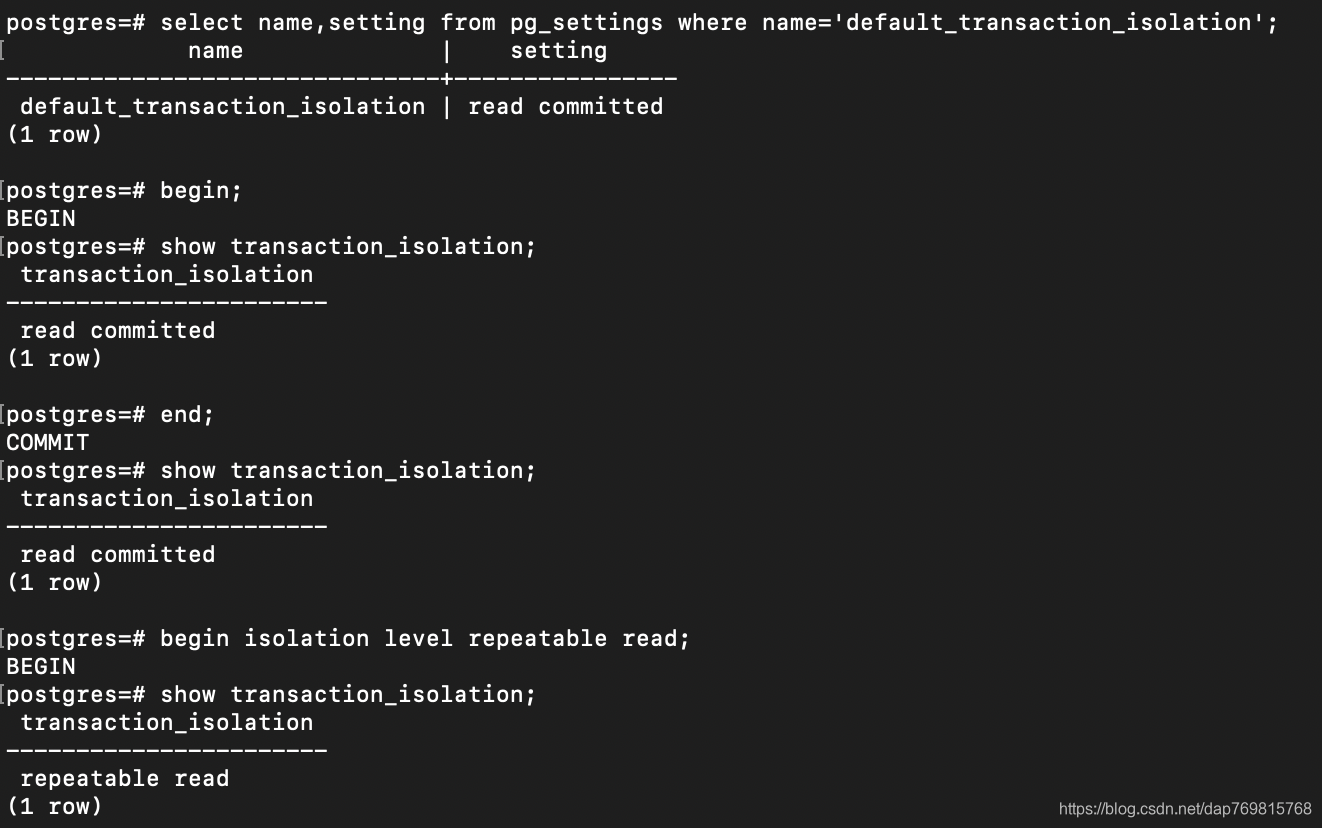
我们可以看到系统默认的事务隔离级别是读提交。
如果想查看有哪些隔离级别,使用\h begin;查看:
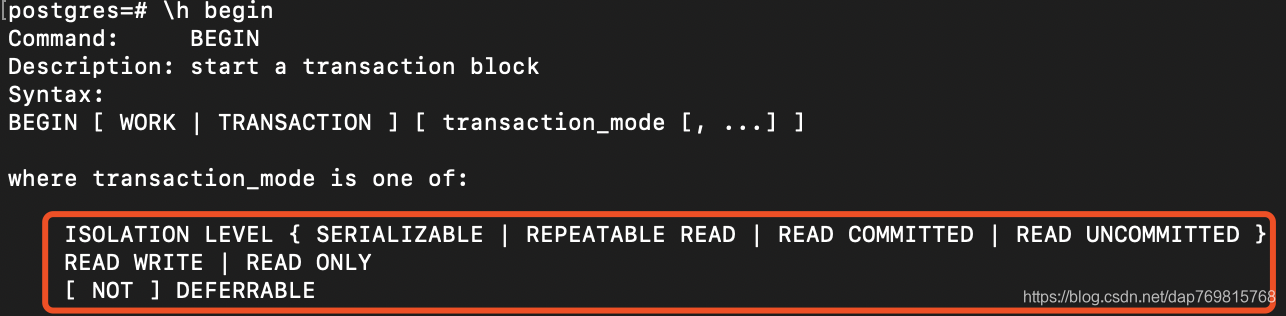
4.锁。
使用上面的可复读事务,我们很自然会想到一个问题,如果是两边同时增加,会怎样,看下面的例子:

上面的操作,不管是哪个事务限制性插入性语句,其结果都会导致重复,注意开启事务的那个不要忘记先执行一次查询,否则不会生成数据库快照。如果是手动开启事务的先执行,导致重复的原因是事务尚未提交,另一个回话读不到数据,因此数据库使用的默认事务隔离级别是读提交,这种情况下一个回话是读不到另一个事务尚未提交的数据的。如果是非手动开启事务的先执行,导致重复的原因是因为使用的事务隔离级别是可重复读,数据库读不到最新的数据。
这种结果显然是我们不想要的,第一个回话在事务里做了检查,如果不存在才插入,但是仍然多插入了一条数据进去,这种结果显然不是我们想要的结果,这就是开启了可重复读可能带来的问题。如果想解决这个问题,可以通过加锁的方式解决:
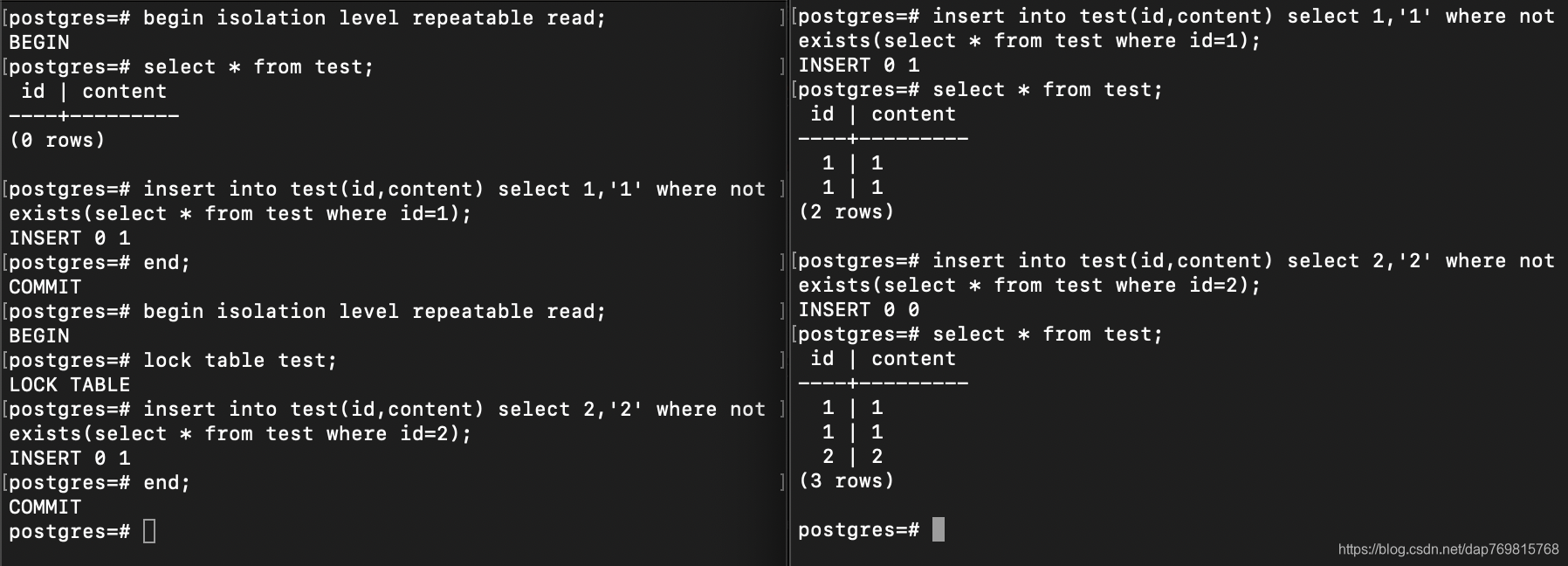
第一个回话的事务,通过lock,将表test锁住,第二个回话尝试修改test,会阻塞。直到第一个事务结束释放锁,它才会继续执行,所以这次的执行结果是正确的结果。
5.postgresql的咨询锁。
上面对test表加锁的操作,会让你很自然地想到,如果将整张表都锁住,那么当并发量很大的时候,将会阻塞大量的数据库操作,这样显示不合适的。那么有没有更细粒度的锁呢,这样就可以通过把锁的级别尽量降低些来提高系统的吞吐能力了,答案是肯定的。postgresql里面有个锁叫做咨询锁。看下面的操作:

这个锁和编程语言里面的锁差不多,对一个常量进行加锁,另外一个常量再对它进行加锁,就会阻塞,直到之前的线程释放了该锁。
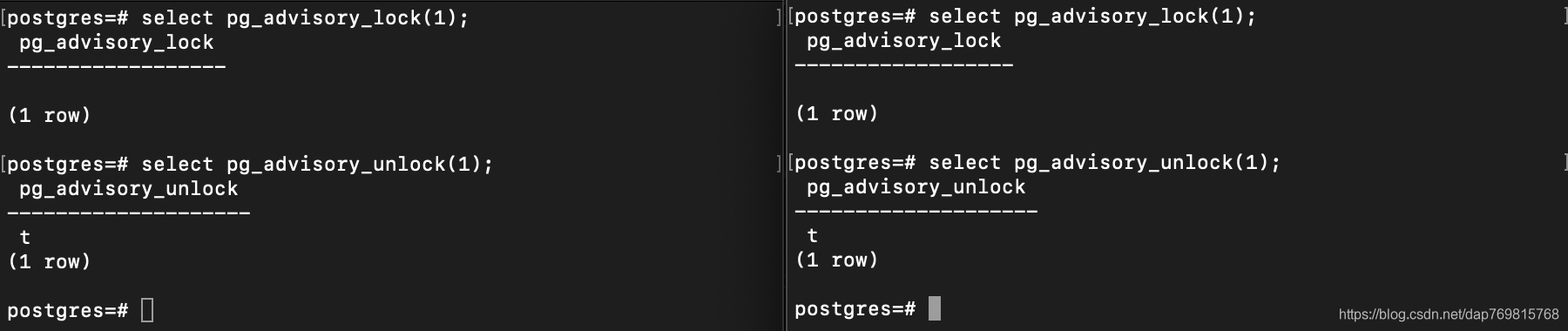
这个锁不会随着事务的结束,自动释放,需要手动释放,这点需要特别注意。
它加锁的时候使用命令:select pg_advisory_lock(1);
释放锁的时候使用命令:select pg_advisory_unlock(1);
所以刚刚的问题,我们可以这样解决:
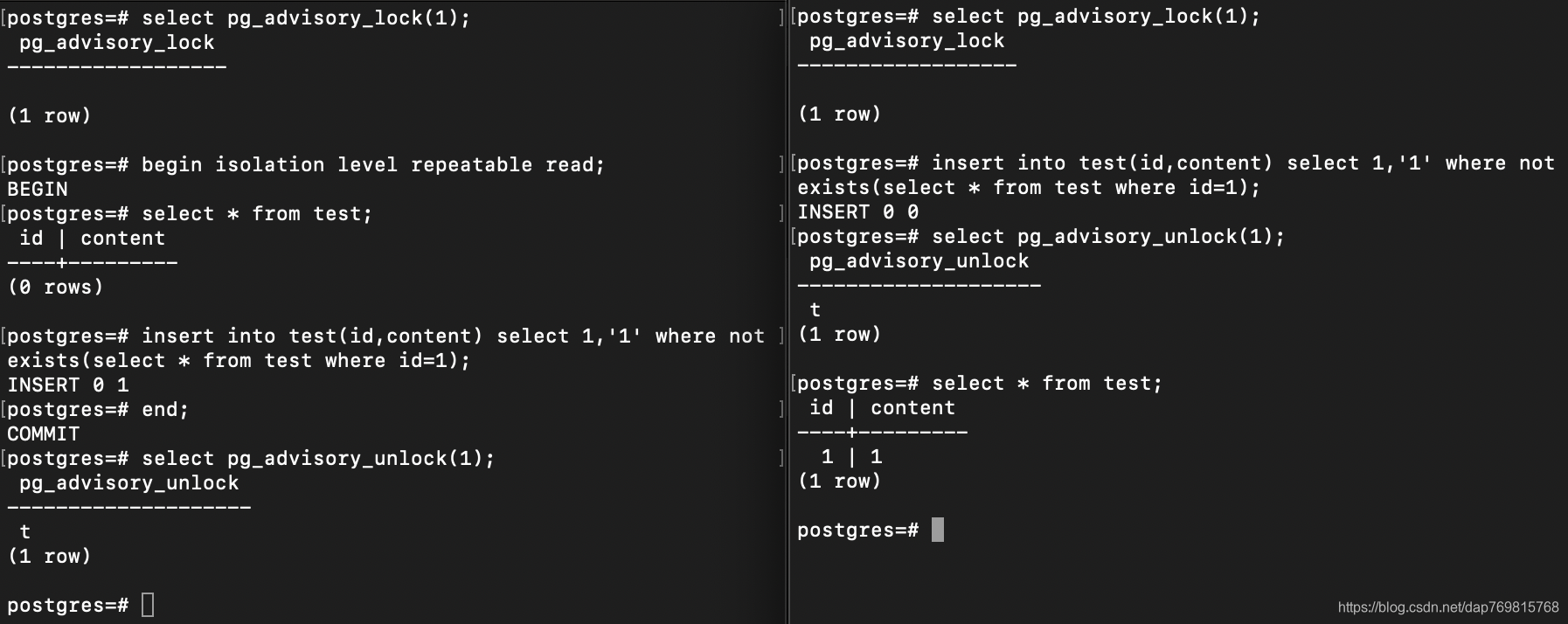
需要注意的是,咨询锁,只能锁整数。
6.辅助表。
上面采用咨询锁可以实现级别相对较低的锁,这里提供一个使用辅助表的方案,来实现用户级别的锁。

要说明的是,该种加锁的方案只能放到事务里面,同时要求能根据条件查询到数据,也就是辅助表里面必须有lockid=1这条数据,否则将不会起效果。锁会随着事务的结束自动释放,如果不希望阻塞,则加上nowait。如下:

当然,这个不一定非要使用辅助表实现,任何表都可以帮助实现这种加锁的方式,具体怎么加锁,要根据你的项目实际情况来定。
7.行级锁。
数据库本身会默认提供一个行级锁。看下面的操作:

当两个线程同时更新同一条数据的时候,由于行级锁的作用,会导致其中一个阻塞。
8.死锁。
由上面的行级锁,我们很容易想到,当两个线程更新的行有交叉,那么就很容易导致死锁:
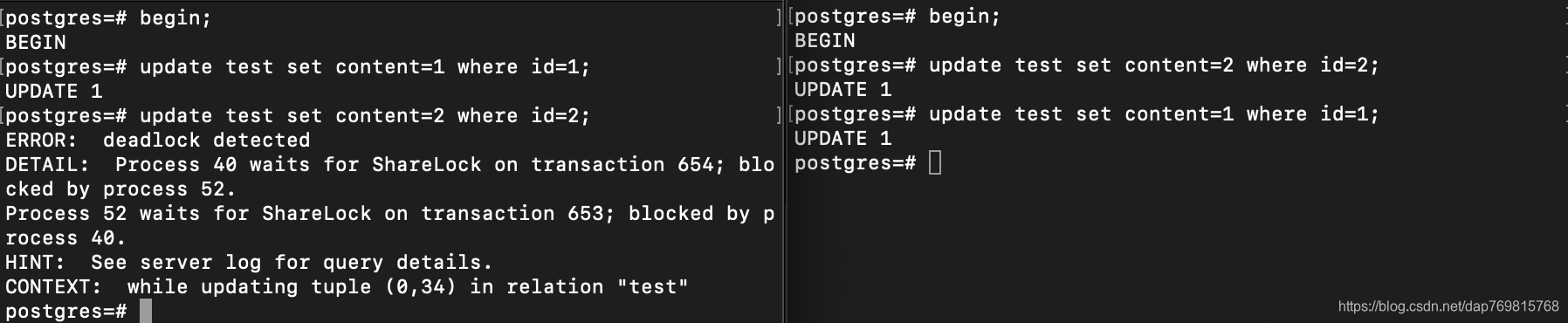
这种情况下,数据库直接检测出了我们的操作存在死锁的情况,给我们返回了错误的结果。
应当说,在高并发环境下,死锁是很容易发生的,解决办法则根据实际情况来定。具体涉及到你的数据库操作策略,事务隔离级别等等。pg这个数据库在一些死锁的情况下会直接返回错误,而不是让线程一直卡着,这点我不知道其他的库是否也如此,也不太清楚pg是否能检测出所有的死锁情况。另外如果出现了死锁,在postgresql里面可以通过一些命令临时排出故障。
使用elect locktype,database,pid,relation ,mode from pg_locks;查看当前锁的使用情况:
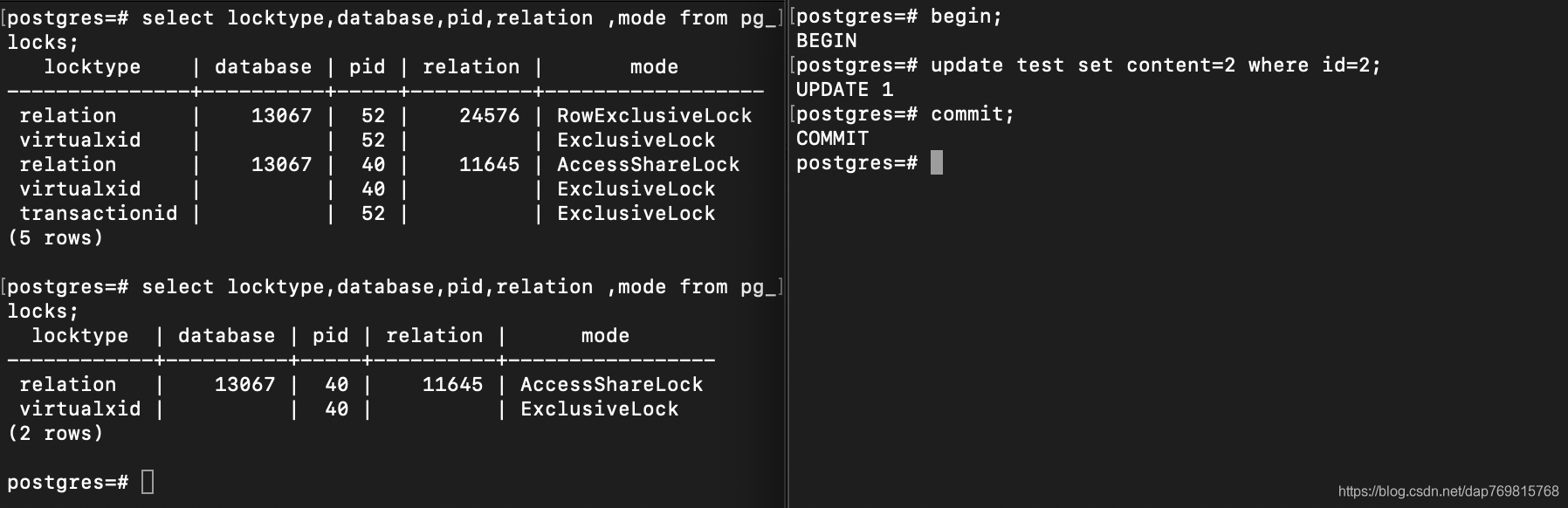
使用select pg_terminate_backend(pid);终止某个线程:
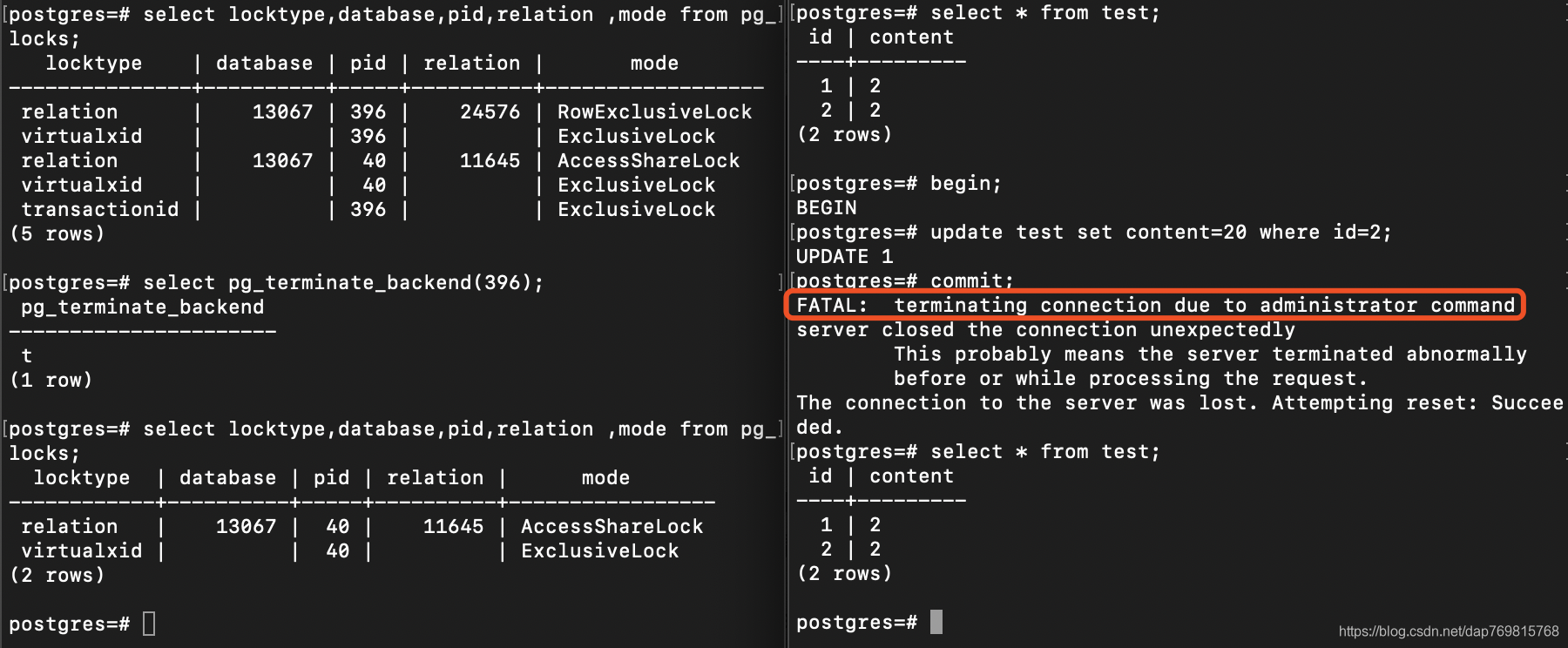
我们看到正在进行的会话,如果被终止了,将会返回错误。另外pg还提供了其他的函数,来发现和解决死锁的问题,我提供的只是比较基础的方法。如果你有兴趣,可以翻看下pg的官方文档。
9.这一部分,我对上面提到的几种事务隔离级别做下稍微详细些的分析,看看他们都各适应些什么场景。
在Postgresql的官方文档里面,定义了四种在不同事务级别禁止的现象:
a)dirty read(脏读)
A transaction reads data written by a concurrent uncommitted transaction.
一个事务读到了另一个并发事务未提交的数据。
A transaction re-reads data it has previously read and finds that data has been modified by another transaction (that committed since the initial read).
一个事务重复读它之前读过一次的数据,发现数据被另一个事务修改了(该事务的提交时间是在之前的事务第一次读数据之后),即同一个事务期间,两次查到的数据不一致。
这里面包含了两个信息(另一个事务必须提交,另一个事务提交的时间在读数据事务第一次读之后)
A transaction re-executes a query returning a set of rows that satisfy a search condition and finds that the set of rows satisfying the condition has changed due to another recently-committed transaction.
一个事务重复执行一个能够得到一组满足某个查询条件数据的指令,发现这组满足查询条件的数据被另外一个最近提交的事务修改了。
所谓幻读是第一次没有读到,后面要根据前面读到的结果进行插入数据,满足条件就插入,在执行插入数据的时候,原本满足条件的数据被修改了,导致本不该插入的数据被插入了。它是由于读条件和执行指令之间有一个时间差导致的,但是这个时间差是没法避免的,虽然这个时间差可能很小,在高并发环境下,这个时间差范围内很可能有另外一个线程修改了数据。比如这句:
insert into user(id,name) select 1,'tom' where not exists(select * from user where id=1);
这句语句在执行的时候,要先去判断是否存在id=1的值,不存在才插入数据,如果在这期间另一个线程恰好插入了一条id=1的数据,那么数据库就出现两条id=1的数据了。
d)serialization anomaly(序列化异常)
The result of successfully committing a group of transactions is inconsistent with all possible orderings of running those transactions one at a time.
成功提交一组事务的结果与一次运行这些事务的所有可能顺序不一致。
下表列出了plsql支持的四种事务隔离级别,和它造成上述问题的可能性:

这四种是sql标准定义的事务隔离级别。注意看表格里面列出的信息,标识了“but not in PG”的表示在pg里面不会出现。所以在pg里面Read uncommitted和Read committed表现一样。
一些PostgreSQL的数据类型和函数有特殊的规则,会无视掉事务级别的限制,特别是在序列变更的时候,会直接对其他的事务可见,也不会因为事务的终止而回滚。
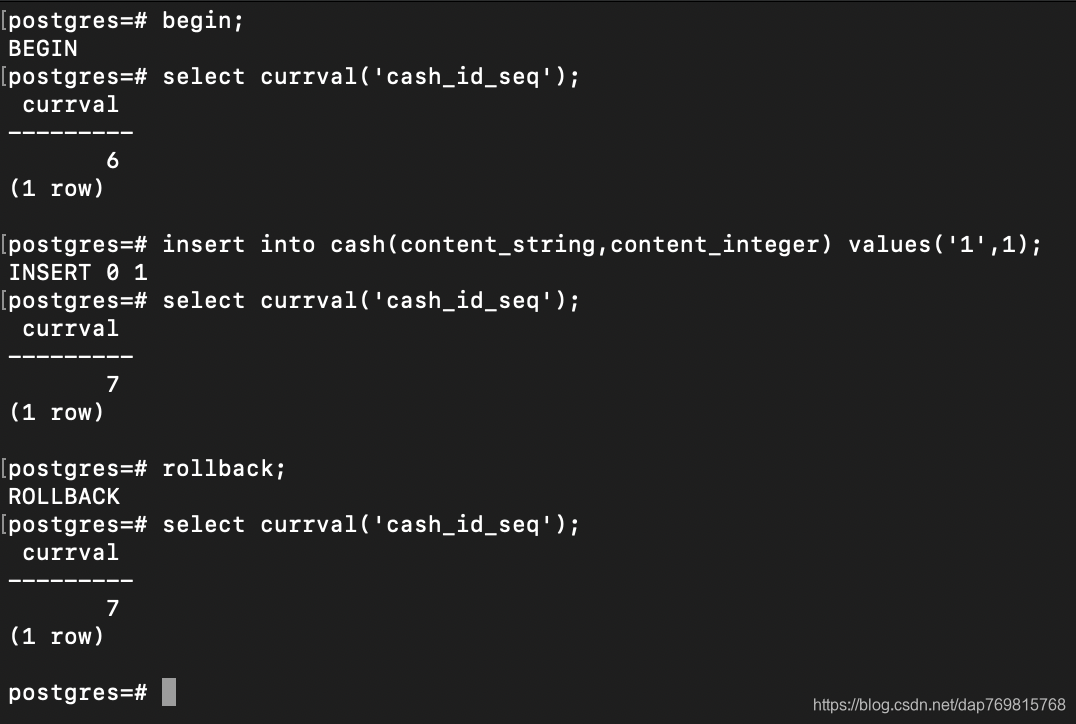
currval函数需要你执行一次nextval才能使用,否则会报currval of sequence "cash_id_seq" is not yet defined in this session的错,这是因为在一个连接会话中,currval是保存在内存中的,所以不要尝试使用currval查看某个序列当前的值,不然你的sql可能会报错。同时当别的会话更新了序列,它的值并不会跟着更新,导致它的结果是不准的,想获取到准确的结果,推荐使用select * from cash_id_seq;
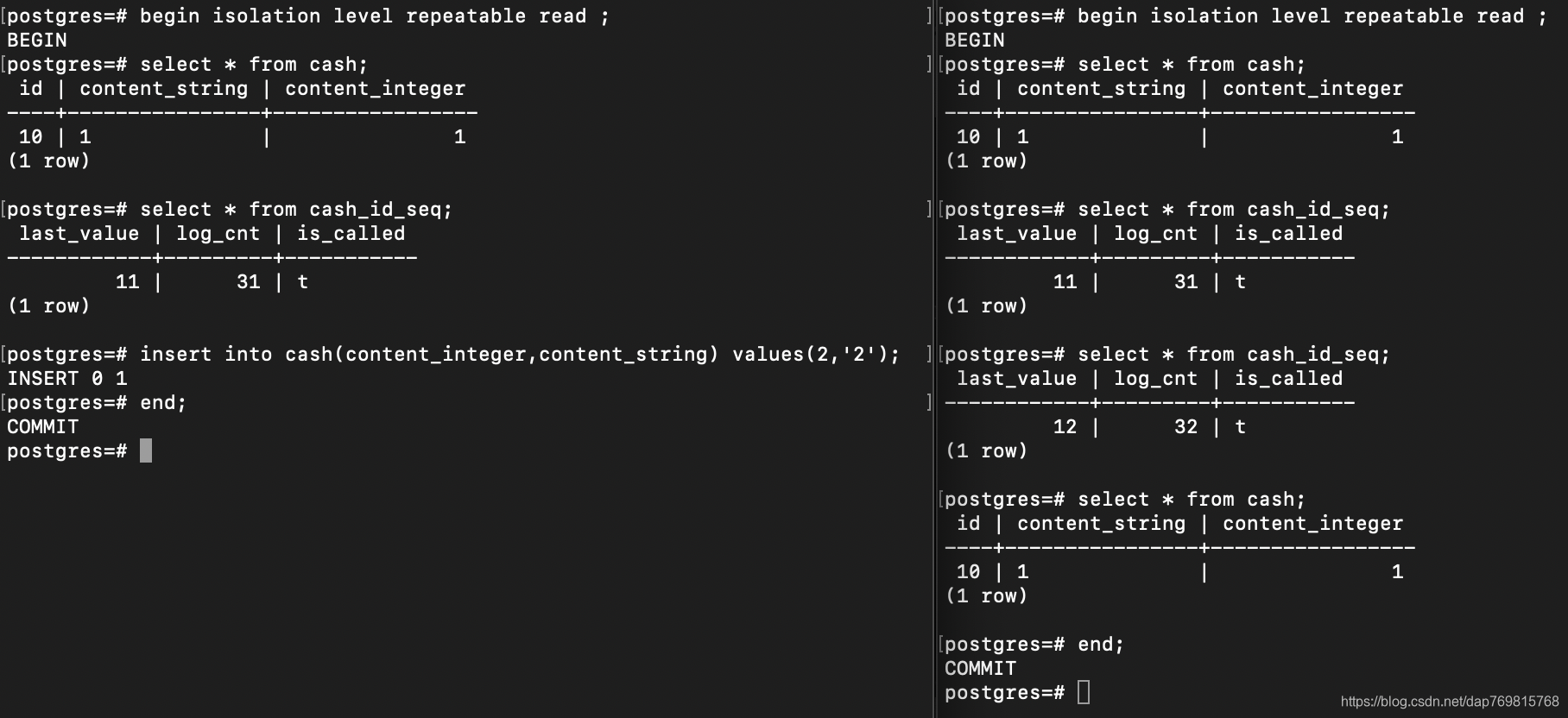
从上面的操作可以看出,即便是可重复读级别的事务,序列对于其他事务也是可见的。
下面对于四种隔离级别的详细说明。
1)Read Committed Isolation Level(读提交)
读提交是pg默认的事务隔离级别。当一个事务使用此隔离级别时,一个select语句(不包含FOR UPDATE/SHARE)只能看到在该语句执行之前被另一个并发事务提交的数据,它永远看不到另一个并发事务未提交的数据以及在查询语句执行期间提交的更改。
实际上,一个select语句看到的是请求开始执行瞬间的数据库快照。但是,select语句看得到它所在的事务里面之前执行的更新产生的影响,即使这些更新尚未提交。
提醒一下,两个select指令可能会看到不同的数据,即使它们在同一个事务里面,如果其他事务提交了更改,提交时间是在这两个select之间,就会产生这种情况。
就搜索目标行而言,update, delete, select for update, 和 select for share指令表现出来的效果和select一样:它们都只能查到指令开始时被提交的行。但是,这样的行很有可能已经在被查询时被另外一个并发事务修改了(或删除、或锁定),这种情况下,在尝试修改的时候就需要等待第一个修改了它的事务提交或者回滚。如果第一个事务回滚了,那么它的影响是负面的,第二个修改者可以继续修改原始发现的数据行。如果第一个事务提交了,如果某个行被删除了,第二个修改者会跳过它,否则,第二个修改者会在已经修改的行的基础上进行操作。指令的搜索条件(where后面的条件)会被重新评估是否被更新的行仍然满足搜索条件。如果满足,第二个修改者会继续在被修改的行上操作。这意味着,在select for update和select for share这种情况下,被锁定和返回给客户端的行的版本是修改了的版本。
在读提交模式下,insert语句中如果包含on conflict do update语句,结果是相似的,要么插入新数据,要么更新数据。两种结果是有保障的,除非有不相关的错误出现。如果冲突是源于另外一个事务,且它的影响对insert尚不可见,那么update语句就会影响该行,即便该命令通常看不到该行的任何版本。
由于另一个事务的结果对插入快照的效果不可见,如果插入时与on conflict do nothing子句冲突,则该子句可能会使行的插入无法继续。同样,这只是在read committed模式下的情况。
INSERT with an ON CONFLICT DO UPDATE clause behaves similarly. In Read Committed mode, each row proposed for insertion will either insert or update. Unless there are unrelated errors, one of those two outcomes is guaranteed. If a conflict originates in another transaction whose effects are not yet visible to the INSERT , the UPDATE clause will affect that row, even though possibly no version of that row is conventionally visible to the command.
INSERT with an ON CONFLICT DO NOTHING clause may have insertion not proceed for a row due to the outcome of another transaction whose effects are not visible to the INSERT snapshot. Again, this is only the case in Read Committed mode.
由于以上的规则,更新命令可能会看到不一致的快照:它可以看到并发更新指令作用在相同的行上时产生的影响,但看不到那些指令作用到其他行上时产生的影响。这种表现导致度提交模式不适合涉及复杂查询条件的指令。但是它正好适合简单的情况。比如,考虑下面的更新银行余额的事务:
BEGIN;
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 12345;
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 7534;
COMMIT;如果两个并发事务尝试更改12345账号的余额,我们显然希望第二个事务以最新的账户信息为基础开始更新。因为每个指令都是仅仅影响特定的行,让它看到最新的行数据,并不会有什么不一致的问题。
在读提交模式下,更复杂的应用可能会产生意料之外的结果。比如,考虑一个delete指令,它所操作的数据正在被另一个指令添加新数据或者从它的限制条件中移除数据。假设website表里面有两条数据,hits等于9和10:
BEGIN;
UPDATE website SET hits = hits + 1;
-- run from another session: DELETE FROM website WHERE hits = 10;
COMMIT;delete语句不会删除任何数据,即使update语句执行前后都存在hits=10的数据。这是因为在执行语句时hits=9被跳过了,当update语句完成时,delete获得锁,新的行的hits不再是10,而是11,它不再满足删除的条件了。
因为读提交模式执行每条指令,都是基于一张最新的快照,这张快照包含了所有已经被提交的数据,因此同一事务的后来指令在任何情况下都可以看到并发事务提交的效果。上面的问题是,是否单条命令能够看到绝对一致的数据库视图。
读提交模式提供的部分事务隔离对于大部分应用程序来说是足够的,这个模式用起来简单快捷,但是它不能满足所有的情况。应用程序如果执行复杂的请求和更新可能需要比读提交模式更严格的数据库视图一致性。
2)Repeatable Read Isolation Level(可重复读隔离级别)
可重复读只能看到事务开始前被提交的数据(但是,请求能看到自己所在事务里面之前进行的修改操作),这是sql标准定义的相对较强安全保障的隔离级别。在sql标准里面,它可能出现幻读,但在pg里面,它只会出现序列化异常,不会出现幻读。
该隔离级别查询时使用的快照是事务里第一条非事务控制语句开始时所拍的数据库快照。
考虑到序列化失败的可能性,使用此级别的应用程序必须有重试事务的准备。
此隔离级别存在死锁,当两个使用此隔离级别的并发事务同时更新同一行时,会导致后面执行更新语句的事务报错:

所以要考虑失败的可能,并且做好重试的准备。在读提交的隔离级别中,并不会存在这个问题。
只有在更新的时候才会有这个冲突,单纯地读数据并不会有这个冲突。
3)Serializable Isolation Level(串行隔离级别)
数据库最严格的隔离级别,看下面的操作,在可重复读的隔离级别中:
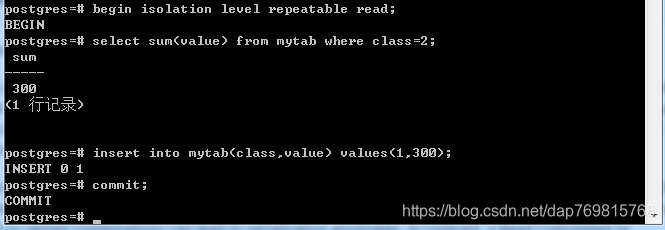
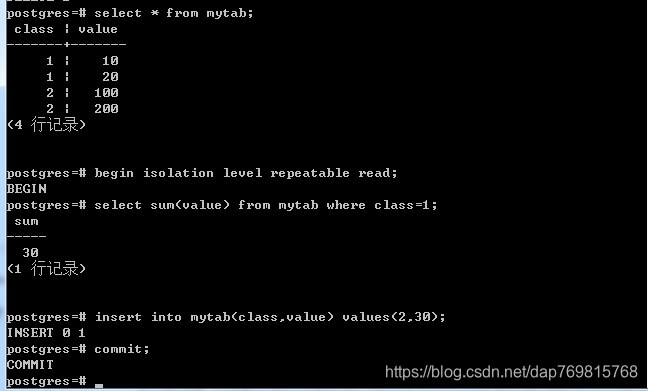
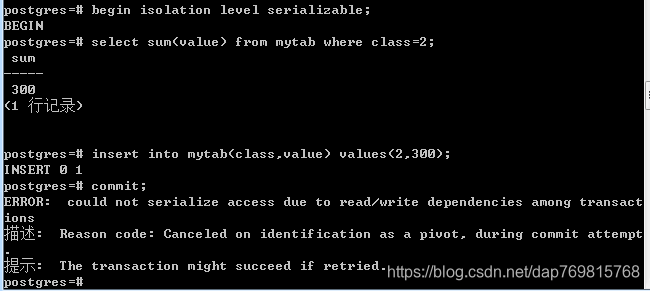
尝试计算总和,并插入一条新数据,两个并发事务一起提交,是没有问题的,但是如果换成串行化隔离级别:
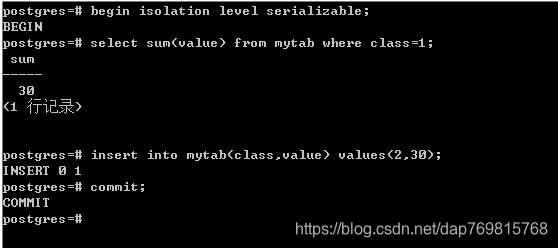
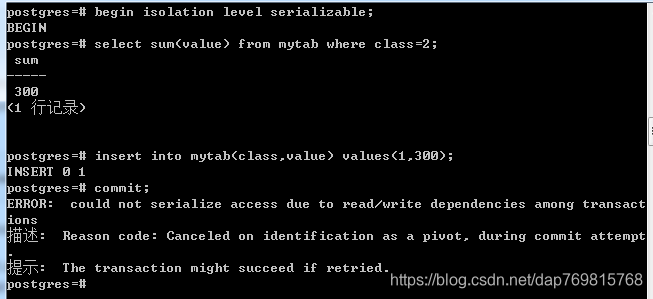
由此可见串行化的隔离级别非常高,连计算总和这种操作的条件都要考虑进去。刚才我演示的两个事务是相互影响的,如果插入的数据不相互影响,第一个事务插入class为1的数据,第二个事务插入class为2的值,这两个事务理论来讲,不会有任何影响,但是由于串行化的隔离级别很高,这里仍然会认为可能会相互影响,导致无法提交成功:
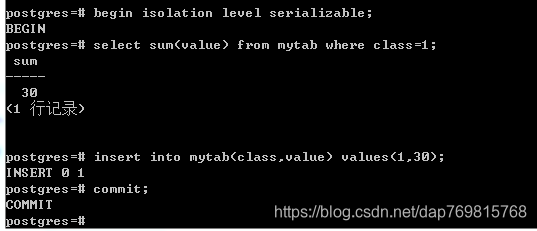


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









