





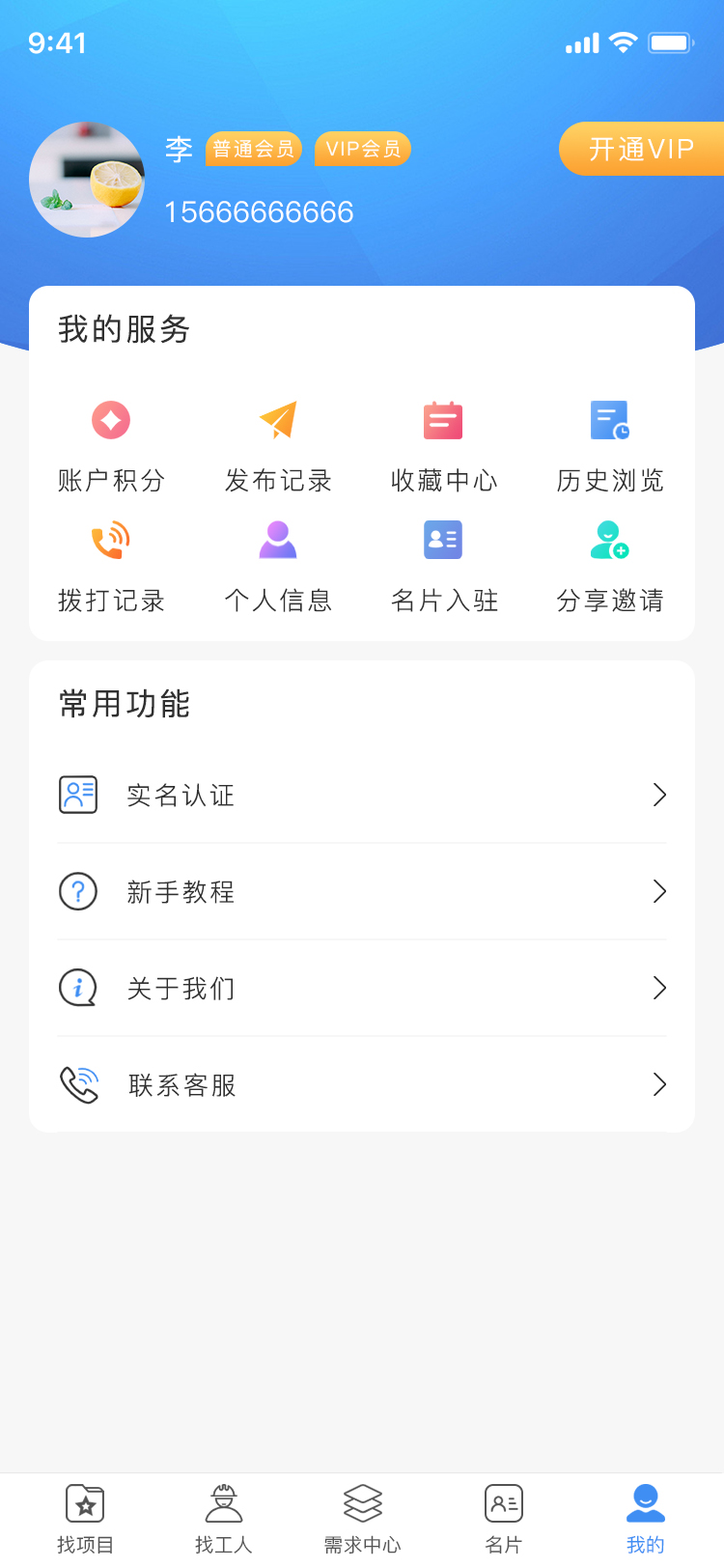
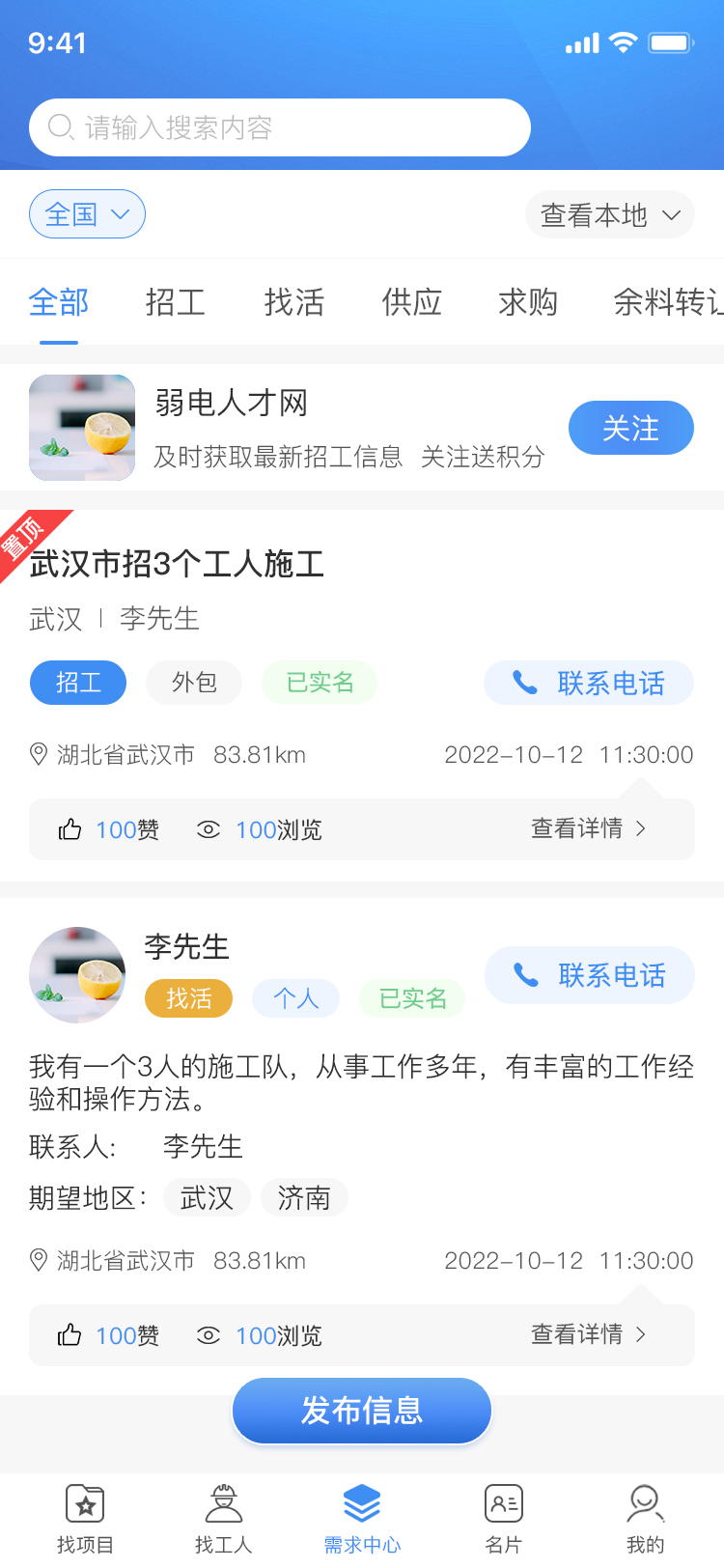
仿鱼泡网小程序可以帮助用工单位和人力资源公司解决招工问题,岗位类别自定义添加、全国城市切换、积分拨打电话,vip充值等、招工信息发布、找活信息发布、名片信息发布、需求发布、vip充值等,可查看头像数字有演示,有成品,也可按需定制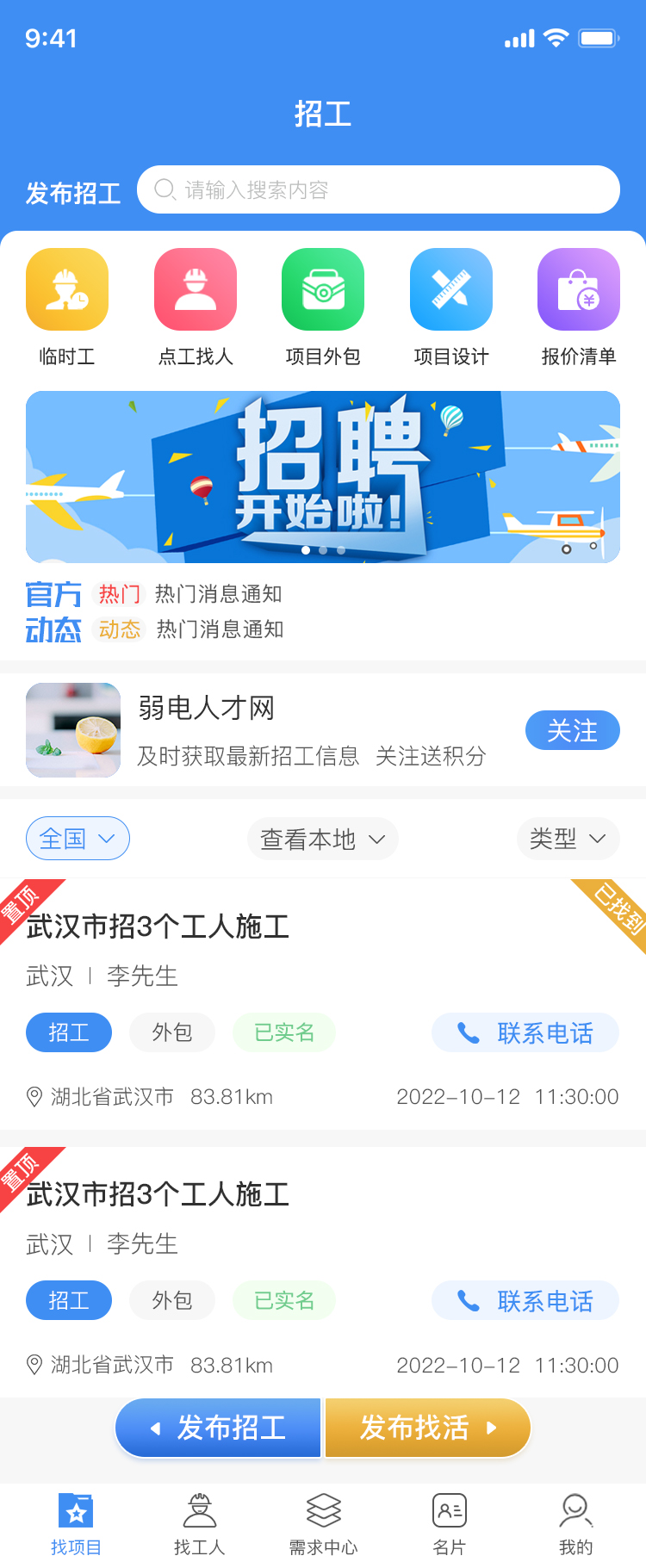
仿鱼泡网招聘小程序灵活用工小程序源码招工小程序开发
最新推荐文章于 2025-06-06 01:14:14 发布

仿鱼泡网小程序可以帮助用工单位和人力资源公司解决招工问题,岗位类别自定义添加、全国城市切换、积分拨打电话,vip充值等、招工信息发布、找活信息发布、名片信息发布、需求发布、vip充值等,可查看头像数字有演示,有成品,也可按需定制
 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























