






 本文介绍如何在Windows环境中使用Eclipse配置Hadoop,并解决遇到的“HADOOP_HOMEandhadoop.home.dirareunset”错误。通过在本地放置Hadoop程序包、正确配置环境变量等步骤,成功实现WordCount程序的运行。
本文介绍如何在Windows环境中使用Eclipse配置Hadoop,并解决遇到的“HADOOP_HOMEandhadoop.home.dirareunset”错误。通过在本地放置Hadoop程序包、正确配置环境变量等步骤,成功实现WordCount程序的运行。
结论
先说结论。最后问题解决了。终于能在windows的eclipse上通过执行wordcount类,然后将某个文档内容处理后,将结果传到远程服务器的hadoop的某个文件夹下了。
当时的环境
我已经在linux服务器上安装了分布式的hadoop环境,一namenode两datanode。而且已经在linux服务器上测试过hadoop2.8自带的wordcount的jar的运行。可以正常运行并得到结果

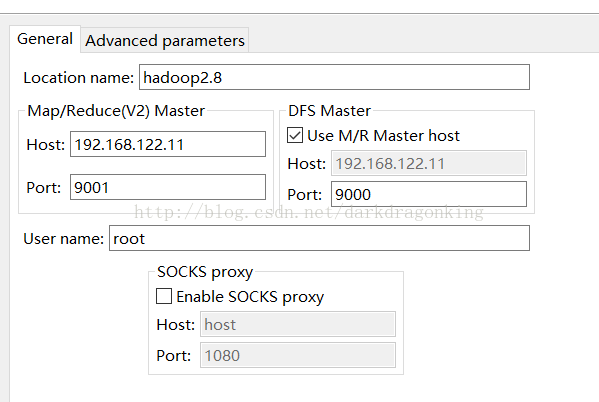
上图中的advanced parameters中仅修改了hadoop.tmp.dir属性,改为我在linux中的/usr/local/hadoop/tmp的路径而已。其他属性都是默认值。
将hadoop自带的wordcount.class反编译后放到一个新建立的mapreduce工程中。工程里面用到的jar包来源于hadoop2.8自带的所有jar包。代码仅有一个wordcount.java,没有其他辅助配置性信息和java文件。代码关键部位如下图所示
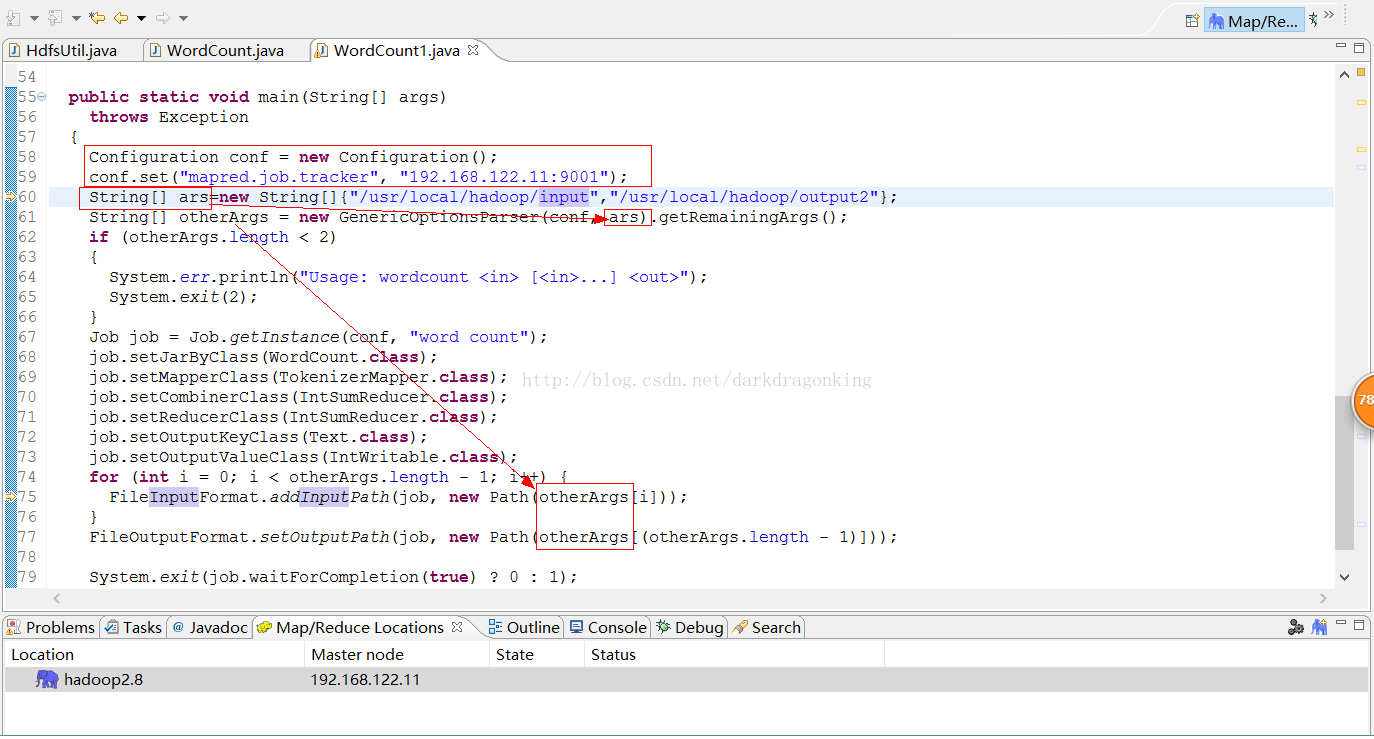
其中入参和出参都在名为ars的字符串数组中定义了。而且那个入参要在linux服务器上真实存在,出参应该是个空的路径,否则会报路径已存在的错误。
问题的产生
当我运行这个java文件的时候,报错“HADOOP_HOME and hadoop.home.dir are unset”。然后我就懵逼了。
解决步骤
题外话:我一直认为,我本地的eclipse就是个调用远程hadoop的作用,所以本地的windows操作系统中不需要安装hadoop了。所以我看到这个HADOOP_HOME的时候一直不明白,难道我还需要在我本地安装一个hadoop吗????
其实答案是:是的。我倒霉就倒霉在没有在本地放一个hadoop。这个hadoop不需要安装,不需要像网上说的得先安装一个什么Cygwin(说个题外话,我始终认为,这个东西就是在windows上模拟一个类似linux的环境出来。然并卵。)。只需要找一个hadoop2.8的二进制包(官网上这个东西大概400多兆),解压放到你windows下的某处即可。
然后重点在这里,仅仅解压缩了这个hadoop的包还不够,还需要这俩东西:hadoop.dll和winutils.exe及其附属(hadoop.exp、hadoop.lib、hadoop.pdb、libwinutils.lib、winutils.pdb)。缺少会报错,我在报错前已经把这俩及其相关的东西都放上了,所以不知会报啥错。
有点扯远了,还说在本地放hadoop程序包的问题。只要解压了程序包,同时在你的环境变量中的系统变量中配置了HADOOP_HOME并且指向hadoop程序包的本目录即可(如我本机就是F:\work\software\linux\hadoop-2.8.0),并且在系统变量的path中附加了%HADOOP_HOME%/bin(这里一定要指向到bin这一级才行)就能在你的windows上运行wordcount程序了。
有的人仅仅配置了上一步还不够,还需要重启一下电脑才行。我就属于这部分的。。。
然后后面可能还会出一些其他jar包找不到的错误,从网上找一下放上就全都ok了。
感想
本地的hadoop其实真的真的没有参与干活儿。因为我连启动都没启动过本地的hadoop。但是在本地的hadoop所属盘符的根目录下生成了一系列的目录。虽然不知是啥原因,但我瞎想可能主要起到一个临时缓存的目的。
生成这个缓存路径的原因应该是hadoop本身系统的相关设置。或者准确来说,是mapreduce本身的设置决定的。要有一个缓存路径。所以在windows上设置hadoop_home的目的就是为了给这个缓存用的。
而且如果是在linux系统上执行wordcount的jar包的时候,应该会在服务器上生成这么一个缓存路径。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









