






数新网络官网已全新上线,欢迎点击访问
www.datacyber.com 数新网络_让每个人享受数据的价值
1. 什么是Flume?
Flume是什么?我们从flume的图标就能看出,它是一个水道。Flume的图标下面是水,上面是木头。当我们在山上的伐木场(source)有很多木头需要运输到山下的时候,如果一棵一棵的去搬的话,太费体力了,刚好山上有条小溪(channel),而它恰好又是通往山下的,我们就可以把木头放到小溪里顺流而下,再在山下挖一个水槽(sink),让木头流向这个水槽,我们需要用的时候就可以在这个水槽里面去取。而flume就是集(source+channel+sink)的一个日志数据采集工具。

图片来源于官网
2. Flume概述
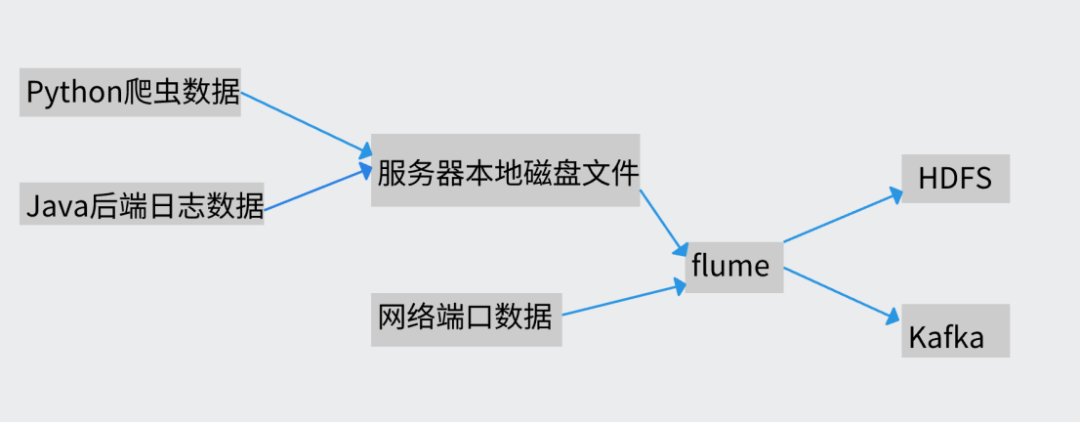
图1-1
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中一般的采集需求,通过对flume的简单配置即可实现,Flume针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
2 Flume版本
1.Flume og结构
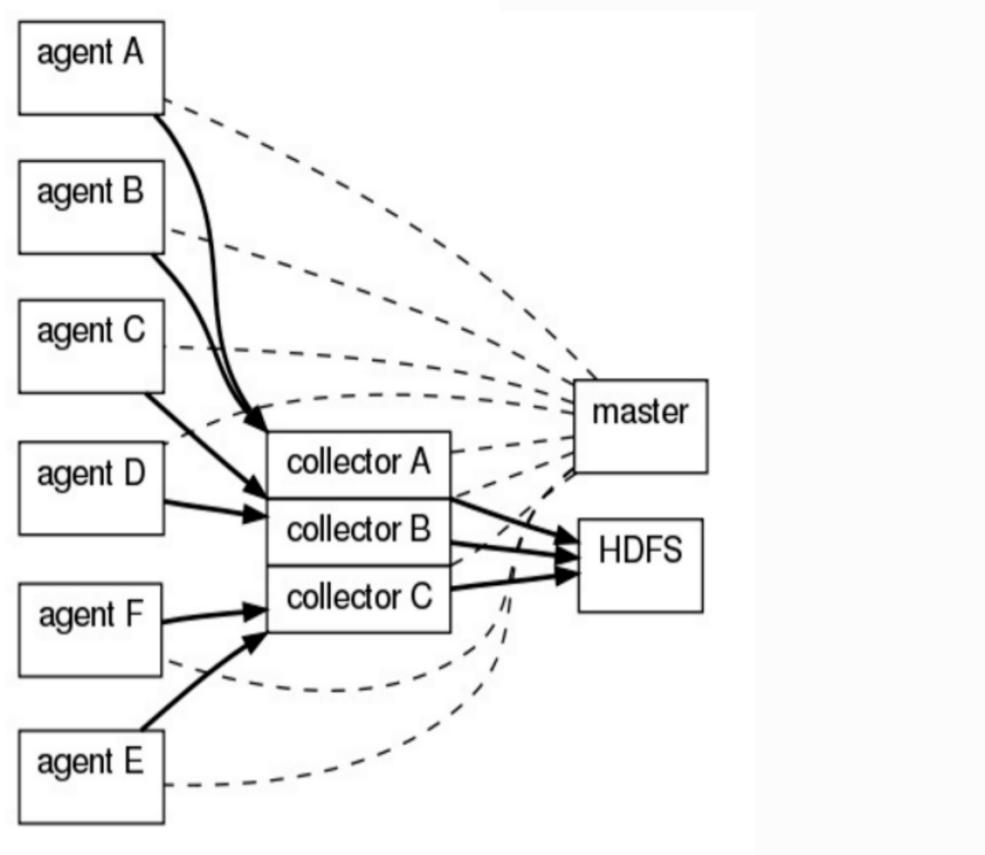
图2-1
Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera,随着 Flume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来。当前我们使用的一般是flume ng (apache Flume)。
Flume OG由三个角色节点组成:agent,collector,master组成。agent负责从数据源收集数据,将数据集中到collector,然后汇入数据库,主节点master负责管理,在OG版本使用中,使用稳定性依赖于zookeeper。
2.Flume ng基础结构
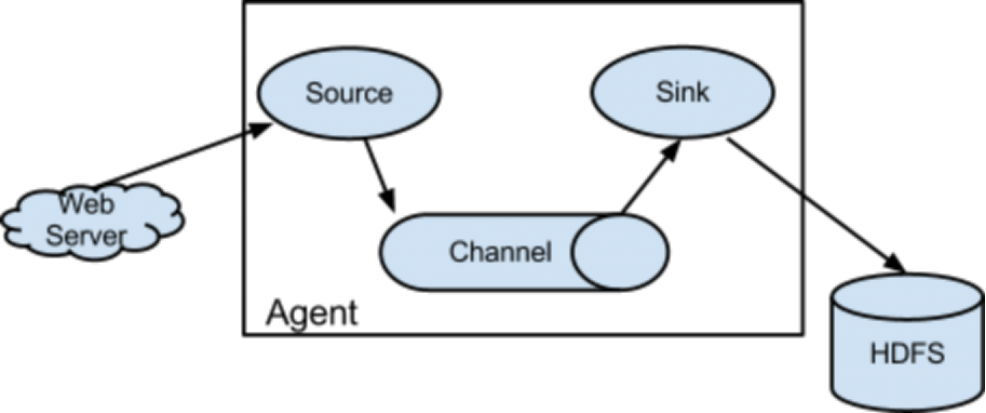
图2-2
Flume NG 只有一种角色的节点:代理节点(agent),没有 collector、master 节点。这是核心组件最核心的变化。去除了 physical nodes、logical nodes 的概念和相关内容。
agent 节点的组成也发生了变化。NG agent 由 source、sink、channel 组成。
3 Flume事物及流程
1. Flume事务
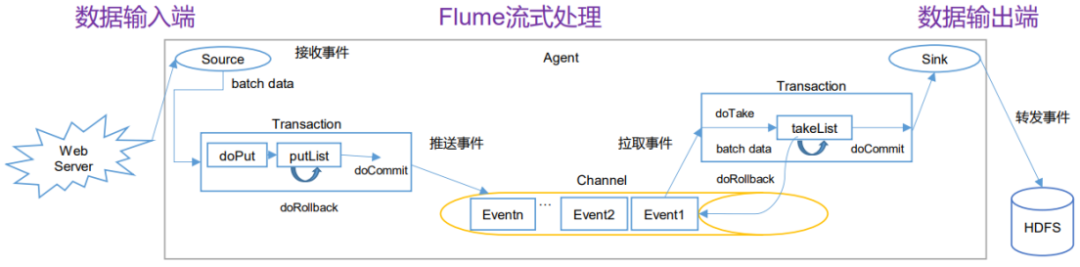
图3-1
-
Put事务流程
将数据先写入 putlist 临时缓冲区,检查channel内存是否足够合并(如果后续没有数据了,将在设定的时间内合并),channel内存不足,将回滚数据。
-
Take事务流程
将数据推入临时缓冲区takelist,并发送到HDFS,如果数据全部发送成功,则清除临时缓冲区 takelist,数据发送过程中如果出现异常,rollback 将临时缓冲区 takelist 中的数据归还给 channel 内存队列。
2.Flume agent 流程
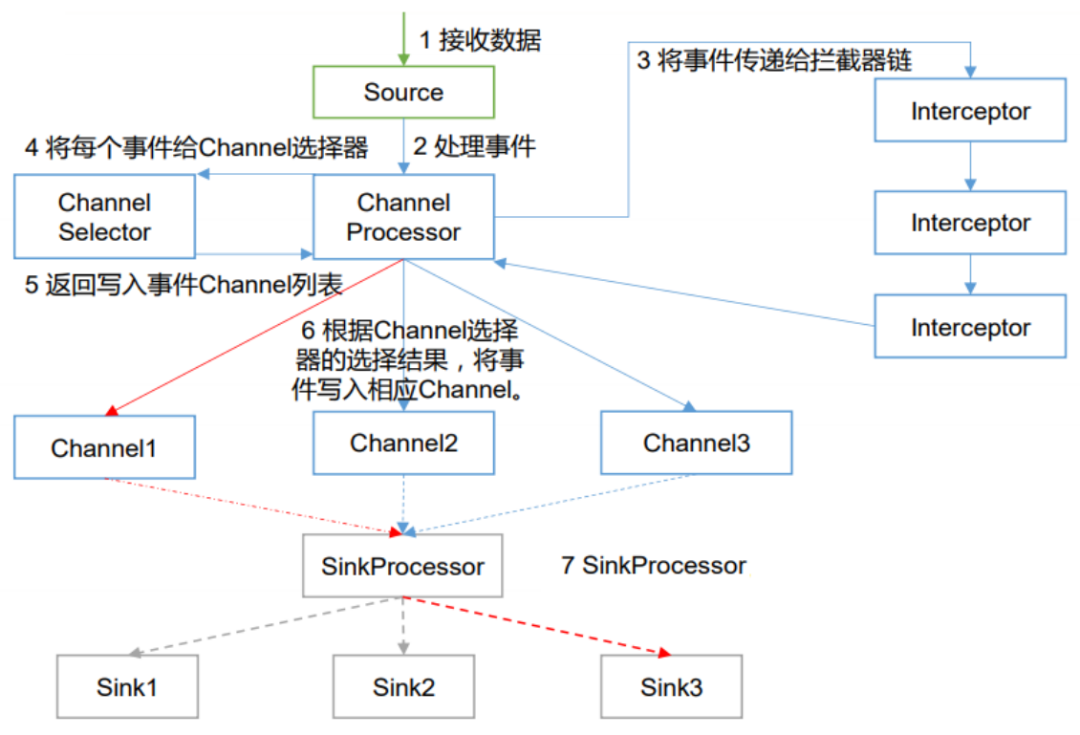
图3-2
在Source接收到数据后,会把数据包装成Event,并把数据交给channel,由ChannelProcessor决定怎么交,交给谁。在ChannelProcessor流程中首先会将数据交给拦截器链,可进行数据清理,处理脏数据。拦截器尽量选择简单的逻辑,不然会影响流式处理链条,整个流程都会变慢。后将数据交给Channel选择器ChannelSelector,ChannelSelector处理完将数据返还给ChannelProcessor,根据ChannelSelector的选择结果将数据写入对应的channel。
每个channel都有一个独立的SinkProcessor,sink不是直接拉取数据的,sink是由SinkProcessor决定怎么拉取数据的,默认的SinkProcessor一共有三种,分别是:
-
DefaultSinkProcessor:接收单一的Sink,不强制用户为Sink创建Processor;
-
LoadBalancingSinkProcessor:负载均衡片处理器提供在多个Sink之间负载平衡的能力;
-
FailoverSinkProcessor:通过配置维护了一个优先级列表。保证每一个有效的事件都会被处理(故障转移)。
4 学习总结
Flume主要是用来数据采集,将用户的信息以及行为日志保存到HDFS集群中或者本地文件夹中,相当于一个搬运工,flume的单位是agent。学习flume的重点是需要掌握source和channel之间的事务、sink和channel之间的事务流程原理,以及source和channel之间的复制和多路复用的原理、sink和channel之间的负载均衡、故障转移等原理。
一 END 一
















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









