









KAFKA中的索引与数据文件的分析
创建topic

来到KAFKA存储目录,发现已经有了两个分区的数据:
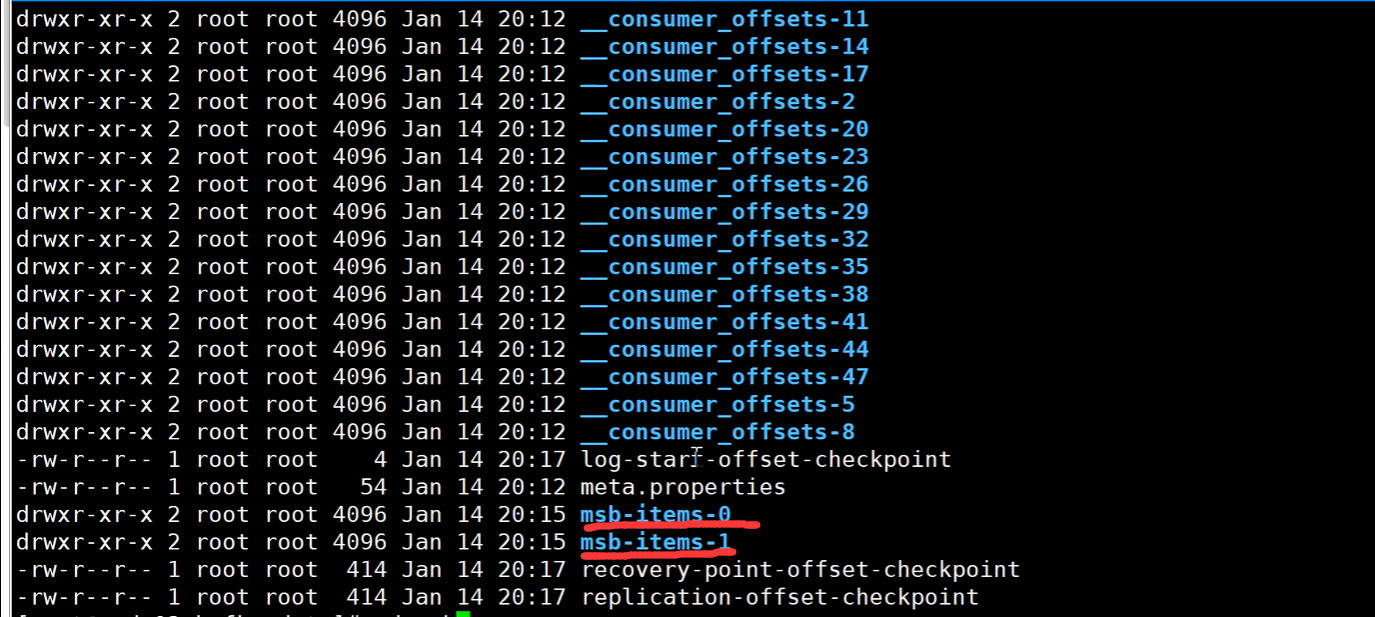
进到0号分区的文件夹:

发现有.log结尾的数据文件,.index结尾的偏移量索引文件,.timeindex结尾的时间戳二级索引文件
但我们发现,我们现在还没有写入消息,但两个索引文件就已经有了10M的大小,这是为何?
这是因为kafka对索引文件使用的是mmap映射,已经预分配好了10M的磁盘块大小的空间,通过lsof查看kafka进程号观察这个细节:

可以看到SIZE/OFF的位置上,确实已经有了这个信息。
继续向下看,关于log数据文件的:

发现就是普通的文件描述符,没有使用mmap。但可以使用OIO(BIO)或者NIO的IO实现。
为什么log数据文件不使用mmap?
数据文件使用普通IO是为了保证通用性,可以在应用程序级别对数据写入磁盘的可靠性进行控制:
在应用程序中,使用OIO可以控制单条还是批量的写入到pagecache中,而使用NIO的filechannel,可以通过调用write+force,完成单条/批量的直接刷写到磁盘,这里有个数据可靠性和性能的通用性取舍存在:是单条force强可靠性,还是写入到pagecache依赖内核刷写,保障高性能?
注:在java中,传统的OIO API,flush方法都是空实现,实际还是把数据落到pagecache中,依赖内核的dirty刷写到磁盘。 需要真正意义到磁盘,需要NIO的force的调用
格式化查看KAFKA的数据和索引文件
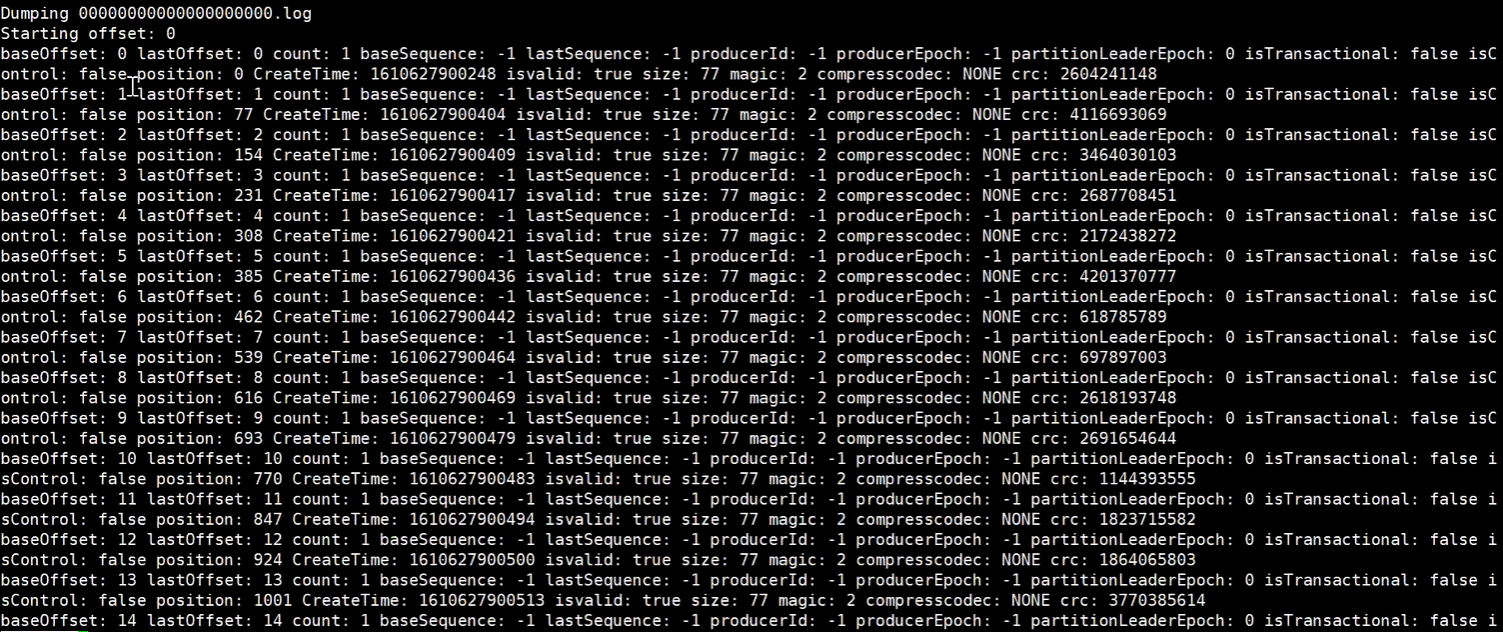
通过producer生产一些消息后,我们来分别查看这三个文件的内容:
数据文件
kafka-dump.log.sh --files 000000000000000.log
index索引文件
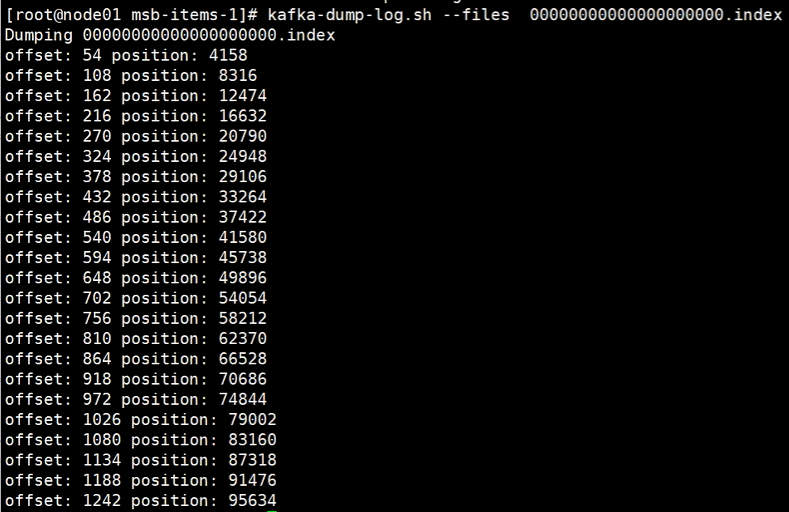
kafka-dump.log.sh --files 000000000000000.index
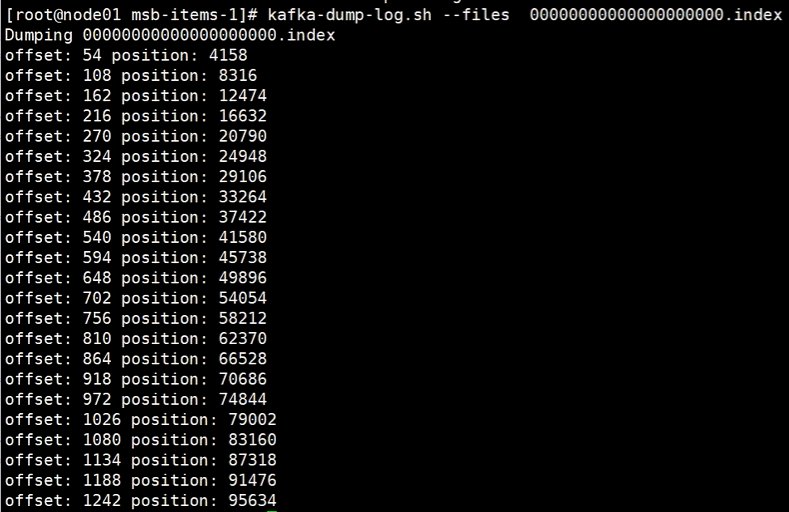
这个文件里记录的就是偏移量的索引,每一行都是一块偏移索引段。
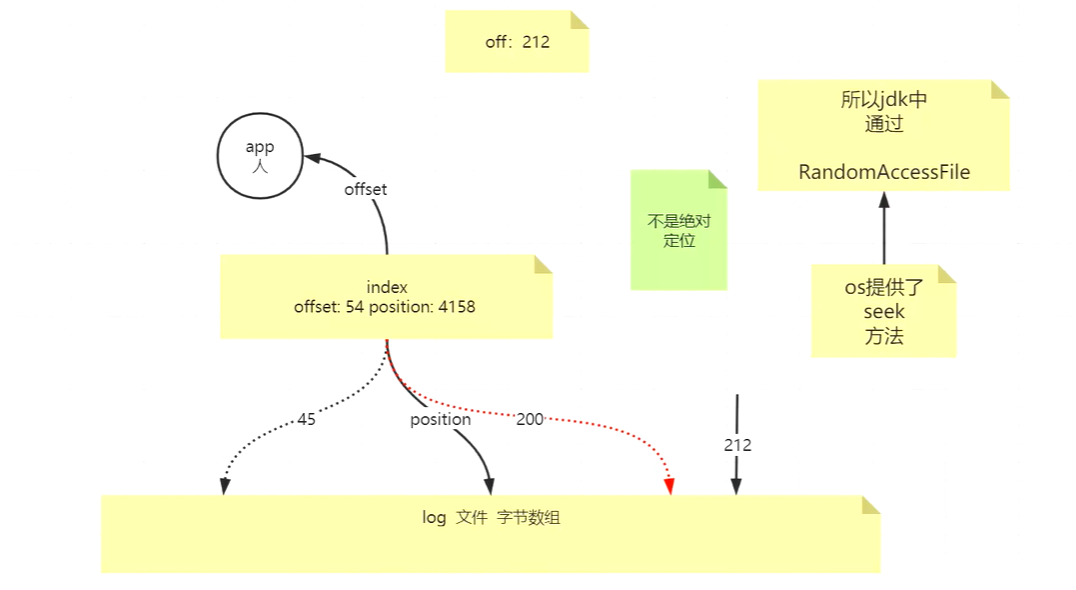
offset代表的是数据的实际偏移位置,是人性化展示的,而position指的则是字节长度,因为数据本质是作为字节数组被存放的。
既然是段,那么在索引某个具体offset数据的时候,首先需要通过seek直接定位到相邻最近的offset段的位置,然后再向后继续读取,这样的seek行为可以减少许多无效的读取。
时间戳索引文件
kafka-dump.log.sh --files 000000000000000.timeindex
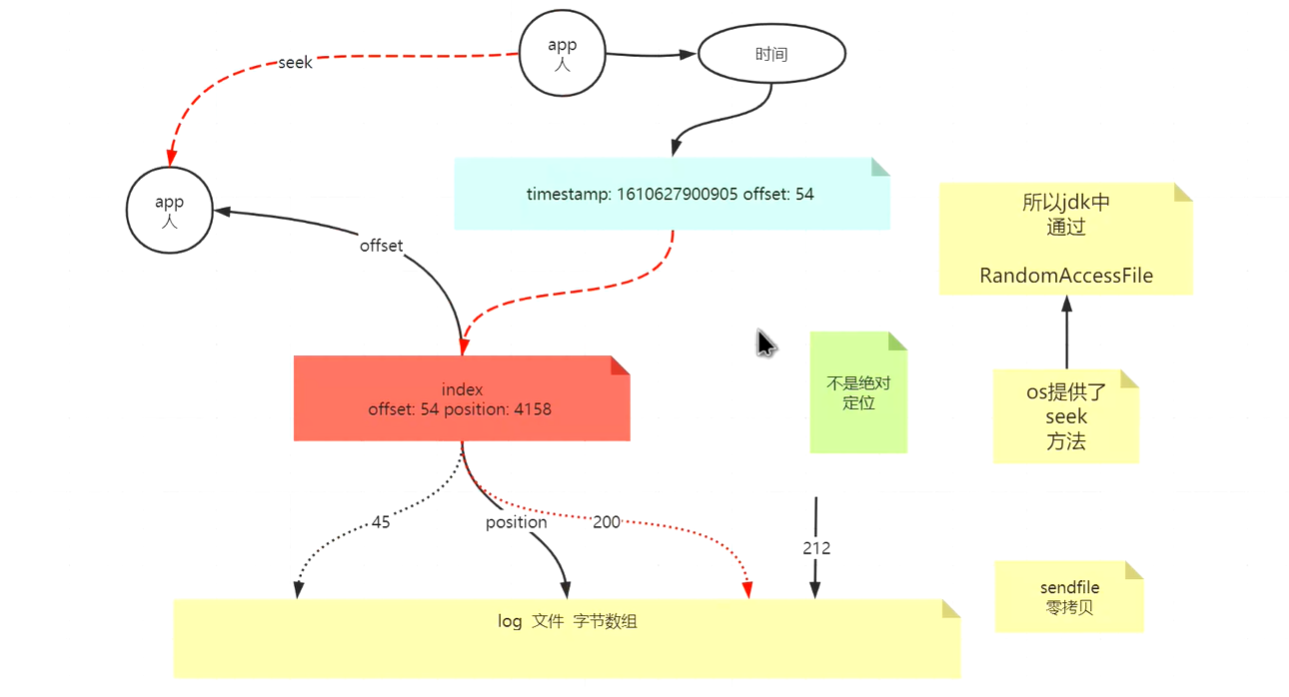
当在kafka中使用时间戳索引的时候,需要根据需要寻找的时间戳在时间戳索引seek到对应的时间戳段,然后通过这个时间戳段对应的offset段,再从在**.index**文件中找到对应的offset段,然后再偏移到实际数据的位置。 可以由此看出,时间戳索引是一个二级索引,需要完成两次索引操作。
KAFKA的ACK级别设置
通过在java代码中为生产者设置ACK的级别,0,1,-1,
Properties props = new Properties();
props.put(ProducerConfig.ACKS_CONFIG, "1");
当ACK设置为0的时候
props.put(ProducerConfig.ACKS_CONFIG, "0");
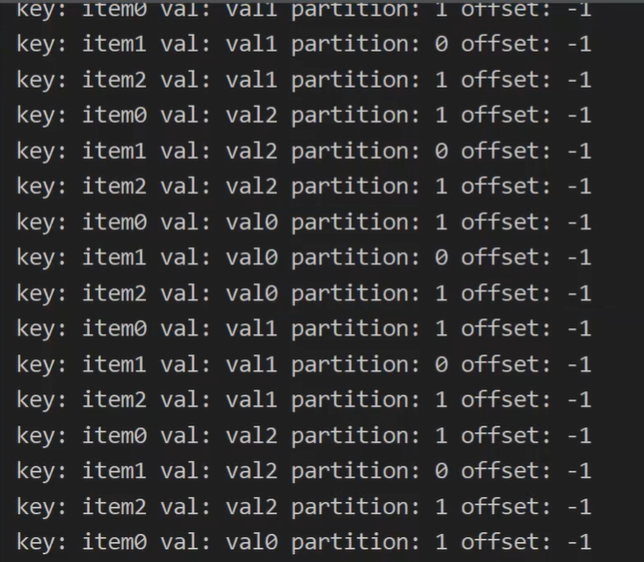
此时生产者发送的消息,发现确认返还的offset是-1,因为此时的级别根本没等broker给出响应,只管发出。
当ACK设置为1的时候
props.put(ProducerConfig.ACKS_CONFIG, "1");
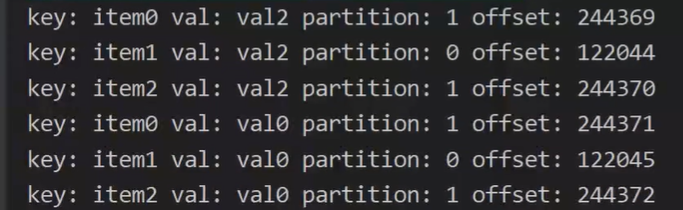
只要broker接受成功,返还ACK,此时的响应的offset就是新生成消息的offset。
当ACK设置为-1的时候
props.put(ProducerConfig.ACKS_CONFIG, "-1");
此时需要集群中的ISR集合的broker都接受成功,返还ACK,此时的响应的offset就是新生成消息的offset。
可以进行实验:
实验1:手动下掉某一台broker,观察生产的细节,会发现当切断后生产者的生产消息的请求响应会有一个停顿,然后依旧返回,这个停顿的时刻,是kafka的集群在把不可用的broker进行剔除。
实验2:还可以尝试设置某一台broker的网卡路由,使其不可对外发出ack,此时观察生产的细节,会发现生产者的生产消息的请求响应会有一个停顿,这个停顿的时刻,是kafka的集群在把这一台故障broker剔除ISR,归入OSR中, 此时如果集群中响应ACK的数量达到了最小ACK的ISR数量,依然会成功返回消息的offset。
基于时间戳的消息索引代码实现
/**
* 以下代码是通过自定时间点的方式,自定义消费数据位置
*
* 其实本质,核心知识是seek方法
*
* 举一反三:
* 1,通过时间换算出offset,再通过seek来自定义偏移
* 2,如果你自己维护offset持久化~!!!通过seek完成
*
*/
Map<TopicPartition, Long> tts =new HashMap<>();
//通过consumer取回自己分配的分区 as
Set<TopicPartition> as = consumer.assignment();
while(as.size()==0){
consumer.poll(Duration.ofMillis(100));
as = consumer.assignment();
}
//自己填充一个hashmap,为每个分区设置对应的时间戳
for (TopicPartition partition : as) {
// tts.put(partition,System.currentTimeMillis()-1*1000);
tts.put(partition,1610629127300L); //这里是要指定的时间戳
}
//通过consumer的api,取回timeindex的数据 用时间戳换算出真正的offset
Map<TopicPartition, OffsetAndTimestamp> offtime = consumer.offsetsForTimes(tts);
for (TopicPartition partition : as) {
//通过取回的offset数据,通过consumer的seek方法,修正自己的消费偏移
OffsetAndTimestamp offsetAndTimestamp = offtime.get(partition);
long offset = offsetAndTimestamp.offset();
System.out.println(offset);
consumer.seek(partition,offset);
}














 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









