







数新网络官网已全新上线,欢迎点击访问
www.datacyber.com 数新网络_让每个人享受数据的价值
01 数据迁移场景
-
不同平台之间的迁移,比如apache hadoop到cdh数据迁移;
-
集群数据集体迁移,由于业务发展迅速,当前集群可能有比较大的业务压力,需要把数据整体迁移到更大的集群;
-
数据的准实时同步,为了保证数据的双备份可用,需要定期的同步数据,保证两个集群的数据周期内基本完全一致。这样做的好处是如果某一天A集群宕机了,可以把线上使用的集群直接切到B集群而不会造成影响。
02 hadoop集群间数据命令
hadoop distcphdfs://master1:8020/foo/barhdfs://master2:8020/bar/foo
03 什么是distcp?是如何实现的?
Distcp是hadoop内部自带的一个程序,用于hdfs之间的数据拷贝。Distcp是作为一个 MapReduce作业来实现的,该复制作业是通过集群中并行运行的 map来完成。每个文件通过一个map进行复制,并且 distcp试图为每一个 map 分配大致相等的数据来执行,即把文件划分为大致相等的块。默认情况下,每个集群节点最多分配20个map任务。
04 distcp常用的参数

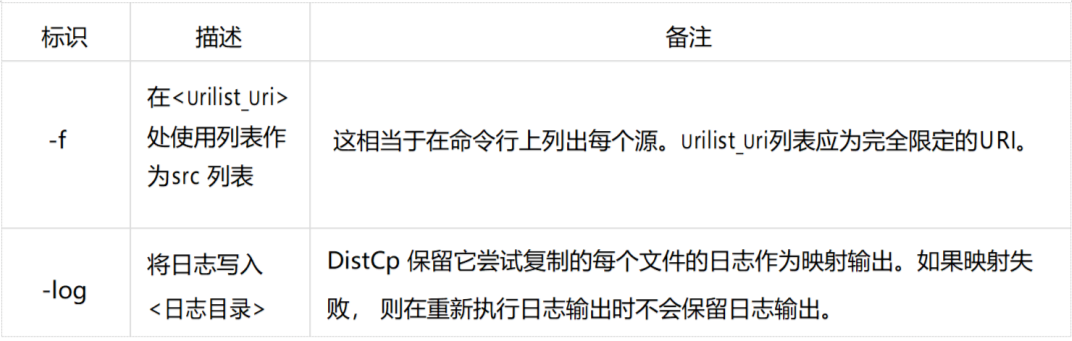
05 Distcp优势特性
-
带宽限流:Distcp是支持带宽限流的,使用者可以通过命令参数bandwidth来为程序进行限流,原理类似于HDFS中数据Balance程序的限流。
-
增量数据同步:对于增量数据同步的需求,在distcp中也得到了很好的实现。通过update,append和diff 2个参数能很好地解决。官方的参数使用说明:Update: Update target, copying only missing files or directories;
Append: Reuse existing data in target files and append new data to them if possible;
Diff: Use snapshot diff report to identify the difference between source and target.
-
高效的性能:执行的分布式特性高效的MR组件。
06 hive数据迁移
1. hive数据export到hdfs
export table tablename to '/tmp/export/tablename';2. 数据复制
hadoop distcp -D ipc.client.fallback-to-simple-auth-allowed=true-D dfs.checksum.combine.mode=COMPOSITE_CRChdfs://master1:8020/tmp/export/tablenamehdfs://master2:8020/tmp/export/tablename
3. 新集群创建表并且导入数据
在源hive show create table tbName显示建表语句,用语句在目标hive建表,然后导入数据:LODA DATA [LOCAL] INPATH ‘filepath’;
4. 验证数据是否相同
select count(*) from 'tablename'本期分享就到这里,欢迎关注我们了解更多精彩内容~
















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









