







通常Hadoop在做join策略的时候会有两种方式map-side join(也叫replication join)和reduce-side join(也叫repartition join或者common join)
1. reduce side join
利用了mapreduce框架的sort-merge机制来使得相同key的数据聚合在一起,在map阶段会分别读取输入dataset,然后根据join key来分发每条记录(其他值包装在value中),在reduce阶段读取所有同一个join key对应的所有记录后,就可以做笛卡尔积,然后将结果再emit出去。
2. map side join
如果一部分输入dataset size比较小的话,可以将这部分数据replicate到所有的map端(利用DistributedCache拷贝到各个map host上),在map task执行的时候,会先将这部分数据(小表)读入memory中,每次在map函数遍历大表的时候,会查找memory中对应相同join key的记录集,然后做join。
Hive执行map side join的策略
Hive在Compile阶段的时候对每一个common join会生成一个conditional task,并且对于每一个join table,会假设这个table是大表,生成一个mapjoin task,然后把这些mapjoin tasks装进conditional task(List<Task<? extends Serializable>> resTasks),同时会映射大表的alias和对应的mapjoin task。在runtime运行时,resolver会读取每个table alias对应的input file size,如果小表的file size比设定的threshold要低 (hive.mapjoin.smalltable.filesize,默认值为25M),那么就会执行converted mapjoin task。对于每一个mapjoin task同时会设置一个backup task,就是先前的common join task,一旦mapjoin task执行失败了,则会启用backup task
流程图:
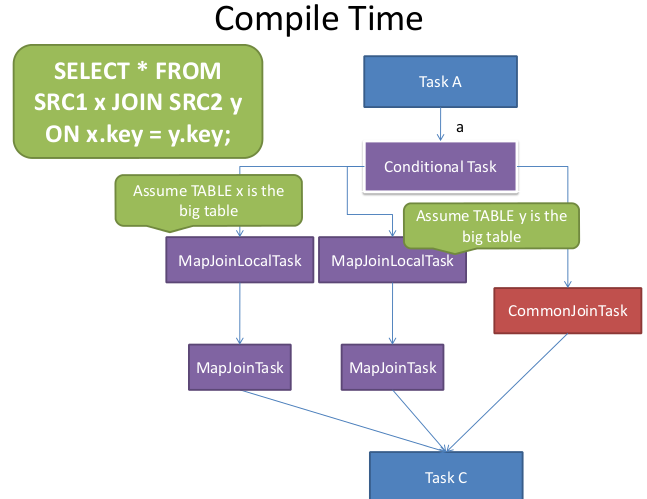
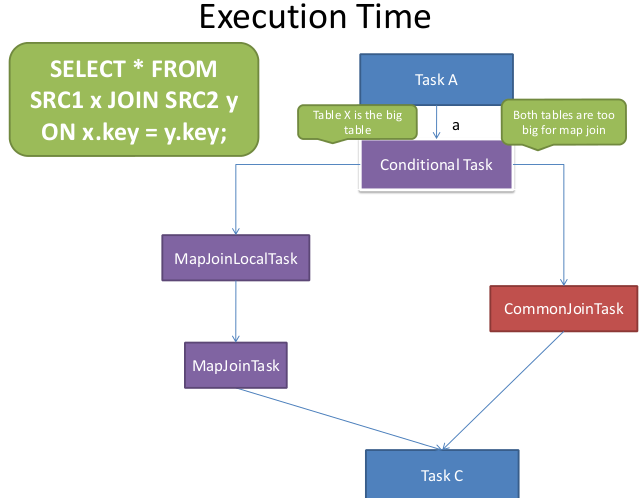
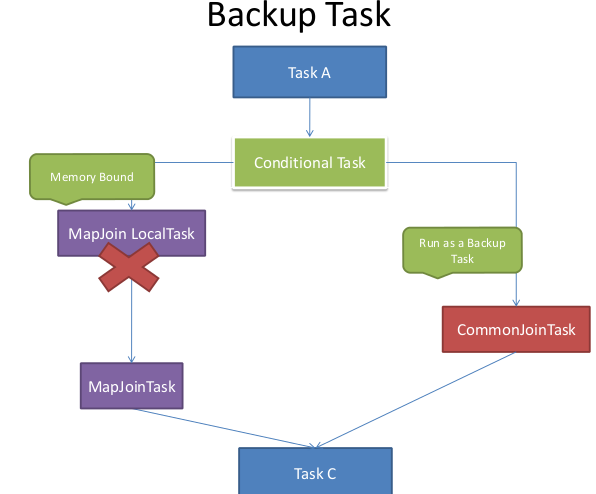
原文链接:http://blog.csdn.net/lalaguozhe/article/details/9082921















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









